AI/추천 시스템
RNN 계열의 GRU 모델을 활용한 GRU4Rec
- -
RNN 계열의 모델
RNN 계열 모델의 자세한 설명은 이전에 작성한 글을 참고하면 된다.
https://glanceyes.tistory.com/entry/Deep-Learning-RNNRecurrent-Neural-Network?category=1050635
순차 데이터와 RNN(Recurrent Neural Network) 계열의 모델
Sequential Model Sequential Data [출처] https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras 일상적으로 접하는 데이터는 대부분 sequential data이다. (예: 음성, 비디오 등) Naive Sequence Model $$ p(x_t
glanceyes.com
RNN(Recurrent Neural Network)
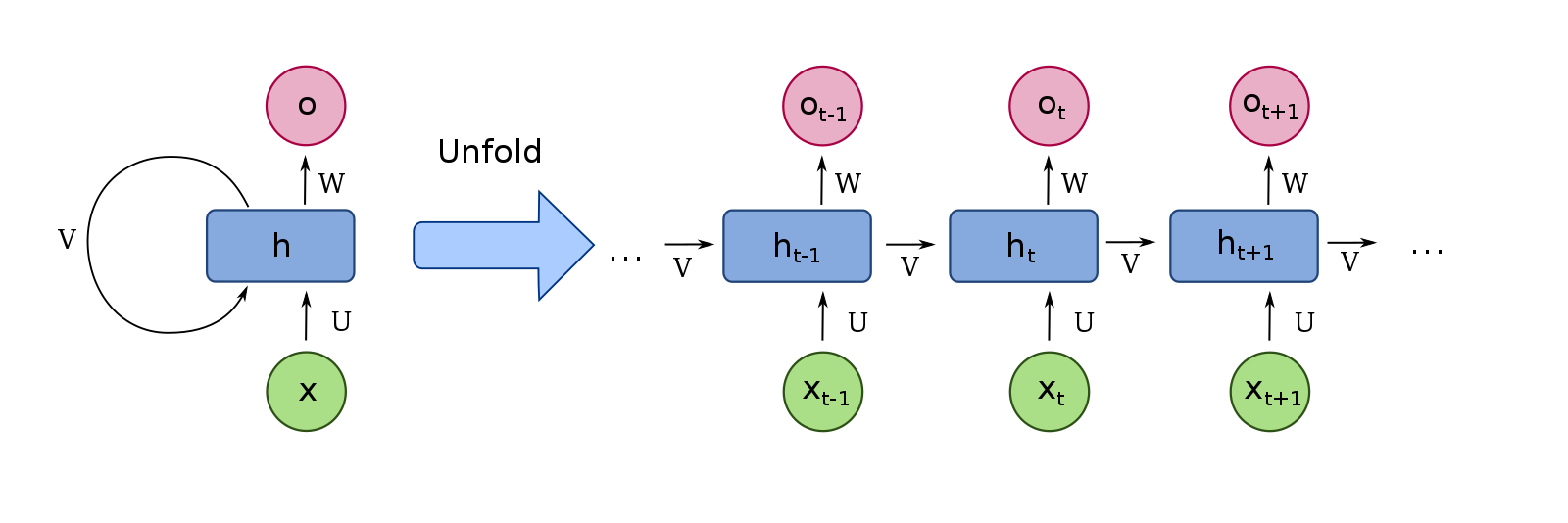
[출처] https://commons.wikimedia.org/wiki/File:Recurrent_neural_network_unfold.svg, fdeloche
순차 데이터의 처리와 이해에 좋은 성능을 보이는 신경망 구조이다.
현재의 상태가 그 다음 상태에 영향을 미치도록 loop 구조를 가진다.
LSTM(Long-Short Tem Memory)
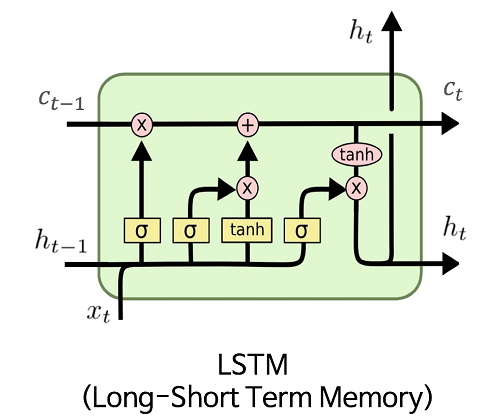
[출처] https://commons.wikimedia.org/wiki/File:LSTM.png, MingxianLin
시퀀스가 길어질수록 학습 능력이 현저하게 저하되는 RNN의 한계를 극복하기 위해 고안된 모델이다.
장기 의존성 해결을 위해 Cell State라는 구조를 가진다.
LSTM의 Gate
Forget Gate
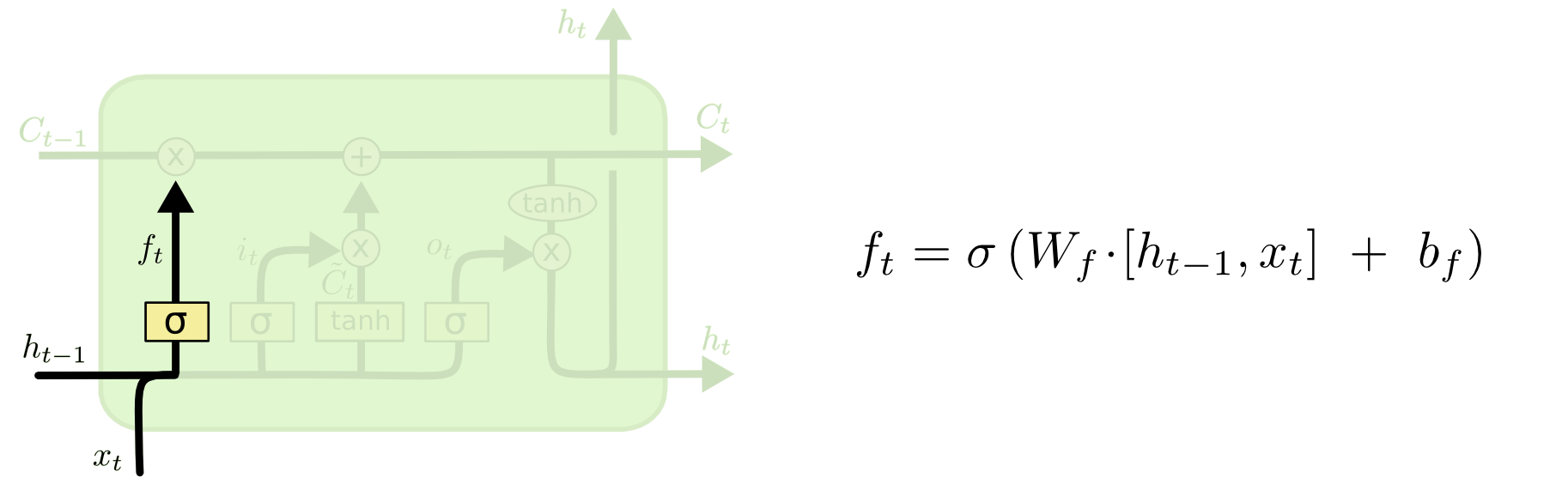
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
이전의 output인
Input Gate
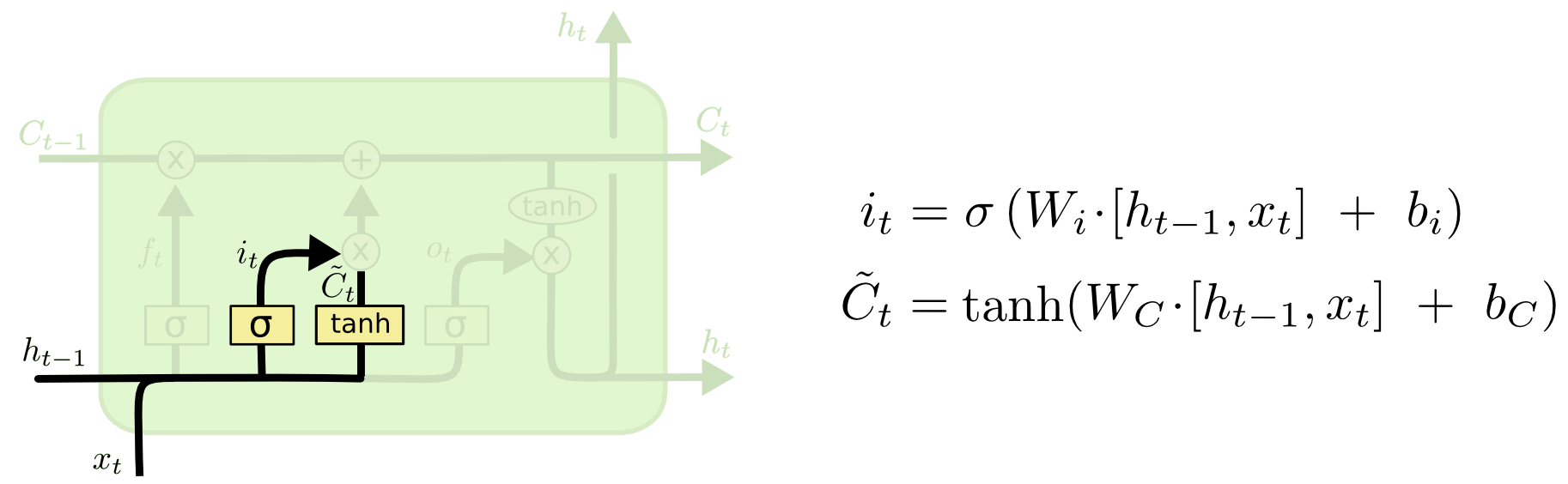
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
이전의 output인
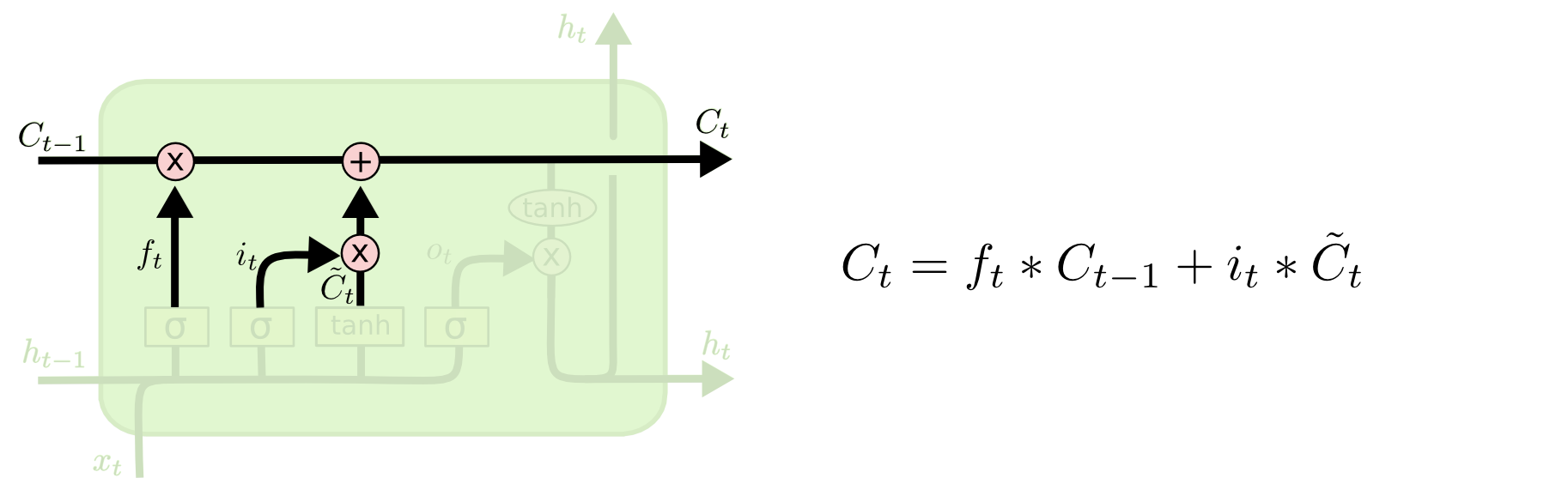
Cell State Update
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
이전의 cell state인
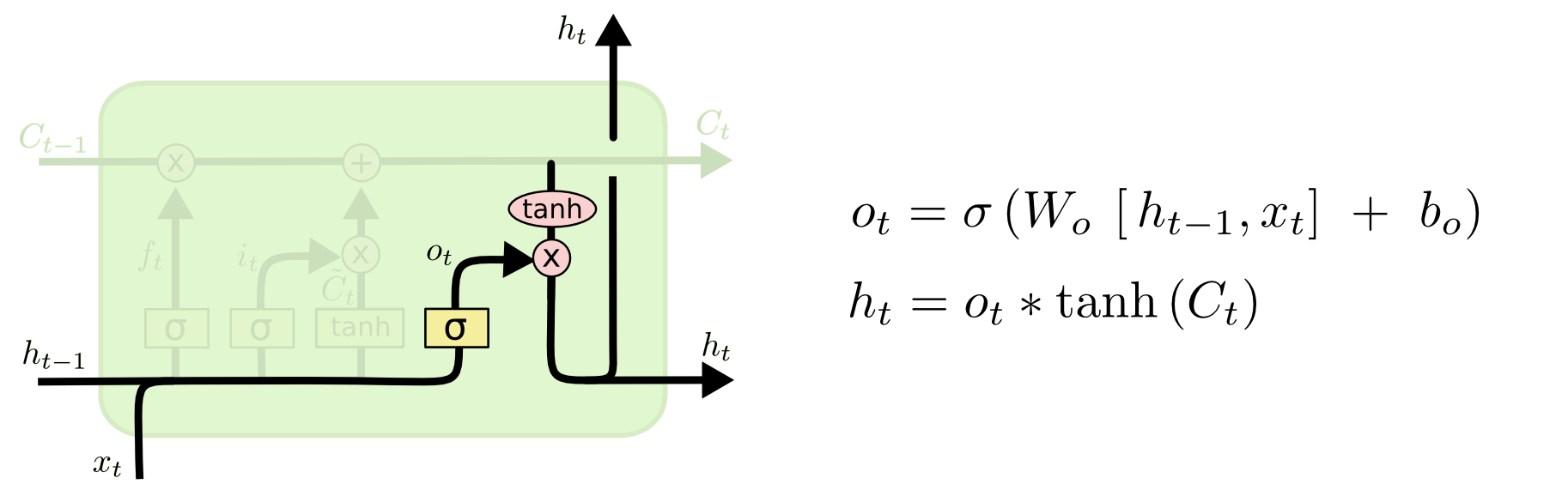
Output Gate
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
이전의 output인
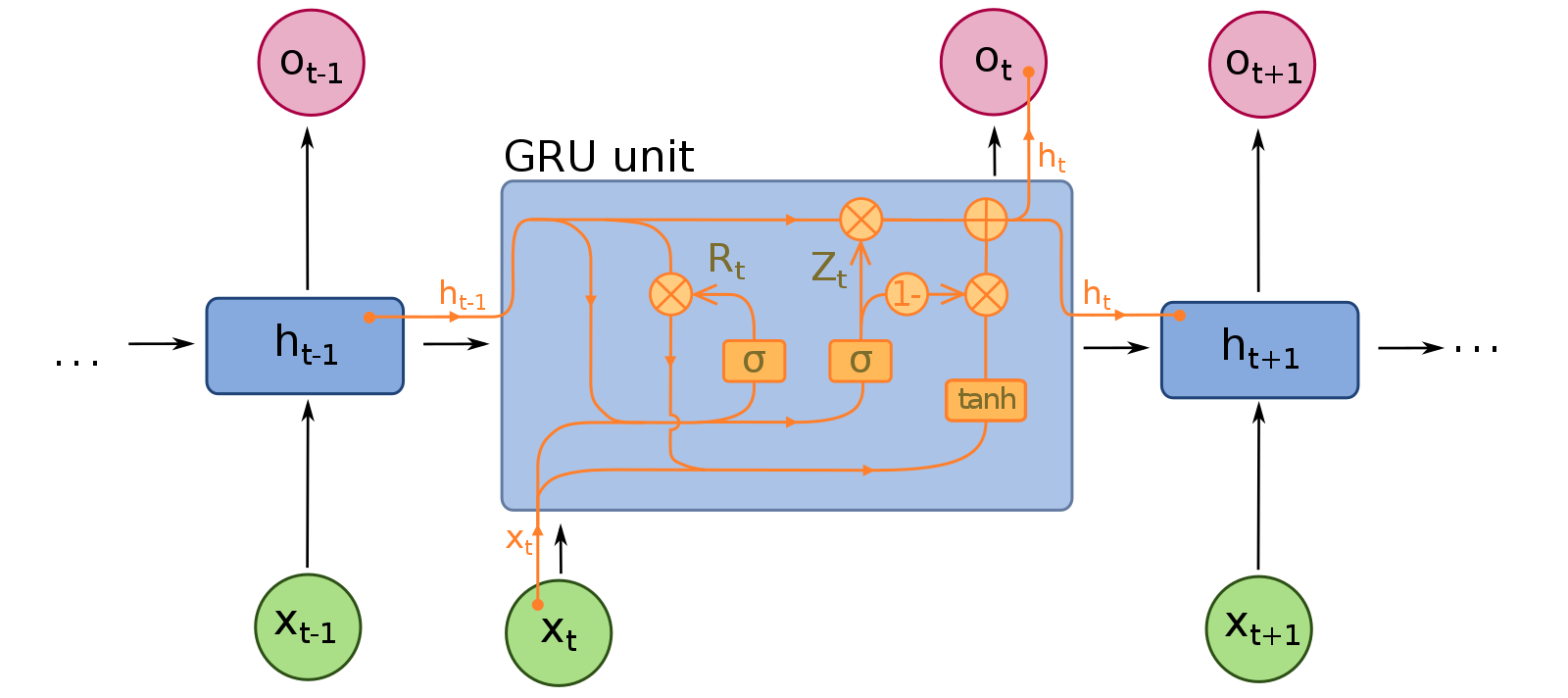
GRU(Gated Recurrent Unit)
[출처] https://commons.wikimedia.org/wiki/File:Gated_Recurrent_Unit.svg, fdeloche
LSTM의 변형 중 하나로, Cell State와 Output Gate가 따로 없어서 파라미터와 연산량이 더 적은 모델이다.
Reset Gate와 Update Gate 두 가지 Gate로 구성된다.
LSTM과 명확한 성능 차이가 없으면서 훨씬 가벼운 모델이다.
RNN과 추천 시스템
Session
유저가 서비스를 이용하는 동안의 행동을 기록한 데이터이다.
Session based Recommender System
고객의 선호는 고정된 것이 아니므로 '지금' 고객이 좋아하는 것이 무엇인지 알아야 할 필요가 있다.
GRU4Rec
Session이라는 시퀀스를 GRU 레이어에 입력하여 바로 다음에 올 확률이 가장 높은 아이템을 추천하는 것이다.
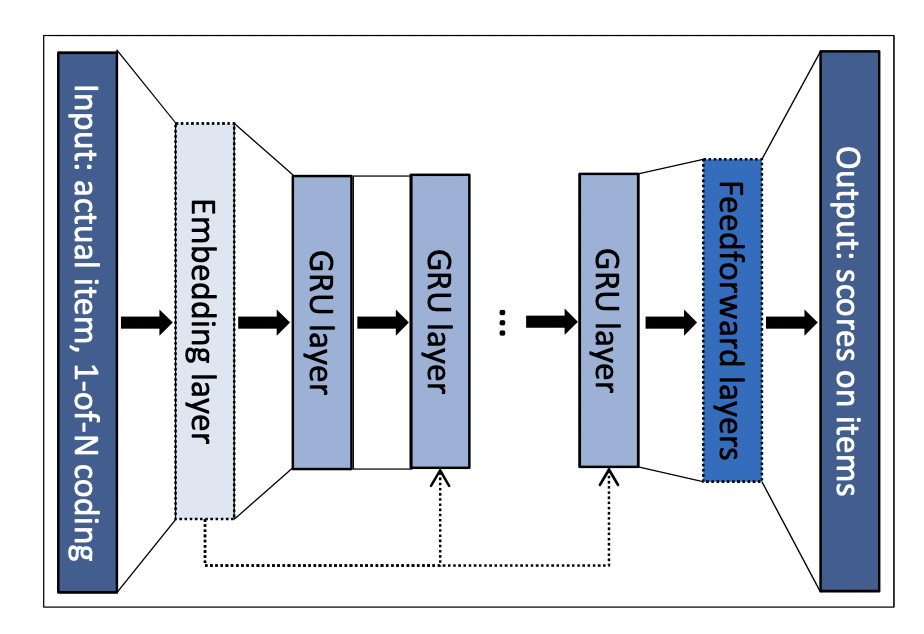
GRU4Rec 모델 구조
[출처] https://arxiv.org/pdf/1511.06939.pdf, SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS
입력
One-hot encoding된 session이다.
GRU 레이어
시퀀스 상 모든 아이템들에 대한 맥락적인 관계를 학습한다.
출력
다음에 추천될 아이템에 대한 선호도 스코어를 출력한다.
GRU4Rec에서 사용된 학습 테크닉
Session Parallel Mini Batches
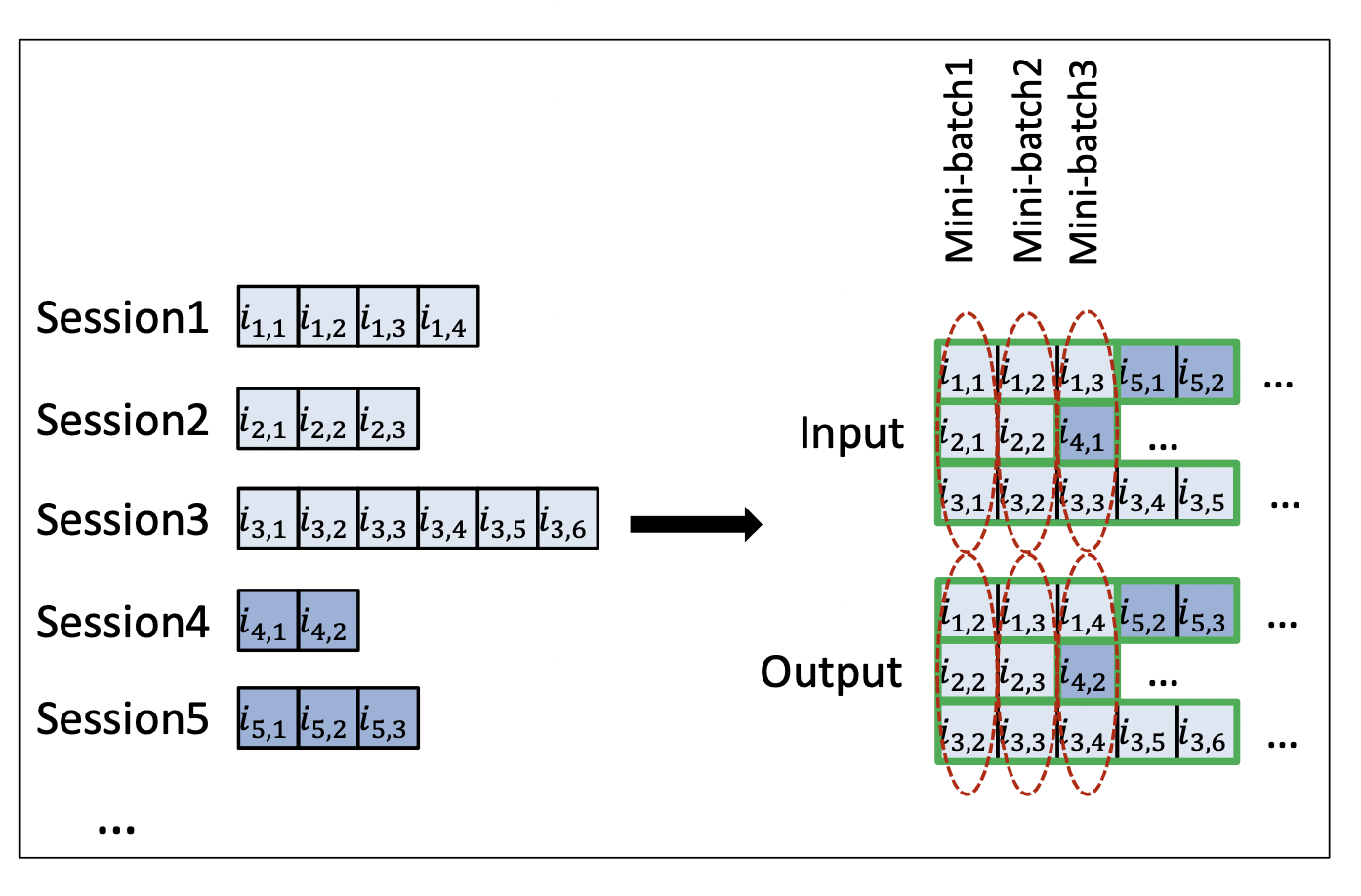
[출처] https://arxiv.org/pdf/1511.06939.pdf, SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS
대부분의 세션은 매우 짧지만, 길이가 긴 것도 존재할 수 있다.
길이가 짧은 세션들이 단독 사용되어 idle하지 않도록 세션을 병렬적으로 구성하여 미니 배치를 학습시킨다.
배치를 그대로 사용하는 것이 아니라 길이가 짧은 세션들은 다른 세션 뒤에 붙여서 미니 배치를 만들어 학습한다.
학습 데이터 sampling
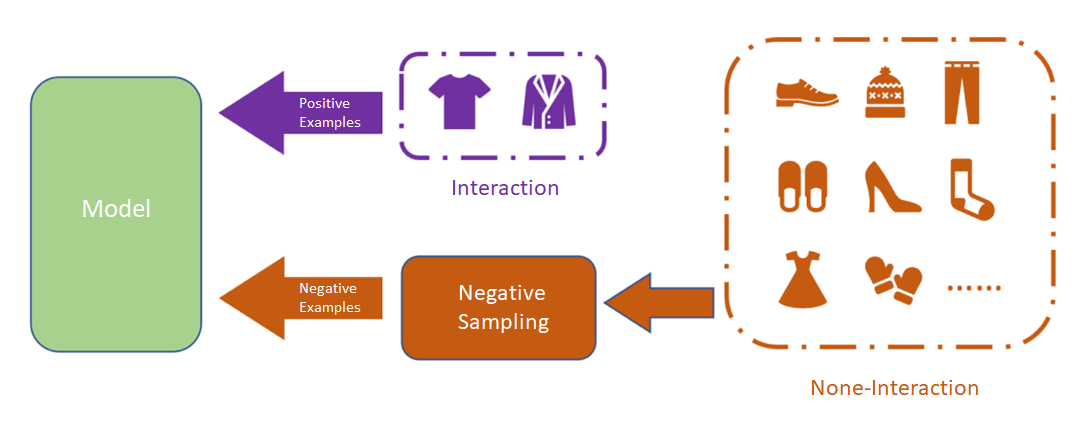
[출처] https://medium.com/mlearning-ai/overview-negative-sampling-on-recommendation-systems-230a051c6cd7
현실에서는 아이템의 수가 많으므로 모든 후보 아이템의 확률을 계산하기 어렵다.
따라서 아이템을 negative sampling하여 subset만으로 loss를 계산해야 한다.
사용자가 상호작용 하지 않은 아이템은 존재 자체를 몰랐거나 관심이 없는 것일 수 있다.
만약 아이템의 인기가 높은데도 상호작용이 없었다면 사용자가 관심이 없는 아이템이라고 가정한다.
그래서 인기에 기반하여 negative sample을 하며, 인기도가 높은 것을 위주로 negative sampling하는 것이다.
GRU4Rec의 특징
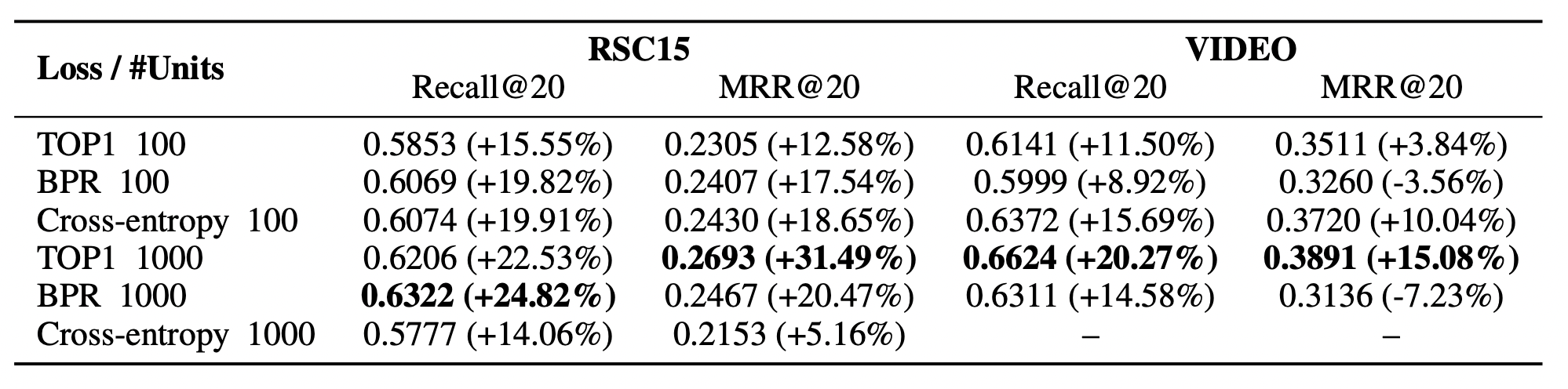
[출처] https://arxiv.org/pdf/1511.06939.pdf, SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS
RSC15와 VIDEO Dataset에서 가장 좋은 성능의 베이스라인인 item-KNN 모델 대비 약 20% 높은 추천 성능을 보인다고 한다.
특히, GRU 레이어의 hidden unit이 클 때 더 좋은 성능을 내는 것으로 알려져 있다.
출처
1. 네이버 부스트캠프 AI Tech 추천시스템 Stage 2 기초 강의
Contents
소중한 공감 감사합니다.