AI/AI 기본
PyTorch에서의 하이퍼파라미터(Hyperparameter) 튜닝
- -
2022년 1월 24일(월)부터 28일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
Hyperparameter Tuning
모델의 Parameter는 학습 과정에서 조정되는 값이지만, Hyperparameter(하이퍼파라미터)는 사용자가 직접 설정하는 값이다.
모델이 스스로 학습하지 않는 learning rate, 모델의 크기, optimizer의 종류 등이 이에 해당된다.
최적의 Hyperparameter는 데이터마다 다르며, 이에 대한 튜닝은 성능을 높일 수 있는 방법이다.
그래서 시간적 여유가 되면 최적의 Hyperparameter를 찾는 것이 필요하지만, 시간 대비 효과가 떨어져서 최근에는 그 영향력이 크진 않다.
보통 모델 자체를 손보거나 데이터를 추가하는 방법 이후에 시도하며, 무엇보다 더 중요한 건 질 좋은 데이터를 고르고 이를 학습에 추가하는 것이다.
대표적으로 Grid Search와 Random Search가 있으며, 최근에는 Bayesian Optimization 기법이 사용된다.
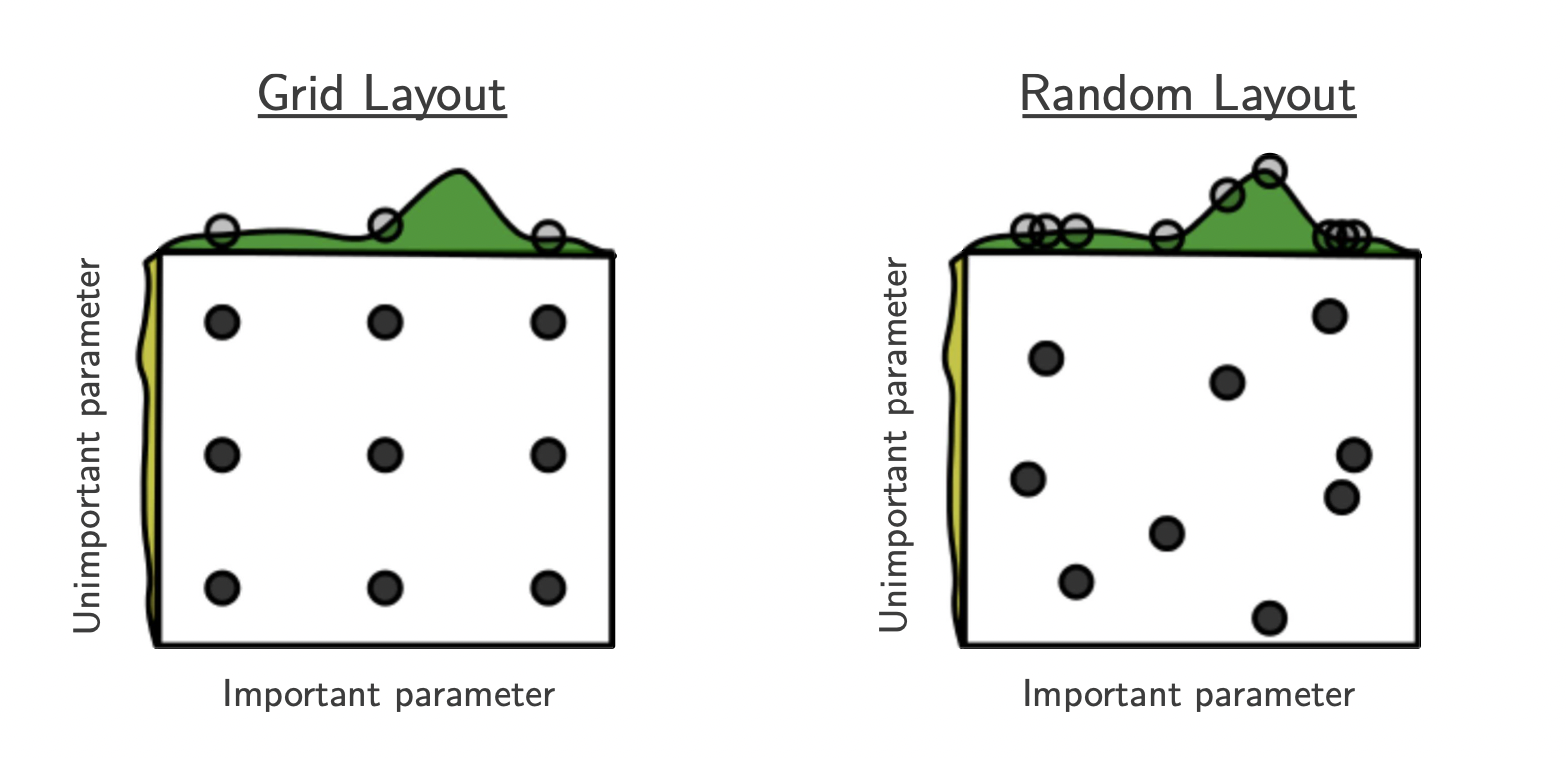
[출처] Random search for hyper-parameter optimization. Journal of Machine Learning Research 13, 281–305 (2012)
Grid Search
적용해볼 값들을 Hyperparameter로 미리 정하여 모든 조합을 시행하는 것이다.
원하는 값만 직접 지정하면 되어서 간단하지만 Hyperparameter의 개수가 많을수록 수행하는 데 시간이 오래 걸린다.
Random Search
랜덤하게 Hyperparameter 값을 사용해보고 그중 우수한 Hyperparameter를 활용하는 것이며, 최적의 모델을 생성하는 데 있어서 시간 대비 성능이 뛰어나다고 알려져 있다. 적용해볼 값들을 Hyperparameter로 미리 정하여 범위 내 무작위 값을 추출하는데, Grid Search보다 훨씬 다양한 조합들을 시험해볼 수 있다.
Bayesian Optimization
베이지안 정리를 기반으로 관측치를 사용하여 후보가 될 수 있는 Hyperparameter를 결정하는 기법인데, 이를 정리하면 다음과 같다고 할 수 있다.
- 관측치를 바탕으로 최적값을 구하고자 하는 objective function에 대해 확률적으로 추정한다.
- 이를 바탕으로 새로운 Hyperparameter를 관측할 값을 선정하고, 그 조합을 바탕으로 다시 objective function을 추정한다.
- 1과 2를 특정 기준을 만족할 때까지 반복한다.
다음과 같은 두 가지 구성 요소를 지닌다고 할 수 있다.
- Surrogate Model(근사수학모델)
- 우리가 궁금한 objective function 또는 모형에 대한 확률적인 추정이다.
- 대부분 각 입력에 대해 정규분포를 따른다고 가정한다.
- Acquisition Function
- 데이터를 기반으로 이를 surrogate model에 적용했을 때 다음에 어떤 점을 탐색해야 하는지를 설정해주는 함수이다.
- objective function을 잘 추정하기 위한 입력값을 추천해주는 함수이다.
Ray
https://docs.ray.io/en/latest/tune/index.html
Tune: Scalable Hyperparameter Tuning — Ray 1.11.0
Learn how to use Ray Tune for various machine learning frameworks in just a few steps. Click on the tabs to see code examples. Tip We’d love to hear your feedback on using Tune - get in touch! To run this example, install the following: pip install "ray[
docs.ray.io
Multi-Node Multi Propcessing을 지원하는 모듈이며, ML 또는 DL의 병렬 처리를 위해 개발되었다.
특히 Hyperparameter Search를 위한 다양한 모듈을 제공한다.
!pip install ray
!pip install tensorboardX
data_dir = os.path.abspath("./data")
load_data(data_dir)
# 하이퍼파라미터를 탐색할 범위(search space) 지정
config = {
"l1": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"l2": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16])
}
# 학습 스케줄링 알고리즘 지정
# ASHAScheduler의 경우 학습을 진행하면서 성능이 떨어지는 모델은 가지치기한다.
scheduler = ASHAScheduler(
metric="loss", mode="min", max_t=max_num_epochs, grace_period=1, reduction_factor=2)
reporter = CLIReporter(metric_columns=["loss", "accuracy", "training_iteration"])
# 학습 실행
result = tune.run(partial(train_cifar, data_dir=data_dir),
resources_per_trial={"cpu": 2, "gpu": gpus_per_trial},
config=config, num_samples=num_samples,
scheduler=scheduler,
progress_reporter=reporter)
Contents
소중한 공감 감사합니다.