Back-End
Rhymix Chatbot(라이믹스 챗봇) 모듈 제작 후기
- -
2018년 여름방학에 인터넷 상에서 AI 챗봇 열풍이 불었다. 지금은 워낙 챗봇을 비즈니스의 용도로 운영하는 웹 사이트가 많이 있고 카카오톡 등 다양한 플랫폼에서 일반인들도 챗봇을 제작할 수 있는 환경을 제공하지만, 당시에는 AI를 통한 챗봇이 지금처럼 대중화되지는 않았다. 당시에 Rhymix 기반의 학교 웹 사이트를 운영해왔었고 언어 처리에 관심이 있어서 이번 기회에 챗봇 모듈을 제작하기로 결심했었다.
그 웹 사이트에서는 학교에 지원하고자 하는 학생들의 질문을 받는 게시판이 있었는데, 꽤 많은 학생들이 질문을 올리다 보니 같은 내용의 질문들이 서로 중복되거나 유사한 내용의 질문들이 올라와서 관리하는 교사와 학생들이 다소 힘들어했던 기억이 있다. 그래서 아예 챗봇을 제작하여 비슷한 분류의 성격을 띠는 질문은 학교의 공식적인 답변을 얻을 수 있도록 하여 운영의 효율성을 높이고자 했었다. 그렇지만...
이용자 활성화 목적으로서의 결과는 실패였다. 실패한 이유는 크게 다음과 같다.
1. Rhymix(XE)의 모듈 제작이 처음이었다. 개학 전까지 만들어야 했지만 너무 성급한 나머지 Rhymix의 모듈 구조와 동작 과정을 이해하지도 않은 채 덤벼든 것이다. 그래도 직접 몸으로 부딪치면서 배운 덕분에 Rhymix의 코어도 커스터마이징 하는 등 개괄적인 내용을 배워갔다.
2. PHP로 챗봇을 만든다는 것 자체가 내 실력으로서는 무리였다. 파이썬에는 각종 대화 언어 처리 라이브러리가 있지만 PHP는 그러한 라이브러리를 찾을 수 없었다. 그래서 언어처리를 미리 수행하는 외부 API를 사용하여 질문의 키워드와 의도 정도만 파악할 수 있는 수준까지만 개발했다. 그러나 이는 다양하고 많은 질문들에 관해 정확한 답을 출력하기에는 역부족이었다.
3. 챗봇의 답변을 제작할 수 있을 만한 학교의 정보 자료가 부족했다. 졸업을 이미 한 상태에서 학교와 커뮤니케이션을 꾸준히 이어갈 수가 없었던 것도 큰 걸림돌이었다.
그래도 당시에는 실패했으나, 약 2-3년이 지난 뒤로 다시 챗봇 모듈 제작에 도전해보려고 한다. Rhymix 모듈의 MVC 구조를 다시 복습할 수 있는 좋은 계기일 뿐만 아니라 그때 사용했던 ETRI에서 제공하는 API가 그 사이에 꽤 개선된 것으로 보인다. 대화 처리 API도 별도로 제공하는 등 기술 발전으로 인해 위에서 서술한 제약이 크게 사라질 것으로 보인다. 소집 해제까지 열심히 공부해서 이 모듈은 꼭 완성해 볼 생각이다.
아래는 모듈 제작 시작 얼마 후에 Rhymix 개발자 사이트인 XETOWN이라는 커뮤니티에 작성했던 글이다.
챗봇 모듈 작업기
8월 말부터 제작은 해오고 있는데 정말 모듈 제작 까다롭네요... 아직 실력이 많이 부족하다는 걸 느꼈습니다. 모듈 제작하시는 분들 존경합니다. XE에서 채팅 관련 모듈은 존재하는 것으로 알고
xetown.com
8월 말부터 제작은 해오고 있는데 정말 모듈 제작 까다롭다.
아직 실력이 많이 부족하다는 걸 느꼈다. 모듈 제작하시는 분들을 존경한다.
XE에서 채팅 관련 모듈은 존재하는 것으로 알고 있는데 아직 챗봇 관련 모듈은 제작된 바가 없는 것 같다. PHP 자체가 무겁고 AI 관련 라이브러리가 많지 않은 것도 한몫하는 것 같다. 그래서 챗봇이란 게 요즘 화제가 되고 있기도 하고, 운영하고 있는 사이트에서 이용자들이 자주 묻는 질문들은 언제든지 빠르게 답장 줄 수 있도록 하기 위해서 한 번 시도해보고 있긴 한데... 아직 갈 길이 먼 것 같다.
처음에 구상할 때는 구름이님이 제작하신 구글 자연어 분석 API 기반 인공지능 모듈(https://xetown.com/rxe_market/815098)의 텍스트 분석 기능을 이용해서 키워드를 뽑아 DB에 저장된 그에 맞는 답변을 출력하는 식으로 제작하려고 했다.
그런데 아쉽게도 구글 자연어 분석 API(https://cloud.google.com/natural-language/)로만은 모든 대화의 중요한 키워드를 딱 골라 뽑지 못한다.
예를 들어서 인사말로 '만나서 반가워'라는 문장에서 키워드를 뽑으라고 하면 '만나' 또는 '반가워' 같이 중요한 용언을 뽑아야 되는데 구글 자연어 분석 API은 아래처럼
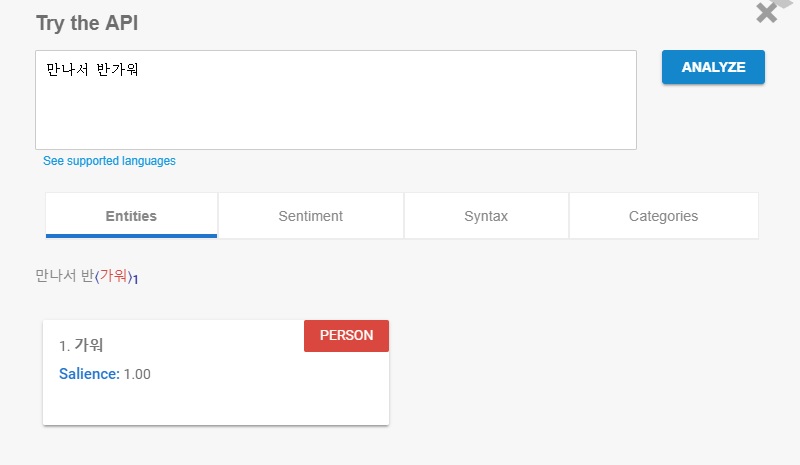
'만나서 반가워'에서 가워를 핵심 entity로 뽑았고 심지어 사람 관련 키워드로 인식한다. ^^;;
또 한 가지 문제점이 인공지능 모듈로 키워드를 추출하는 데 대략 1~2초 정도 소요되는데 챗봇과 대화하는 상황에서 이 시간이 꽤나 길게 느껴진다.
그래서 구름이님이 제작하신 인공지능 모듈뿐만이 아니라 ETRI에서 개발한 공공 인공지능 오픈 API(http://aiopen.etri.re.kr/)의 질문 분석 기능도 같이 사용하기로 결정했다. 이 API가 좋은 점이 질문의 의도와 정답 형태를 추출해서 답변의 정확도를 높일 수 있다는 것이다.
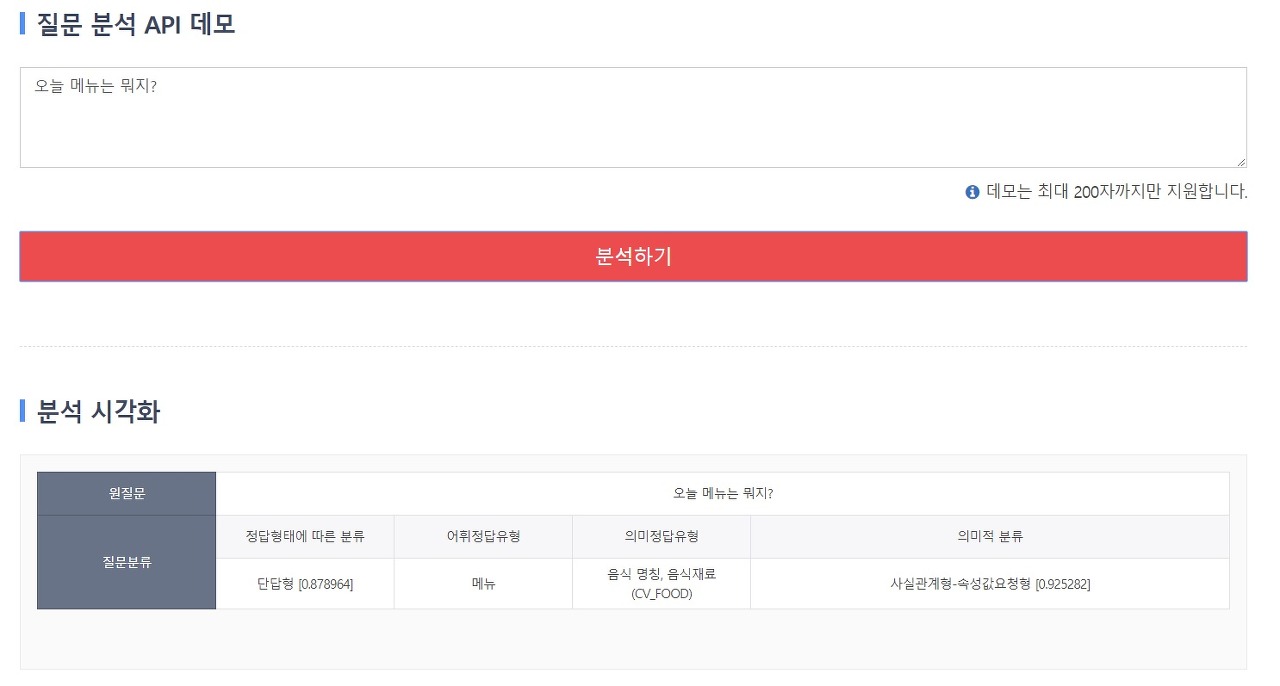
이 API는 상업적 목적으로 사용하지 않는 이상 API Key를 신청하면 누구나 이용 가능하고, 1일 사용 가능한 횟수가 5,000건이어서 비상업적인 소규모 사이트에서는 충분히 활용 가능하다고 생각된다.

질문에 대하여 챗봇이 할 수 있는 답변들은 모듈 설정에서 의미 정답(intention), 어휘 정답, 필수 단어(entity), 키워드(keyword), 답변, 트리거를 입력할 수 있도록 했다. 이렇게 의도와 예상 답변 유형을 미리 추출하고 거기서 신뢰도가 높은 답변을 추출하니까 예전보다 좀 더 정확도가 높아진 것 같다.
그래도 아직 많이 부족하다고 느끼는 건 입력한 데이터량이 너무 적어서 예상에서 벗어난 질문을 이용자가 입력했을 때 어떻게 답변할지에 관해서 잘 모르겠다는 점이다. 또 만일 데이터량이 많아지면 답변 목록에서 정확한 답변을 추출하는 데 부하도 심할 것 같고 시간도 많이 들어서... 실제로 정말 비즈니스용으로 쓰기에는 턱없이 부족할 것 같다. 그냥 소규모 사이트에서 재미 삼아 시범용으로 사용하는 정도의 퀄리티만 나와도 만족할 것 같다.


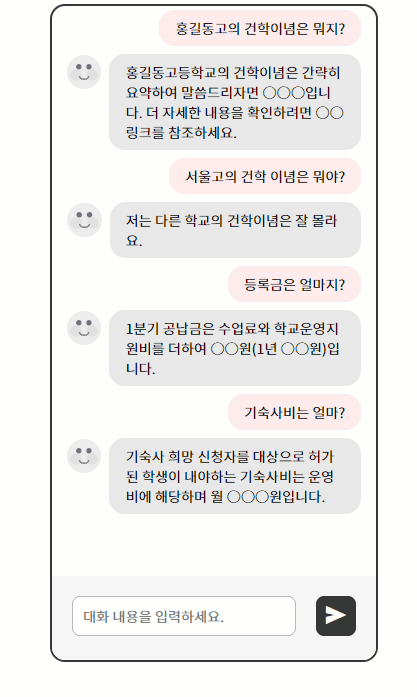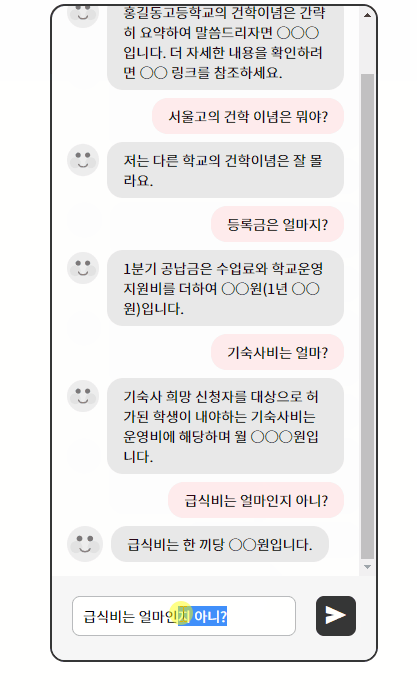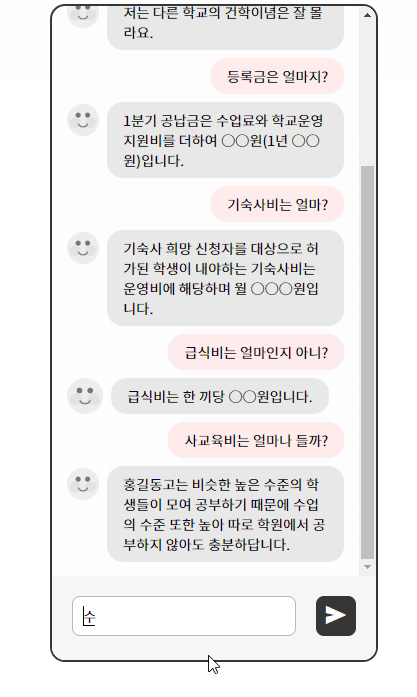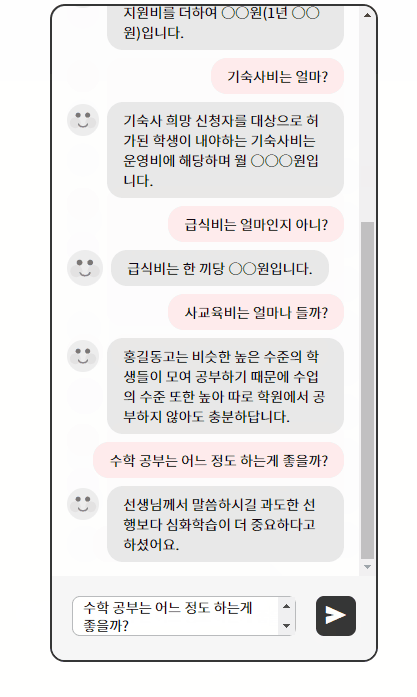



예상 답변 목록에 트리거 이름을 입력하면 답변을 출력하면서 다른 모듈과 연계하여 추가적인 정보를 출력한다.
또한 원하는 추가 정보 출력 형태도 답변 등록 시 입력 가능하도록 했다.
API로 받은 데이터를 잘 처리하는 것도 많이 어렵다...;;
계속 데이터를 입력해보면서 최대한 정확도를 끌어올려봐야겠다.
'Back-End' 카테고리의 다른 글
| Visual Programming으로 AI 모델링이 가능한 웹 어플리케이션 개발 후기 (0) | 2022.09.01 |
|---|---|
| GCP(Google Cloud Platform) VM 인스턴스 생성하기 (0) | 2022.07.19 |
| AWS CodeDeploy로 배포할 때 환경변수 사용하는 방법, Parameter Store (0) | 2022.06.16 |
| [RepositoryNotFoundError] TypeORM에서 Entity를 찾지 못하는 문제 해결 방법 (0) | 2022.06.16 |
| Rhymix 개발에서 자주 사용하는 이메일 발송 함수 (0) | 2021.02.08 |
Contents
소중한 공감 감사합니다.