AI/NLP
BERT를 경량화하여 모델의 크기를 줄인 ALBERT의 특징
- -
ALBERT
GPT-3와 같은 pre-training model들은 거대한 파라미터의 수를 지니는 형태로 발전해 왔지만, 이는 더 좋은 성능의 GPU와 대용량의 메모리를 필요로 하고 방대한 데이터셋을 학습시키는 데 긴 시간을 소모하게 된다.
ALBERT는 'A Lite BERT'라는 의미를 지니는 경량화된 BERT이며, 기존의 BERT가 지니고 있던 모델의 비대함이라는 한계를 극복하면서 동시에 성능의 큰 하락은 피하고자 한 모델이다.
즉, 모델의 크기가 비대해진다고 해서 반드시 성능이 향상된다는 사실에 반하는 결과를 제시한 모델이다.
더 나아가 새로운 변형된 형태의 문장 level에서의 self-supervised learning의 pre-training task인 sentence order prediction을 제시했다.
ALBERT의 특징
Factorized Embedding Parameterization
BERT와 같은 transformer 기반의 기존 모델들은 self-attention block을 점점 쌓아 나가면서 skip connection을 계속 유지하므로 각 block에서 사용하는 hidden state 벡터의 차원인
여기서
그런데 self-attention block을 쌓아 나가면서 레이어가 깊어지면 깊어질수록 low-level보다는 주로 high-level에서 의미론적으로 유의미한 정보를 추출해 나갈 수 있다.
이러한 관점에서 첫 번째로 주어지는 임베딩 레이어처럼 앞쪽에서 주어지는 self-attention block의 입력 벡터에서는 입력 문장 전체의 contextual meaning을 고려하지 않고 단어별로 독립적인(token-independent) 정보를 더 많이 갖고 있는 반면에, 레이어가 깊어지면 깊어질수록 block의 입력 벡터 또는 hidden state 벡터는 문장 전체에 관한 정보를 지닐 수 있어야 한다.
그래서 앞쪽에서의 임베딩 벡터는 뒤쪽보다 상대적으로 더 적은 정보만을 필요로 하므로 좀 더 작은 차원을 지니는 벡터의 형태를 지니어도 된다.
이를 바탕으로 ALBERT에서는 임베딩 레이어의 차원을 줄이는 방법을 제시했는데, 문장에서 각 단어(token)의 임베딩 벡터를 만들 때 기존의 임베딩 차원 수보다 더 적은 차원 수를 지니도록 하고, 대신에 단어의 원래 임베딩 벡터에 관해 skip connection을 수행이 가능하도록 self-attention block의 입력부에 선형 변환 layer를 하나 더 추가하여 앞서 차원 축소를 시킨 단어별 임베딩을 원래 임베딩 벡터로 바꿔줄 수 있게끔 한다.
각 단어의 임베딩 벡터이자 hidden state vector가 원래 4차원의 벡터를 지닌다면, ALBERT에서는 초반부의 각 block에 주어지는 단어별 2차원 벡터를 입력부의 선형 변환 layer를 통해 선형변환하여 4차원의 벡터를 지니도록 근사시키는 low-rank matrix factorization을 수행하는 것이다.
Vocabulary size만큼의 단어 개수를
대개 pre-trained model은 방대한 단어를 학습하므로
그래서
Cross-layer Parameter Sharing
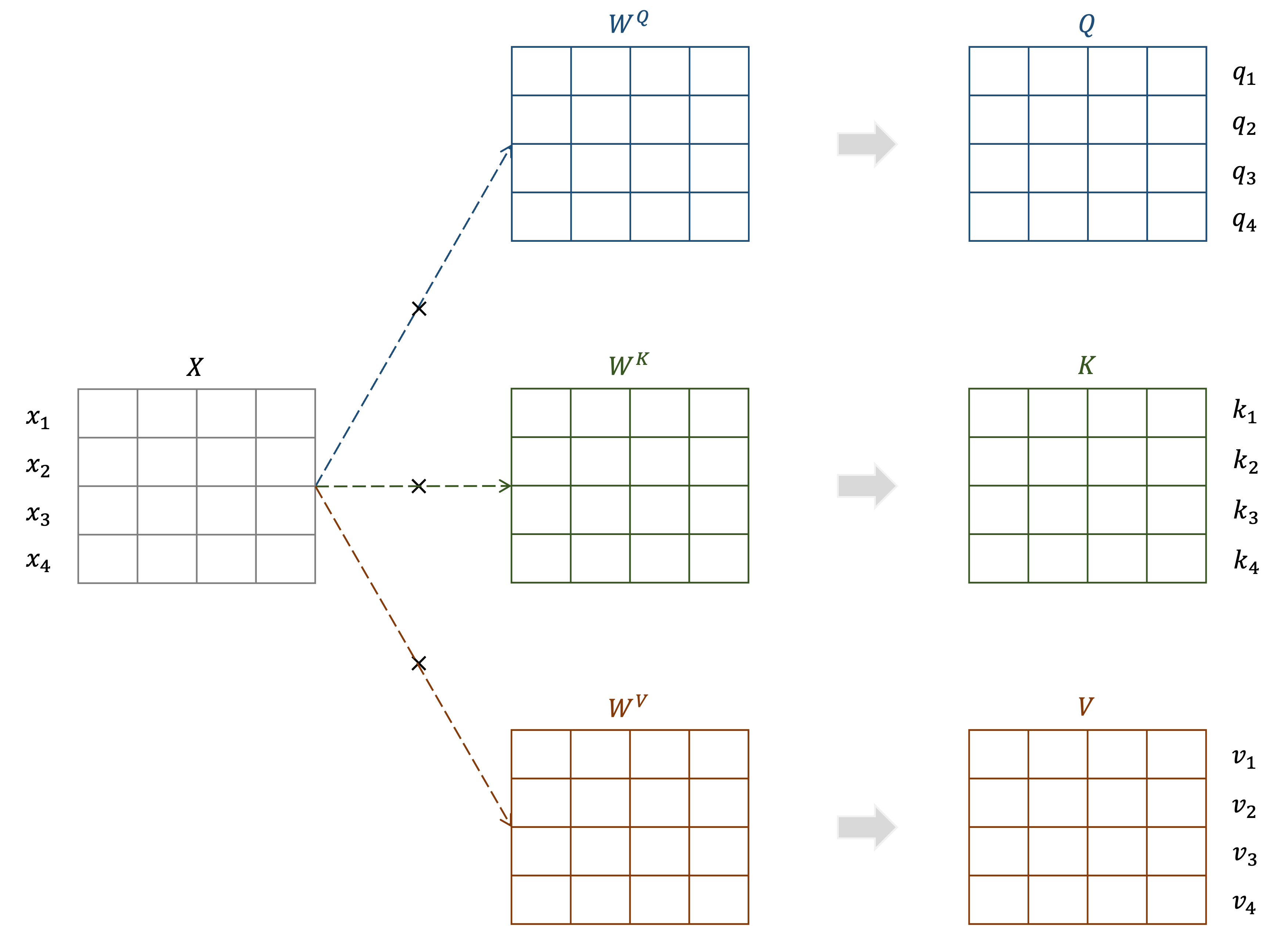
Self-attention block을 살펴보면 block의 입력으로 주어지는 임베딩 벡터에 관해 query, key, value vector로 선형 변환을 해주는 행렬인
또한 multi-head attention에서 query, key vector로 attention score를 구하고, 이를 가중치로 사용하여 value vector에 관해 가중 평균을 구한 output vector 행렬인
이처럼 기존의 self-attention block에서는 위의 파라미터가 서로 독립적으로 학습을 진행하는데, ALBERT에서는 전체 모델의 학습 파라미터 수를 줄이고자 조금 다른 방식을 사용했다.
ALBERT에서는 겹층으로 쌓은 서로 다른 self-attention block에서 사용하는
[출처] https://arxiv.org/pdf/1909.11942.pdf, ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
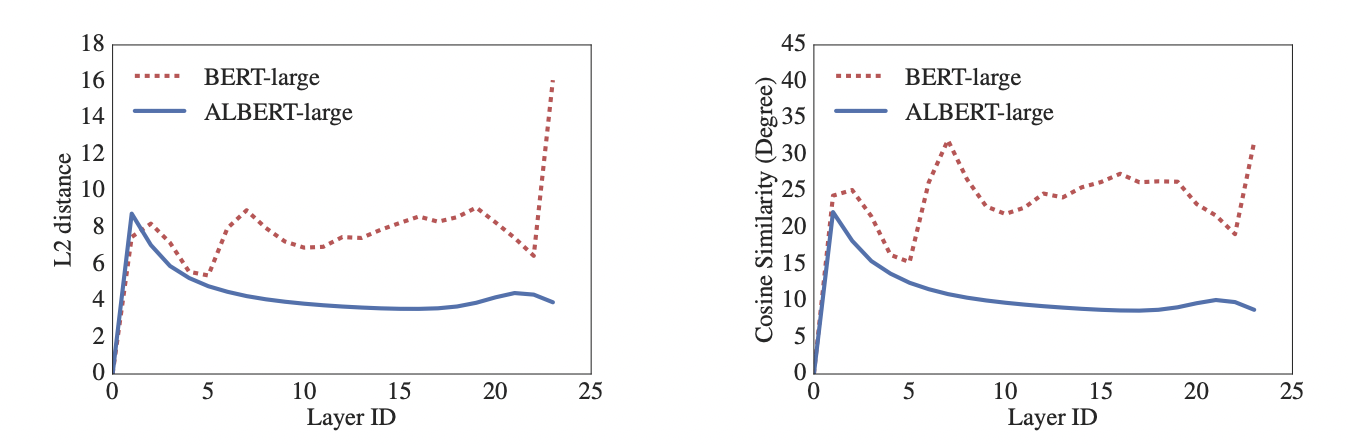
위의 그림은 각각 BERT와 ALBERT에서 input과 output embedding의 L2 distance와 cosine 유사도 결과를 표현한 그래프이다.
ALBERT에서 파라미터를 공유했을 때 레이어마다 transition이 좀 더 부드러워서 결과적으로 네트워크의 파라미터가 안정화되는 효과를 낳는다고 설명하고 있다.
Shared-FFN
Self-attention block의 output layer에서의
Shared-attention
모든 self-attention block마다
All-shared
모든 self-attention block마다
[출처] https://arxiv.org/pdf/1909.11942.pdf, ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
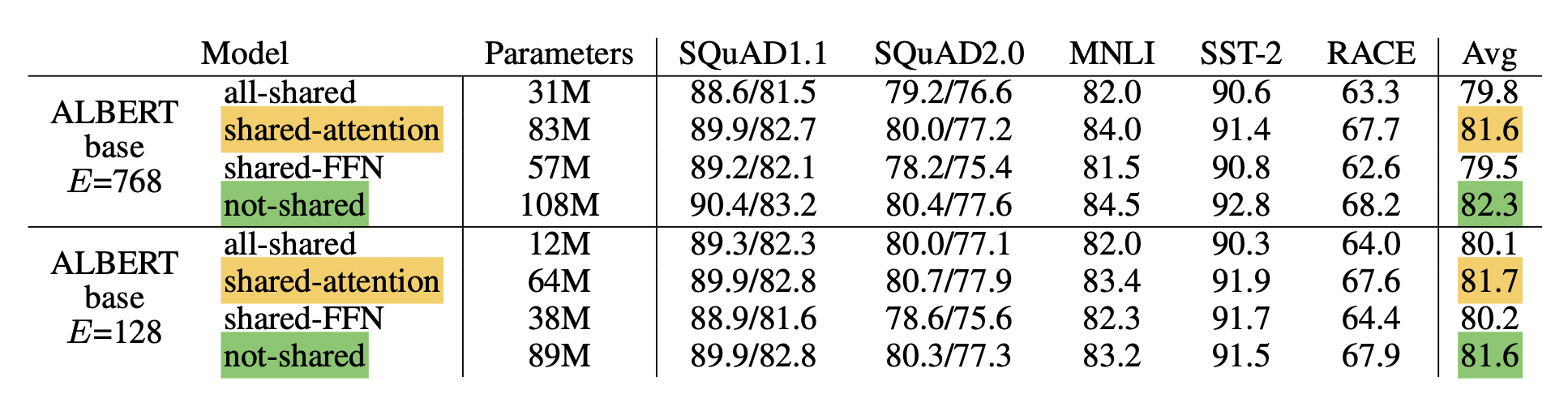
파라미터를 레이어마다 공유했을 때의 결과가 공유하지 않았을 때마다 크게 떨어지지 않는 것을 볼 수 있으며, 특히 모든 self-attention block마다 파라미터를 공유하는 shared-attention에서는 아예 파라미터를 공유하지 않았을 때마다 더 좋은 성능을 보인다는 것을 확인할 수 있다
Sentence Order Prediction
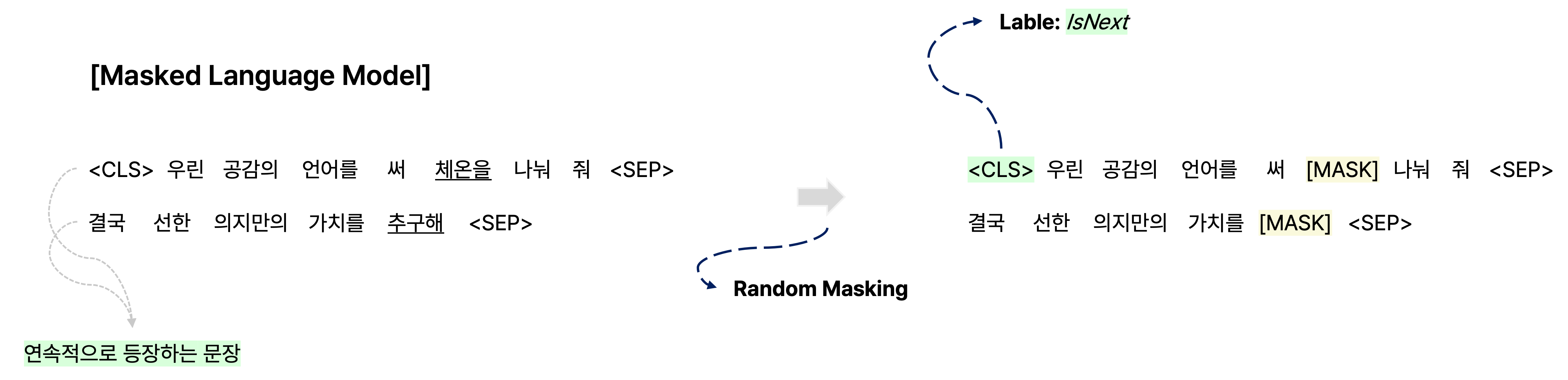
기존의 BERT에서 사용되던 pre-training task에는 일부 단어를 masking해서 해당 부분의 단어를 예측하여 생성하는 masked-language model과 <CLS> token을 사용하여 같은 document에서 연속으로 오는 문장 관계인지를 파악하여 다음에 올 문장이 맞는지 예측하는 next sentence prediction이 있다.
그러나 여러 후속 연구에 의해 next sentence prediction은 BERT에서 그다지 큰 효용성이 없다는 주장이 제기되었으며, 여러 실험에 의해 굳이 next sentence prediction을 사용하지 않고도 masked-language model만 사용하는 것만으로도 확연한 성능 하락이 보이지 않는다는 게 관찰되었다.
그래서 ALBERT에서는 next sentence prediction을 좀 더 유의미한 task로 바꿔서 두 문장의 쌍이 주어질 때 기존 document에서의 순서처럼 주어지면 연속된 문장으로, 그렇지 않고 순서가 바뀌어 있으면 연속되지 않은 문장으로 학습하게끔 한다.
하지만 기존 BERT의 next sentence prediction처럼 임의로 서로 다른 문서에서 추출된 두 문장을 concatenate 되었을 때는 두 문장의 내용이 서로 겹칠 가능성이 적으므로 이에 관한 순서를 학습하는 게 논리적 관계를 학습하는 데 있어서 큰 의미가 없을 수 있다.
또한 같은 document에서 연속되는 두 문장을 뽑아서 학습하는 것은 두 문장에서 자주 등장한 overlap 되는 단어의 빈도를 학습하게 되는 부작용을 낳게 할 수 있다.

ALBERT에서는 동일한 문장에서 연속되는 두 인접 문장을 뽑되, 두 문장의 순서를 바꾼 쌍을 negative sample로 준다.
그래서 단순히 두 문장을 비교했을 때 유사한 단어가 빈번히 등장한다고 해서 해당 문장을 연속한 문장으로 학습하게 되는 현상을 예방하고 좀 더 논리적 관계에 주목하여 학습할 수 있도록 한 것이다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech NLP Track 주재걸 교수님 기초 강의
Contents
소중한 공감 감사합니다.