AI/CV
HoloGAN: Natural 이미지로부터 3D representation에 관해 unsupervised learning 할 수 있는 생성 모델
- -
이제까지의 GAN(Generative Adversarial Model)은 2D 이미지로부터 3D representation을 학습하여 같은 content의 새로운 이미지를 생성하기 위해 학습 시 데이터 각각의 이미지마다 촬영한 각도(pose) 등 부가적인 정보를 레이블링(labelling) 했다. 그러나 HoloGAN은 레이블링을 하지 않고 단순히 2D 이미지 데이터만으로 unsupervised learning을 하여 새로운 이미지를 생성할 수 있는 방법론을 제시했다. 또한 HoloGAN은 이미지를 생성하는 데 있어서 같은 content에 관하여 다른 요소는 그대로 둔 채 오직 하나의 요소만을 조절하여 이미지를 생성할 수 있는 disentangled learning이 가능하다고 한다. 이번 논문 리뷰에서는 GRAF(Gradient Radiance Fields for 3D-Aware Image Synthesis)를 분석하기 전에 앞서 HoloGAN을 분석하고자 하며, 이전에 리뷰했던 동일한 제1 저자가 연구한 RenderNet의 아이디어와 유사한 부분이 있어서 그의 연장선으로 글을 작성하고자 한다.

HoloGAN 소개
HoloGAN이란?
본 논문의 저자는 이미지로부터 3D representation을 unsupervised learning을 통해 학습 가능한 GAN(Generative Adversarial Network)인 HoloGAN을 제안했다. HoloGAN은 3D representation에 관한 명시적인 정보(pose, 3D shape, object를 바라 보는 여러 개의 view, geometry prior 등)를 주지 않은 unlabelled 2D image만을 가지고 end-to-end로 비지도 학습을 수행할 수 있는 GAN 모델이다.
GAN(Generatvie Adversarial Network)이란?
GAN은 임의의 latent space의 분포로부터 뽑은 샘플을 어떤 데이터가 진짜인지 가짜로 생성했는지를 분류하는 분별자(discriminator)를 속일 수 있는 데이터로 mapping 할 수 있도록 학습한다. GAN에 관한 자세한 내용은 이전에 작성했던 아래 글을 참고하면 된다.
https://glanceyes.tistory.com/entry/Deep-Learning-Generative-Model
생성 모델(Generative Model)과 VAE, 그리고 GAN
Generative Model 단순히 무언가를 생성하는 것만으로 국한시킬 수는 없고, 그보다 더 많은 내용을 포함하는 모델이다. Generative Model의 특징 강아지의 이미지가 주어지고, 이를 학습하는 generative model
glanceyes.com
HoloGAN의 핵심
HoloGAN은 레이블링 되지 않은(unlabelled) 2D 이미지로부터 pose와 identity(shape + appearance)를 분리하는 것을 학습할 수 있다. 대다수의 generative model들은 이미지를 생성하는 데 있어서 2D kernel에만 의존하고 3D world에 관해 매우 적은 가정을 만든다. 그래서 이러한 모델들은 강한 3D understanding을 요구하는 task에서 흐릿한 이미지나 artefact를 생성하는 경향이 있다. 대신 HoloGAN은 world의 3D representation을 학습하고, 이러한 representation을 사실적으로 렌더링 할 수 있다. 다른 GAN들과는 달리 HoloGAN은 학습한 3D representation의 rigid-body transformation을 사용하여 생성된 object의 pose를 명백히 조절할 수 있도록 한다.
논문의 저자는 실험을 통해 explicit 3D features는 HoloGAN이 다른 generative model들과 유사하거나 그보다 더 좋은 visual quality로 이미지를 생성할 수 있으면서(visual fidelity를 유지하면서) 3D pose와 identity를 구분할 수 있도록, 더 나아가 identity를 shape와 appearance로 분해할 수 있도록 한다는 것을 보였다.
HoloGAN은 pose 등 이미지에 관한 다른 정보를 주지 않고도 unlabelled 2D 이미지만을 가지고 end-to-end로 학습할 수 있으며, 이러한 점을 미루어 볼 때 HoloGAN은 완전한 unsupervised learning을 통해 자연적인 2D 이미지로부터 3D representation을 학습할 수 있는 최초의 generative model이라고 저자는 말하고 있다.
HoloGAN의 특징
이전의 Generative Model과의 비교
컴퓨터 비전과 컴퓨터 그래픽스 분야에서 3D object와 2D 이미지 간의 관계를 학습하는 건 매우 중요한 주제이다. 컴퓨터 비전에서는 로보틱스, 자율주행, 보안과 같은 다양한 응용 분야가 있고, 컴퓨터 그래픽스에서는 content를 생성하거나 조작하는 데 응용할 수 있는 이점을 가져다 준다. 특히 이는 실제 사진으로 찍은 것 같은 3D scene rendering 뿐만이 아니라 스케치로 그린 듯한 3D 모델링, novel view synthesis, relighting 등 다양한 분야에 응용될 수 있다.
당시 논문 연구 시점에 따르면 generative model(특히 GAN)은 해상도가 높으면서 좋은 visual quality를 보이는 이미지 생성에 있어서 인상적인 결과를 달성했지만, 이러한 모델들은 아직 생성된 이미지의 속성을 직접 조절하지 못해서 응용될 수 있는 분야가 제한되어 있었다고 한다. 또한 당시 conditional GAN 모델들은 학습을 수행할 시 label이 필요한데, labeling을 할 수 없는 환경에서는 학습이 어려워지는 한계가 존재했다. 이처럼 당시 최근 모델들은 pose와 같은 3D 데이터를 label로 부여하여 학습을 수행했으나, 3D ground-truth 데이터는 매우 비싸다는 단점이 존재한다. 그래서 논문의 저자는 레이블링이 되지 않은 2D 이미지로부터 3D representation을 직접 학습할 수 있는 방법을 찾으려고 했다. 그래서 저자는 3D representation을 unsupervised learning으로 학습하기 위한 새로운 모델을 설계했는데, 가장 중요한 점은 3D world에 관한 강한 inductive bias를 deep generative model과 결합시킨 것이다.
컴퓨터 그래픽스에서 voxel과 mesh 같은 기존의 representaton은 3D에서 explicit하고 rigid-body transformation을 통한 조작이 매우 쉽다는 게 특징이다. 그러나 이를 직접 사용하는 것은 메모리 비효율성을 가져오고, 복잡한 object를 어떻게 이산화(discretise)할 것인지 애매해진다. 즉, 기존의 representation을 직접적으로 사용하는 generative model를 만드는 건 당연하지 않다. 고차원의 latent vector 또는 deep feature 등 implicit representation을 generative model에서 사용하면 공간적으로 compact해지고 의미적으로 expressive(표현이 가지게 되는 정보가 풍부)해질 수 있다. 그러나 이러한 feature들은 explicit view manipulation 등 3D transformation을 적용하면 visual artefact를 생성하거나 흐릿하게 만들 수 있어서 적절하지 못하다고 한다.
이전까지의 GAN의 한계
1. pose, light 등 이미지와 관련된 추가적인 정보 필요 → expensive
2. 생성하고자 하는 것에 관한 직접적인 control이 어려움
⇒ HoloGAN: 레이블 필요 없이 각각의 요소에 관한 control도 가능한 unsupervised learning 제안
그래서 저자는 3D object에 관하여 3D에서 explicit 할 뿐만이 아니라 의미적으로도 expressive한 representation을 학습하는 unsupervised 이미지 생성 모델을 제안했으며, 이러한 representation은 레이블링 되지 않은 natural image로부터 직접적으로 학습될 수 있다고 한다. 다른 GAN 모델과는 달리 HoloGAN은 이미지 생성을 위해 3D와 2D feature를 모두 사용하는데, HoloGAN이 어떻게 학습하는지를 네 단계로 요약하면 다음과 같다.
- 3D representation을 학습한다
- Target pose로 transformation 한다.
- 2D feature로 projection 한다.
- Final image 생성을 위해 shading computation으로 렌더링 한다.
과정들을 살펴보면 3번과 4번 과정이 렌더링 과정과 유사하고, 그 앞 과정은 3D representation을 학습하여 임의의 각도로 3D representation을 변환하는 걸 수행하는 걸 눈여겨볼 수 있다. 이 3번과 4번 과정은 RenderNet에서 그 아아디어를 가져와 구현했는데, 이에 관해서는 자세히 후술할 것이다.
HoloGAN의 기술적인 기여
- 이미지로부터 3D object의 pose, shape, appearance처럼 disentangled representation을 학습하는 deep generative model에 3D world에 관한 강한 inductive bias를 결합한 새로운 architecture를 제시했다는 것
- Visual image fidelity(얼마나 이미지가 디테일을 잘 지니면서 정확한 대상을 보여주는지)을 희생하지 않으면서 view manipulation에 관해 처음으로 native support를 하는 unconditional GAN(이미지 자체만 주어지고 이와 관련한 다른 정보는 discriminator에 주어지지 않는 GAN)이라는 것
- 레이블을 사용하지 않고 disentangled representation 학습이 가능한 비지도 학습 접근법
이때 disentangled representation learning은 어떤 하나의 representation을 각 구성 요소별 representation으로 구분하여 학습을 수행하는 것이다. 이를 구현하는 이유는 단지 어떤 하나의 factor만 변화시키고 나머지 요소는 변화 없이 그대로 두는 동일한 대상의 이미지를 생성하는 과정에서 유용하다. 예를 들어, 한 인물의 사진에 관해서 머리의 색만 변화시킨 이미지를 생성하려고 할 때, disentangled representation learning을 통해 representation을 pose, shape, appearance로 분리해서 appearance 요소만을 변화시켜 다른 머리 색을 지닌 동일한 인물의 이미지를 생성할 수 있다. HoloGAN은 pose, shape, appearance를 성공적으로 구분 짓는 걸 학습할 수 있을 뿐만이 아니라 explicit pose control을 제공하고 shape와 appearance editing을 가능하게끔 한다고 강조한다.
HoloGAN의 모델 구조
HoloGAN은 3D world의 3D repesentation을 학습하여 이미지를 생성하고, 이를 사실적으로 렌더링하여 discriminator를 속일 수 있도록 한다. 기본적으로 HoloGAN은 StyleGAN에서의 방법을 차용한 부분이 있어서 StyleGAN에 관한 기본적인 지식이 있으면 이해하는 데 수월한데, StyleGAN에 관한 자세한 내용은 후술할 것이다.
당시 다른 최근의 연구들이 직접 만든(hand-crafted) 미분 가능한 renderer를 사용한 것과 달리, HoloGAN에서는 projection unit을 사용하여 perspective projection과 3D feature rendering을 학습한다. 이 projection unit이라는 새로운 architecture는, 마땅한 hand-crafted differentiable renderer가 존재하지 않는 natural image에 관해 HoloGAN이 직접적으로 3D representation을 학습할 수 있도록 한다. 같은 scene에 관해 새로운 view를 생성하기 위해, HoloGAN에서는 학습된 3D feature(representation)에 3D rigid-body transformation을 직접 적용하고, 이와 동시에 같이 학습되는 neural renderer를 사용하여 결과를 시각화한다.
HoloGAN의 Generator
HoloGAN의 generator는 먼저 3D convolution layer 모듈을 통해서 이미지의 대상이 canonical pose로 주어졌다는 가정 하에 3D representation을 학습하고, 3D transformation을 통해서 학습한 3D representation을 특정한 pose로 변환하며, projection unit을 통해 visibility를 계산한 후, 2D convolution layer 모듈을 통해 각 픽셀별로 shaded color value를 구한다.
학습 과정에서는 uniform distribution에서 random pose를 샘플링하고, 3D feature를 2D image로 바꾸는 렌더링을 수행하기 전에 3D feature를 샘플링한 pose로 변환한다. 이때 random하게 pose를 샘플링하는 이 perturbation이 생성자(generator)가 3D transformation과 분별자(discriminator)를 속일 수 있는 이미지를 생성하는데 있어서 적합한 disentangled representation을 학습하도록 만든다고 한다. Pose transformation을 데이터를 통해 학습할 수도 있겠지만 이처럼 미분 가능한 3D transformation 연산을 HoloGAN에 직접 제공한 것은, 논문 연구 당시의 여러 사례들로 비추어 볼 때 novel view synthesis를 하는 데 있어서 explicit rigid-body transformation을 사용하는 것이 artefact는 줄이면서 더 뚜렷한 이미지를 생성했기 때문이라고 한다. 더 중요한 것은 이렇게 3D transformation 연산을 직접 사용하는 것이 explicit 3D rigid-body transformation이 적용될 수 있는 representation에 inductive bias를 제공해주는 효과가 있다고 한다. 그 결과, 학습된 representation은 3D에서 explicit 하면서 pose와 identity(shape + appearance)로 구분될(disentangled) 수 있다고 한다.
저자는 이전에 출판된 논문을 인용하면서 학습된 disentangled representation을 intrinsic과 extrinsic 요소로 분류할 수 있다고 한다. Intrinsic 요소에는 shape, appearance가 포함되고, extrinsic 요소에는 pose(elevation, azimuth), lighting(location, intensity)이 속할 수 있다고 한다. HoloGAN의 모델 디자인은 3D world에 관한 inductive bias를 더 사용함으로써 intrinsic과 extrinsic 요소로 분리하는 데 도움이 된다고 설명하고 있다. 구체적으로 3D transformation를 적용하는 건 pose를 control 할 수 있게끔 하고, 그 transformation의 적용 대상인 학습된 3D features는 identity를 control 할 수 있게 만든다.
HoloGAN은 2D image로부터 의미 있는 3D representation을 학습하기 위해 HoloGAN은 occlusion을 추론하는 differentiable projection unit을 학습한다. 자세히 말하자면, projection unit은 3D feature인 4차원의 feature를 받아서 2D feature인 3차원의 feature를 반환한다. Projection unit 자체는 RenderNet에서 사용한 바와 크게 다르지 않다. Reshaping layer에서는 channel 차원과 depth 차원을 concatenate 하여 4차원인
학습 이미지들이 다양한 관점에서 캡처되었기 때문에 HoloGAN은 perspective projection을 학습할 필요가 있다. 그러나 학습 이미지들 외에 아무런 데이터가 주어지지 않아 camera intrinsic parameter에 관한 정보를 알 수가 없으므로, HoloGAN에서는 2D feature로 projection 시키기 전에 AdaIN을 사용하지 않은 두 개의 3D convolution layer를 사용하여 3D representation을 perspective frustum으로 변화시킨다.
HoloGAN은 학습된 constant tensor로부터 3D representation을 생성한다. 대신 랜덤 노이즈인
StyleGAN
먼저 StyleGAN에 관해 자세히 리뷰한 글이 있어서 StyleGAN 논문에 관한 상세한 내용은 아래 링크를 참고하는 것이 좋다.
StyleGAN: Style transfer와 mapping network를 사용하여 disentanglement를 향상시킨 generative Model
이번 글에서는 일명 StyleGAN이라고 불리는 'A Style-Based Generator Architecture for Generative Adversarial Network' 논문에 관해 핵심 위주로 리뷰 해 보고자 한다. StyleGAN은 출판 당시에도 회자되었던 논문이고,
glanceyes.com
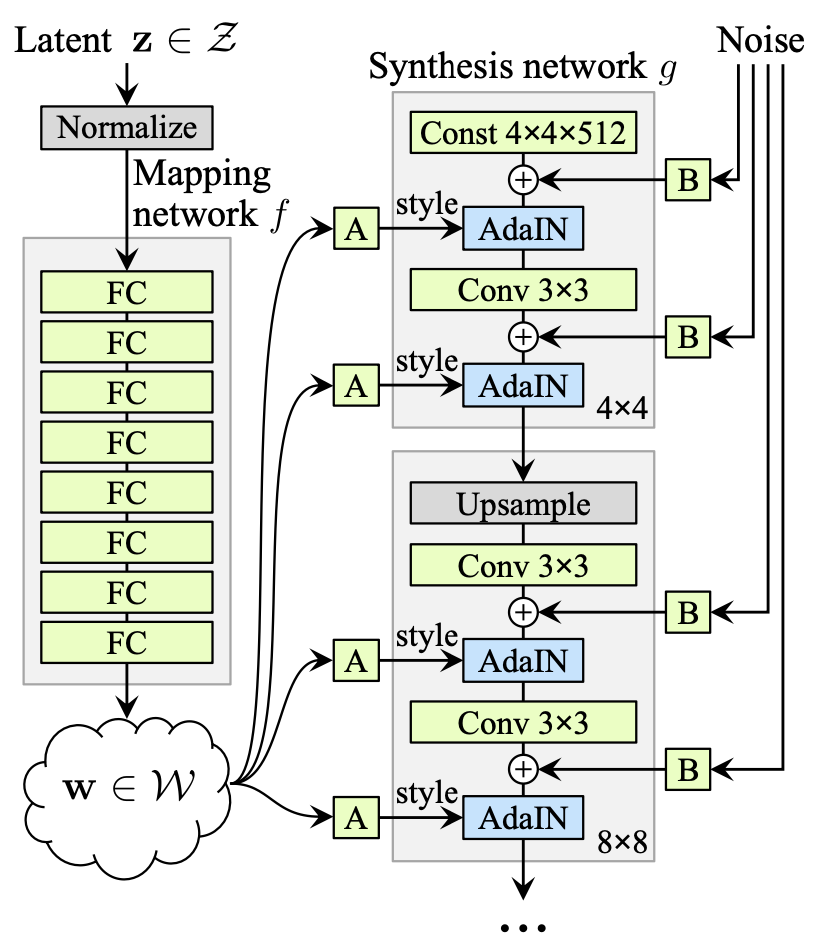
StyleGAN은 다른 원하는 데이터(style 이미지)로부터 style 정보를 가져와서 현재 조작하고자 하는 이미지에 대한 style 정보를 바꿀 수 있는 generative model이다. StyleGAN이 어떠한 배경에서 제안되었는지를 알려면 StyleGAN 이전에 제안된 논문인 PGGAN(Progressive Growing of GANs for Improved Quality, Stability, and Variation)에 관해서 알아 볼 필요가 있다. PGGAN은 학습 과정에서 점진적으로 레이어를 추가해 감으로써 고해상도 이미지를 학습하고 생성하는데 좋은 성과를 보인 모델로 알려져 있다. 그러나 레이어를 점차 증가해나가는 방식으로 학습을 해서 학습 시간이 오래 걸릴 뿐만이 아니라 이미지의 특징들이 구분(disentangled)되어 있지 않아서 이미지의 특징을 제어하는 데 어려움을 겪었다. 이를 해결하고자 StyleGAN에서는 mapping network와 AdaIN 기법을 사용하여 하나의 이미지를 여러 개의 sementic 정보로 구성되는 형태로 레이어를 통과하면서 style을 적용해 나가는 방법으로 architecture를 구현했다. 즉, 어떤 한 이미지를 생성하는 과정에서 여러 style 정보가 layer를 거칠 때마다 적용될 수 있도록 하여 보다 다양한 이미지를 생성할 수 있도록 하는 feed-forward 방식의 style transfer를 수행한다.
Mapping Network
StyleGAN에서는 특정 space에 있는 sampling한
Style Transfer
Style transfer는 어떤 유지하고자 하는 content에다가 유사하게 따라하고 싶은 style을 결합하여 새로운 이미지를 생성하고자 하는 작업이다. Style을 Gram matrix로 정의한다면, Gram matrix가 서로 유사해지도록 학습해서 기존의 content를 지님과 동시에 새로운 style을 지니는 이미지를 생성할 수 있다. 여기서 Gram matrix는 channel 별 공분산을 구한 행렬로 이해해도 되는데, 각 channel이 어떠한 channel과 유사한지 그 상관관계를 구한 matrix라고 봐도 좋다.
그러나 style을 Gram matrix가 아니라 어떤 한 데이터의 분포로 정의를 한다면, style transfer을 다음과 같이 생각해 볼 수 있을 것이다. 어떤 데이터가 정규분포를 따른다고 가정하고, 그 데이터의 정규분포에 관한 평균과 분산을 알고 있으면 이를 표준화시켜서 표준정규분포로 바꿀 수 있다. 이를 우리가 원하고자 하는 정규분포로 바꾸고 싶으면 앞서 바꾼 표준정규분포에다가 바꾸고 싶은 분포의 분산을 곱하고 거기에 평균을 더하면 된다. 즉, 우리가 원하고자 하는 style로 변환하겠다는 것은, 기존에 있던 feature 데이터의 분포를 style의 분포로 변환하는 과정으로 이해할 수 있다.
AdaIN(Adaptive Instance Normalization)
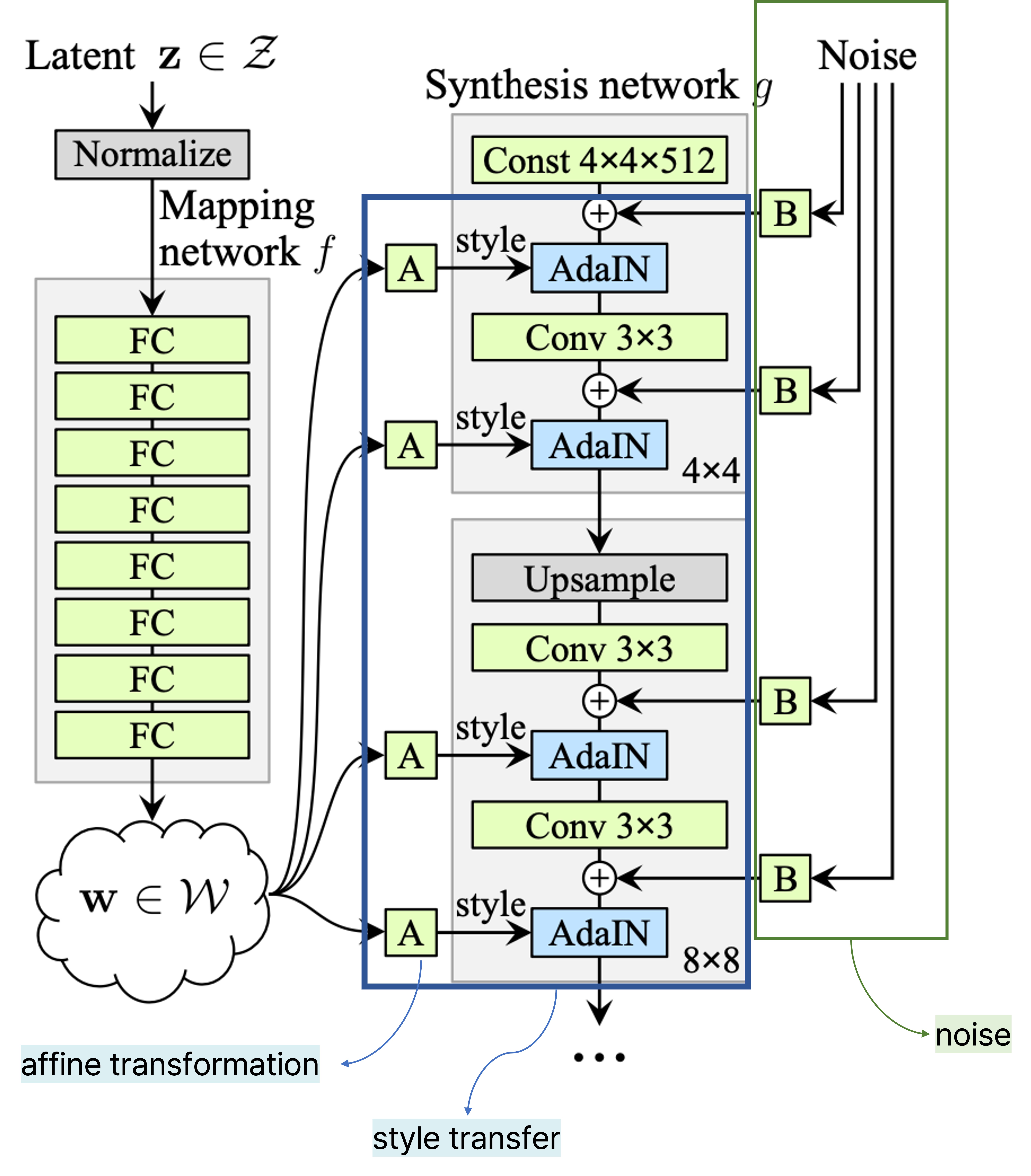
여기서 인용한 AdaIN은 컨텐츠에 있는 이미지가 정규분포를 따른다고 가정하고 표준정규분포로 만든 후, 그 분포를 다시 style의 분포로 옮기는 역할을 한다. 즉, content feature의 평균과 분산을 가지고 content feature를 style feature의 분포와 align 시키는 것이다. 그래서 HoloGAN에서는 학습 대상이 되는 이미지의 'style'이라고 일컬어지는 서로 다른 level의 feature의 평균(mean)과 표준 편차(standard deviation)를 matching 시키기 위해 AdaIN을 사용하여 학습된 constant tensor인 template을 변환하는 과정을 통해 이미지를 생성하는 것으로 볼 수 있다. Instance normalization이란 이름이 붙은 건 하나의 이미지 feature에 대하여 한 channel에 관해 정규화를 수행하는 과정과 같아서다. 단, 이를 정규화한 후 다시 주어진 style feature의 분포로 변환하는 과정이 추가되어 'adaptive'란 수식어가 붙은 것이다.
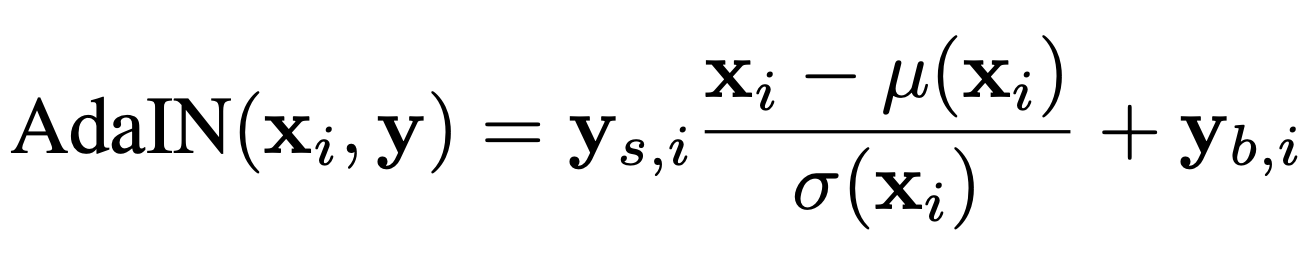
Style 정보가 layer에 적용되기 전에 affine transformation을 적용하여 각각의 channel 마다 style 정보를 반영하고, 각각의 channel마다 feature의 mean과 variance 값을 바꾸는 정규화를 수행한다. 또한 정규화된 feature map에 관하여 얼마만큼 scaling하고 얼마만큼 bias를 더할지를 결정했다.

또한 StyleGAN에서는 stochastic variation을 처리할 수 있도록 noise를 사용했는데, 각각의 layer마다 noise가 반영되도록 네트워크를 구성했다. 이를 적용한 이유는, 사람의 이미지를 예시로 들자면 그 사람의 피부 상태(여드름, 주근깨, 기미 등)나 머리 스타일링(바람에 흩날리는지 등)처럼 확률적인 측면을 고려할 수 있도록 하는 것이다. 이러한 noise를 독립적으로 layer마다 주입함으로써 coarse detail부터 upsampling을 통해 fine detail까지 서로 다른 레벨의 디테일에 variation을 준다. 위의 그림에서 (a)는 모든 레이어에 noise를 준 것, (b)는 noise를 주지 않은 것, (c)는 오직 fine layer에 noise를 주어서 머리카락이 매우 곱슬거림을 보여주고, (d)는 오직 coarse layer에 noise를 주어서 머리카락이 (c)보다 덜 곱슬거리는 것을 확인할 수 있다.
HoloGAN의 저자는 이러한 AdaIN을 HoloGAN의 generator에도 적용했는데, style controller이자 identity인 latent vector
초기 입력을 변수 대신 상수(constant) Tensor로 주는 이유
PGGAN에서는 latent vector를 변수로 하여 초기 input으로 넣었다. 그러나 StyleGAN에서는 AdaIN을 통해 style 정보인
HoloGAN과 StyleGAN 비교
HoloGAN은 위에서 설명한 방식을 사용한 StyleGAN과 유사하지만, 두 가지 중요한 방면에서 차이가 있다.
첫 번째로 HoloGAN은 이미지를 생성하기 위해 2D feature로 projection 시키기 전에, 학습된 4차원의 constant tensor로부터 3D feature(representation)을 학습한다는 것이다. 반면에 StyleGAN은 3D feature를 학습하는 HoloGAN과 달리 오직 2D feature만 학습한다.
두 번째로 HoloGAN은 학습 과정에서 3D feature를 rigid-body transformation과 결합함으로써 disentangled representation을 학습할 수 있다는 것이다. 그러나 StyleGAN은 각각의 convolution layer마다 독립적인 랜덤의 noise를 주입하는데, 이는 결과적으로 pose, identity 같은 coarse feature부터 hair, freckle 같은 fine-grained detail까지 feature resolution에 의존하면서 2D feature를 서로 다른 레벨의 디테일로 분리하는 걸 학습한다. 그러나 HoloGAN은 여기서 더 나아가 coarse feature에서 pose와 identity을 구분하며, pose는 3D transformation에 의해, shape는 3D feature에 의해, appearance는 2D feature에 의해 조절된다.
HoloGAN과 다른 모델과의 비교

논문에서는 HoloGAN이 VON(Visual Object Networks)과 같은 다른 모델보다 더 제약된 해상도의 deep 3D representation을 가지고 더 나은 퀄리티와 복잡한 배경에 관해 이미지를 생성할 수 있다는 점도 강조하고 있다. 여기서 VON은 이미지의 shape를 이미 학습한 상태에서 3D shape의 distribution에서 sampling을 하여 기하학적인 이미지를 렌더링 하는 모델이다. 반면에 HoloGAN은 이미지의 shape에 관한 사전 학습 없이 이미지로부터 deep 3D representation을 추출하여 렌더링 한다.
3D feature를 학습하고자 3D convolution을 채택한 것에 더하여 HoloGAN에서는 2D 이미지로 3D feature를 projection 시키기 전에, 학습된 3D feature를 랜덤한 pose로 변환함으로써 3D world에 관해 더 높은 inductive bias를 지닌다고 한다. 이러한 random pose transformation은 HoloGAN이 구분될 수 있으면서(disentangled) 가능한 모든 view에 관해 렌더링될 수 있는 3D representation을 학습하는 걸 보장하는 데 매우 중요하다고 한다. 그러나 이와 유사한 방식을 사용하는 DR-GAN이 implcit vector representation을 사용하는 반면에 HoloGAN은 explicit 3D rigid-body transformation을 수행한다고 한다.
HoloGAN에서 정의한 Loss Function
HoloGAN을 학습하기 위한 loss function는 regularizer를 포함하여 크게 세 부분으로 설명할 수 있다.
Identity Regularizer
먼저 HoloGAN은 identity regularizer를 사용했는데, 생성된 이미지로부터 재건된 vector가 생성자
Style Discriminator
앞서 말한 바처럼 HoloGAN의 생성자는 학습 대상의 이미지의 서로 다른 레벨에 관해 'style'을 matching 시키도록 설계되었다고 했는데, 이는 서로 다른 스케일에 있는 이미지의 속성을 효과적으로 조절할 수 있다고 한다. 그래서 추가적으로 진짜와 가짜 이미지를 분류하는 discriminator를 사용한 것에 더하여, 같은 task를 수행하지만 서로 다른 feature level에 관해 수행하는 multi-scale style discriminators를 사용했으며, style discriminator는 이미지의 'style'이라고 불리는 평균
위에서 설명한 loss에다가 원래 GAN 모델임을 고려하여 DC-GAN에서 사용한 GAN loss까지 함께 고려하여 전체 loss를 정리하면 다음과 같다. 여기서
HoloGAN과 RenderNet
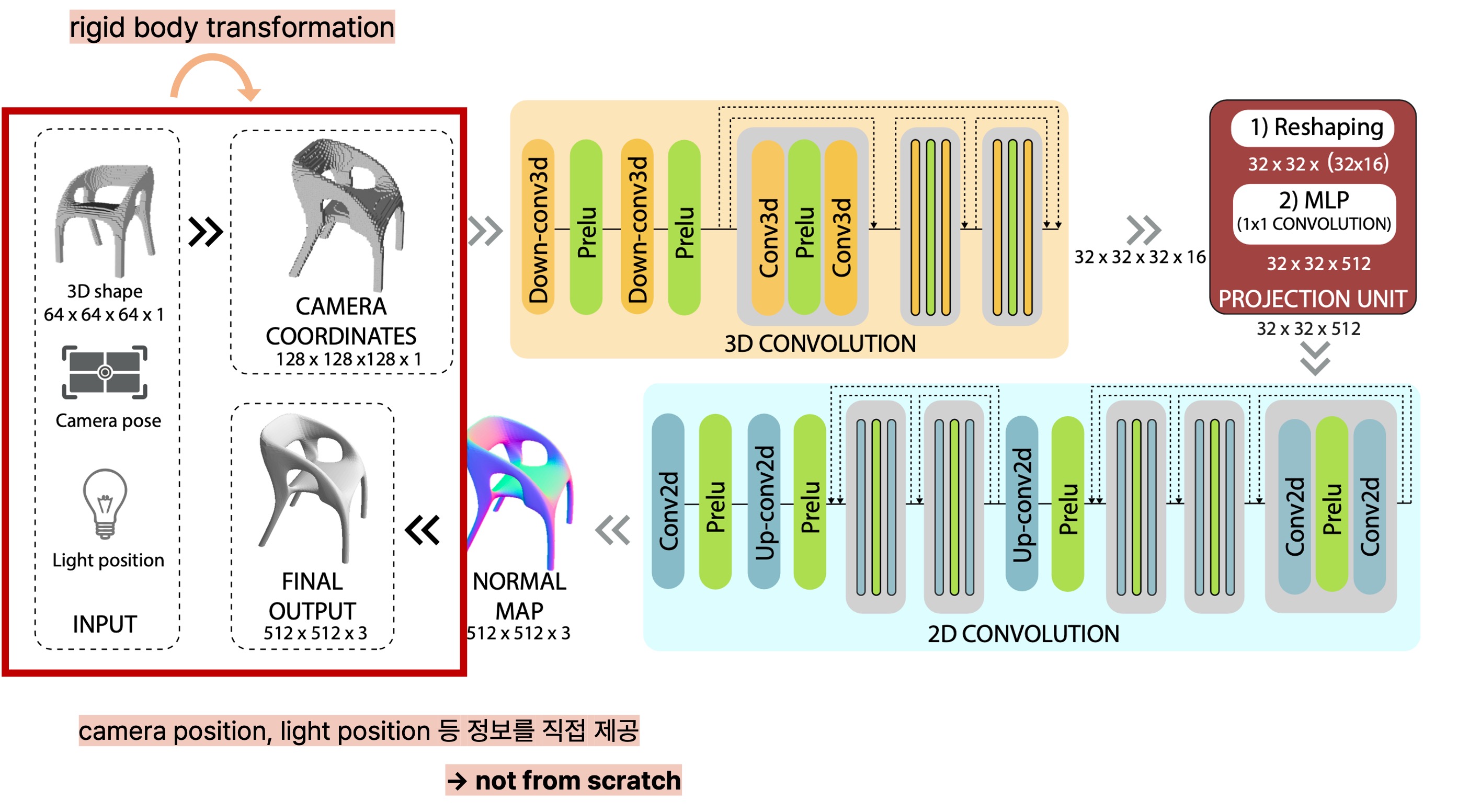
HoloGAN은 논문의 제 1 저자가 이전에 연구한 RenderNet의 아이디어를 차용했다고 한다. RenderNet의 핵심을 간단히 요약하면, RenderNet은 end-to-end로 학습 가능하고 convolution layer로 이루어지며, differentiable rendering을 수행할 수 있는 network이다. 특히 RenderNet에서 3D object를 2D image로 렌더링하는 과정을 3D convolution layers와 projection unit로 구성된 visibility computation, 2D convolutional layers로 구성된 shading computation의 두 단계로 나누어 설명한다. 또한 visibility computation 전에 input인 3D object를 사전에 정한 어떤 한 pose의 각도로 변환하는 작업을 거치는데, 이는 convolutional layer에서 각도에 관한 representation까지 학습하는 것은 어려워서다. 즉, RenderNet에서는 3D convolutional layer를 통해 3D representation을 학습하고, projection unit에서 3D representation을 2D image로 projection 하면서 visibility가 어떻게 되는지를 계산하며, 2D 이미지를 2D convolutional layers에 통과시키면서 shading을 계산하는 과정을 거친다.
RenderNet에 관한 자세한 내용은 아래 링크로 첨부한 RenderNet 논문 리뷰를 참고하면 된다.RenderNet 논문 리뷰
RenderNet: 3D shape를 가지고 differentiable rendering을 수행할 수 있는 Convolutional network
들어가기 전에 이번 논문 리뷰에서는 differentiable rendering을 CNN(Convolutional Neural Network)를 사용하여 shading effect, 3D shape reconstruction, novel-view synthesis task 등 다양한 graphics rendering 작업에 응용할 수 있
glanceyes.com
HoloGAN에서는 3D scene에서 2D 이미지로의 렌더링을 수행하지는 않고 GAN 본연의 목적에 맞게 새로운 이미지를 잘 생성하는 모델을 만드는 걸 목표로 하지만, 앞서 설명한 RenderNet의 두 단계로 구성된 렌더링 과정에서 아이디어를 얻어 generator 모델을 구현했다.
첫 번째 3D convolution layers 모듈에서는 이미지의 3D representation을 학습하고, 3D rigid-body transformation을 적용하여 특정 camera pose로 되도록 3D representation을 변환한다. 이때 camera pose는 학습 과정에서는 랜덤하게 sampling 되고, 테스트 시에는 사용자가 생성하기를 원하는 특정 각도로 주어진다. 이후 또 다른 3D convolution layers 모듈을 통과하면서 3D representation을 perspective frustum으로 변화(morph)시키고, projection unit을 사용하여 3D feature를 2D image로 projection 시킨다. 개인적으로 "morph 3D representation into a perspective frustum"이라는 문장을 이해하기 쉽지 않았는데, 3D feature를 perspective projection을 고려하기 위해 원근법을 고려하는 절두체(frustum)에 나타내는 것으로 이해했다. (Perspective projection에서 나온 개념이라고 생각한 접근법인데, 틀린 설명일 수도 있으므로 언제든지 댓글로 지적해주시면 감사하겠습니다.) 이 과정이 앞서 RenderNet에서 설명한 'visibility computation' 부분과 유사하다는 걸 볼 수 있다. 또한 그 이후에는 변환한 2D feature를 2D convolution layers 모듈에 통과시키면서 각 pixel 별로 shading을 학습하는데, 이도 마찬가지로 RenderNet의 'shading computation' 부분과 유사하다는 걸 확인할 수 있다. 단, RenderNet과의 차이라고 하면 HoloGAN은 RenderNet과는 달리 neural renderer의 사전 학습이 필요로 하지 않을 뿐더러 3D-shape과 2D image 간의 짝지어진 dataset이 요구되지도 않는다.
Rendering 과정을 사용한 HoloGAN
그러면 왜 RenderNet의 두 단계로 구성된 렌더링 과정을 HoloGAN에 차용했는지 궁금해질 수 있다. 논문의 저자는 모든 2D 이미지가 기본적으로 3D world의 projection라고 생각했다. 다시 말해, 우리가 눈으로 보거나 카메라로 찍은 모든 대상의 2D 이미지는 실제 현실 3D 좌표계에 존재하는 대상을 rendering 한 결과와 같다. 그러면 주어진 2D 이미지의 3D representation을 학습하고, 그 3D representation에서 각도(pose)만 변환하여 이를 2D 이미지로 다시 렌더링하면 그 2D 이미지를 다른 각도에서 바라본 새로운 이미지를 생성한 것과 같지 않느냐는 것이다. 개인적으로 이 부분이 HoloGAN에서 배워갈 수 있는 가장 중요한 인사이트가 아닐까 하는 생각이 든다.
학습한 3D representation에 3D rigid-body transformation을 직접 적용하여 view manipulation을 실현했는데, 이는 generator를 통한 2D 이미지 생성이 학습된 3D representation을 2D image로 mapping 하는 것과는 독립적인(view-dependent)이라고 설명하고 있다. 개인적으로 이 부분은 결국 학습된 3D representation에 직접 transformation을 적용한 후 network를 통해 2D 이미지로 mapping을 학습하므로 view에 관한 transformation과 3D representation을 2D image로 렌더링 하는 과정이 분리되어 있다고 받아들였다.
출처
1. https://arxiv.org/abs/1904.01326, HoloGAN: Unsupervised learning of 3D representations from natural images, Thu Nguyen-Phuoc
2. https://arxiv.org/abs/1812.04948, A Style-Based Generator Architecture for Generative Adversarial Networks, Samuli Laine
3. https://www.youtube.com/watch?v=HXgfw3Z5zRo&list=LL&index=2&t=1893s, StyleGAN: 고해상도 가상 얼굴 이미지 생성 기술 (꼼꼼한 딥러닝 논문 리뷰와 코드 실습), 나동빈
Contents
소중한 공감 감사합니다.