AI/AI 기본
Transformer를 사용하는 것이 항상 좋을까?
- -
들어가기 전에
'Attention is All You Need'라는 논문을 필두로 CV, NLP, RecSys 등 많은 분야와 여러 AI 대회에서 Transformer를 사용하는 경우는 이제 너무나 흔한 일이 되었다. 그만큼 Self-Attention을 기반으로 하는 Transformer가 딥 러닝 분야에 막대한 영향을 끼친 breakthrough라고 말해도 과언이 아니다. 그러나 과연 Transformer를 어떠한 경우에서든 상관없이 무작정 사용하는 것이 바람직한가에 관해서 의문이 들 수 있다. Transformer라고 항상 만능이 아니므로 모델을 사용할 목적과 환경을 고려해야 할 필요가 있으며, 특히 데이터의 상태와 양에 따라 Transformer의 효율이 좋을 수도 있고 나쁠 수도 있다. 이번 글에서는 Transformer를 어떠한 문제와 용도에서 사용할 때 바람직한지를 알아보고, 그렇지 않다면 transformer를 사용하기 위해 어떻게 문제를 극복했는지를 살펴보고자 한다.
Transformer 사용을 재고해야 할 필요가 있는 경우
Transformer는 다양한 sequence data에 있어서 강점을 보이지만, self-attention을 수행하는 과정에서 다른 모델에 비해 상대적으로 많은 양의 데이터와 연산량을 요구한다.
그래서 어떠한 케이스에 상관없이 무조건적으로 Transformer를 택하여 사용하는 건 바람직하지 않을 수 있고, 사용자가 고려하는 목표와 주어진 환경을 종합적으로 고려할 필요가 있다.
Feature를 가지고 하나의 Sequence로 만드는 것이 어려운 경우
예를 들어, 주어진 데이터의 feature의 순서가 중요하지 않아서 이를 하나의 sequence로 묶기 어려운 경우가 존재한다.
이때 feature 사이에 관계를 찾는 것이 어려워서 Transformer의 입력 데이터를 어떻게 만들어서 주는 것이 효율적인지 답을 찾기 힘들 수 있다.
그러나 아래에서 설명하겠지만, sequence로 주어지는 데이터에서 각 token의 순서가 중요하지 않은 경우에는 feature vector를 적절히 embedding 하여 하나의 sequence 데이터로 구성할 수 있다.
Feature와 Label의 수가 데이터에 비해 너무 많은 경우
또한 feature의 수와 예측해야 하는 label의 수가 너무 많은 데 반해 학습으로 주어지는 데이터의 양이 많지 않으면 Transformer가 오히려 더 불리할 수 있다.
Transformer는 귀납편향(inductive bias)이 CNN 등 다른 모델보다는 약해서 데이터에서 다양한 특징을 좀 더 global하게 뽑아내서 feature embedding을 할 수 있지만, 이를 위해 데이터 자체가 많이 필요하다.
여기서 귀납편향이란 학습 과정에서 보지 못한 데이터에 관해 모델이 정확한 예측을 하고자 사용하는 추가적인 가정이라고 볼 수 있다. 쉽게 설명하자면, 머신러닝에서 모든 데이터에 관하여 입력이 주어질 때 출력을 예측할 수 있는 approximate function이 존재한다고 가정하자.
모델이 새로운 데이터에 관해 좀 더 다양하고 많은 approximate function의 후보를 고려하면 inductive bias가 약하고, 반대로 좀 더 그럴 듯하지만 적은 approximate function 후보를 고려하면 inductive bias가 강하다고 말할 수 있다.
Kernel을 이동해 가면서 locality를 주로 학습하는 CNN과는 달리, Transformer는 self-attention을 통해 각 token이 모든 token을 고려하게 되므로 global한 특징을 파악하지만 inductive bias는 상대적으로 약하다고 볼 수 있다.
Inductive Bias에 관한 자세한 내용은 아래 글을 참고하면서 이해할 수 있었다.
[머신러닝/딥러닝] Inductive Bias란?
Inductive Bias란 무엇일까요? 최근 논문들을 보면 그냥 Bias도 아니고 inductive Bias라는 말이 자주 나오는 것을 확인할 수 있는데요! 오늘은 해당 개념에 대해 정리해보는 시간을 가지려고 합니다.
velog.io
그래서 데이터의 수보다 feature 수가 더 많으면 이를 축소할 필요가 있으며, 많은 feature를 충분히 설명할 수 있는 대표적인 feature를 뽑아서 학습을 수행하거나, PCA(Primary Component Analysis)를 통해 feature 개수를 줄일 수도 있다.
또한 도메인 지식과 가설을 바탕으로 바람직한 feature engineering을 통해 일부 feature를 없애거나 통합하여 적절한 수의 feature로 변환하는 방법도 있다.
참고로 이러한 Transformer의 특성은 일반적으로 feature를 많이 요구하는 LGBM(Light Gradient Boosting Machine)과는 다른 양상을 보인다는 것을 알 수 있다.
Sequence 길이가 너무 긴 경우
Sequence의 길이가 길어지면 Transformer의 Self-attention을 사용하는 과정에서 데이터의 양이 증가함에 따라 시간복잡도(time complexity)가 증가한다는 단점이 있다.
예를 들어, sequence의 길이가 $n$이고 임베딩 차원이 $d$이면 시간복잡도가 $O(n^2 \cdot d)$인데, 이는 sequence가 길어질수록 복잡도가 제곱에 비례하여 커진다는 것이다.
그래서 주어진 resource를 고려하여 두 개의 token을 묶어서 하나의 token으로 만들어 모델을 학습하는 방법이 있으며, 이는 아래에서 자세히 설명할 것이다.
Transformer가 가지는 장점
위와 같은 문제점이 존재하지만 그럼에도 Transformer가 많이 쓰이고 대다수의 경우에서 좋은 성능을 발휘하는 이유는 바로 Transformer가 지니는 이점을 무시할 수 없어서다.
Sequence 안의 각 token이 다른 token을 모두 참조한다.
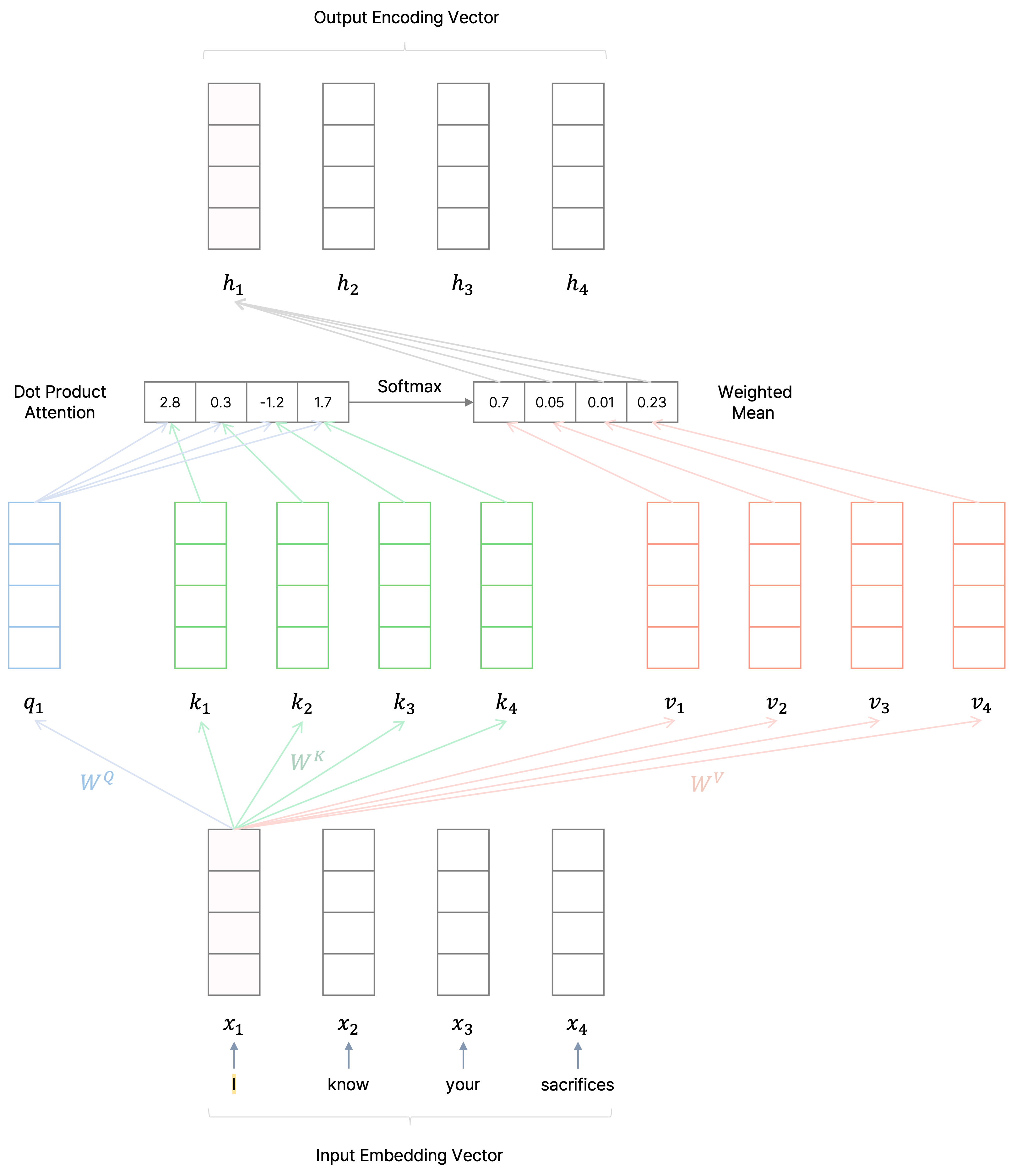
Transformer는 sequence로 주어진 input 데이터에서 각각의 모든 token이 다른 token을 참조하며, sequence 앞쪽 또는 뒤쪽의 token에 관해서 self-attention을 적용할 때도 병목 현상없이 병렬적으로 전반적인 데이터를 보고 학습을 수행할 수 있다는 장점이 있다.
Sequence의 순서 정보를 반영할 수 있다.
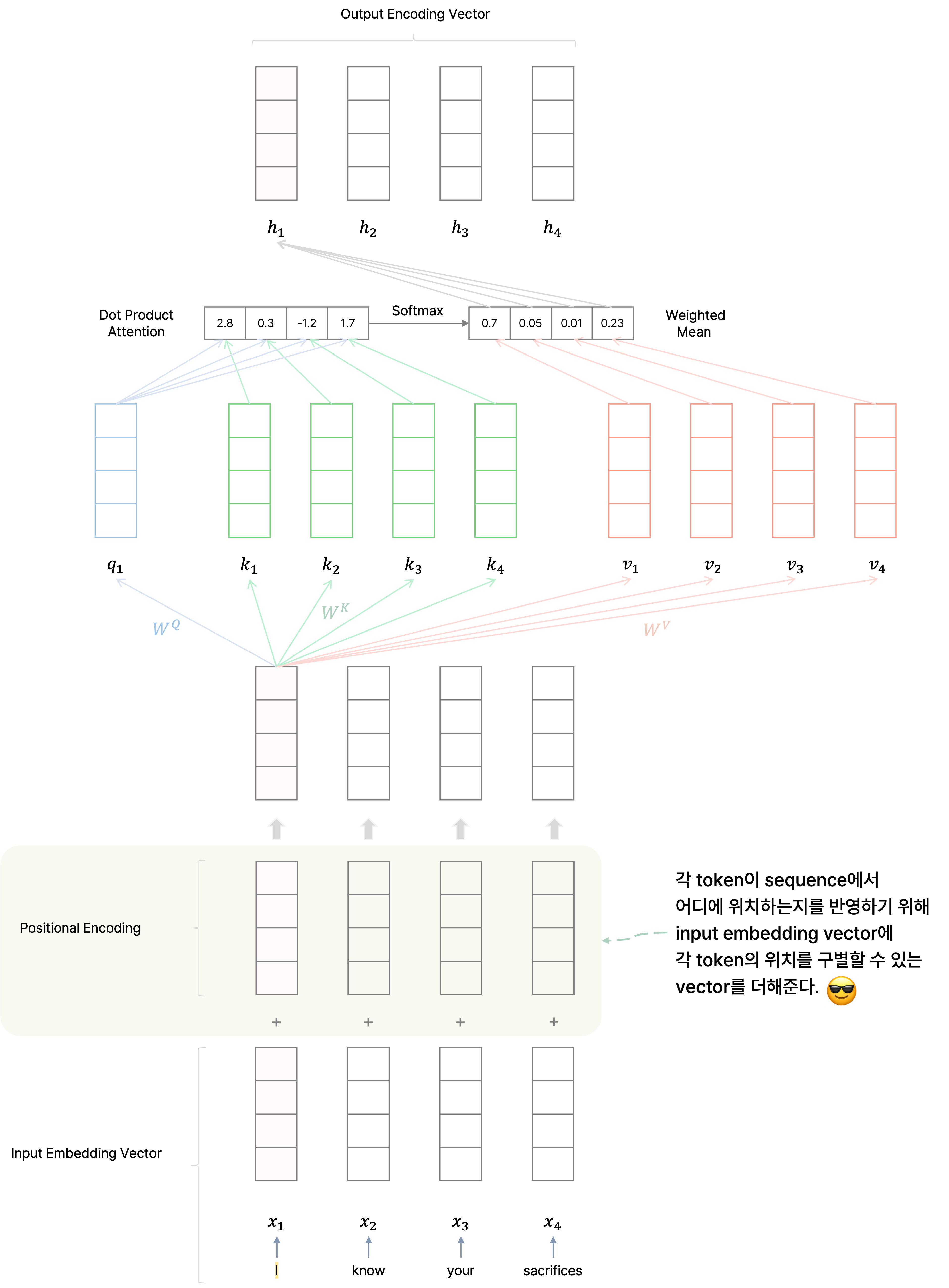
기본적으로 Transformer는 순차적으로 token에 관해 임베딩 벡터를 학습하지 않고 self-attention을 통해 모든 token을 참조하면서 병렬적으로 학습을 수행하므로 순서 정보를 학습할 수 없다.
그러나 sequence에서 각 token이 어떠한 위치에 있는지에 관한 정보를 positional encoding을 통해 input data에 적용하여 sequence의 순서까지 학습할 수 있다.
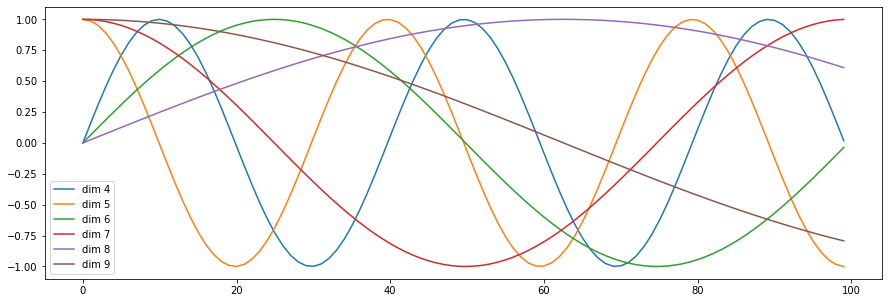
Attention is All You Need 논문에서는 각 차원마다 서로 다른 주기의 sin, cos 함숫값을 더하여 token마다 서로 다른 positional embedding을 지니도록 했으며, 더 나아가 아예 positional embedding을 학습 파라미터로 두어서 end-to-end로 학습하는 시도도 있다.
Transformer의 변형
이처럼 무시할 수 없는 장점으로 인해 아직까지도 많은 연구와 개발에서 Transformer를 사용하는 사례는 적지 않으며, Transformer의 장점을 살리고 단점과 한계를 극복하기 위해 Transformer를 tuning 하는 사례도 종종 볼 수 있다.
예를 들어 보다 작은 구조를 사용해야 하는 경우, 대회 플랫폼에서 inference time이나 메모리에 제약이 걸리는 경우, 적용하려는 task에 맞게 pre-trained 모델을 변형을 해야 하는 경우 등 여러 상황에서 Transformer를 변형해야 필요성이 있다.
특히 Transformer에서 encoder 부분을 잘 활용하고 변형하여 여러 task에서 높은 성과를 얻는 경우가 종종 있다.
반드시 Sequence 데이터의 순서를 학습할 필요가 없다
Sequence data 내에서 각 token의 위치가 중요한 경우도 존재하지만, 그렇지 않은 경우도 존재한다.
예를 들어, sequence의 순서가 무작위로 변경된다고 해도 결과는 똑같이 나와야하는 경우가 존재한다.
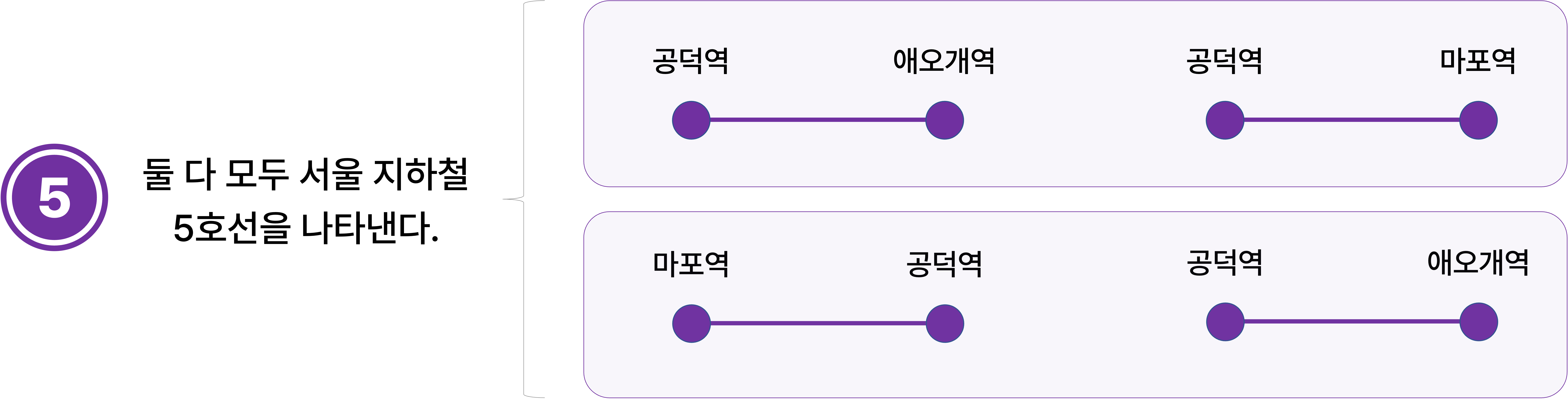
지하철 노선을 나타내는 데이터가 노선 위에 있는 임의의 인접한 두 역의 쌍으로 주어진다고 한다.
그러면 서울 지하철 5호선은 (공덕역, 애오개역), (공덕역, 마포역)으로 표현할 수 있다.
그렇지만 (마포역, 공덕역), (공덕역, 애오개역)으로 표현된다고 해서 서울 지하철 5호선인 사실이 변하지는 않는다.
만약 주어지는 인접한 두 역의 쌍 하나가 token이라고 가정하면, 이 token이 어떠한 순서로 입력으로 주어지든 간에 Transformer는 같은 결과를 예측해야 한다.
그러나 일반적으로 positional encoding을 수행하면 token이 위치한 정보도 같이 학습을 하므로 이러한 예측 상황에 대처할 만한 좋은 방법이 아니다.
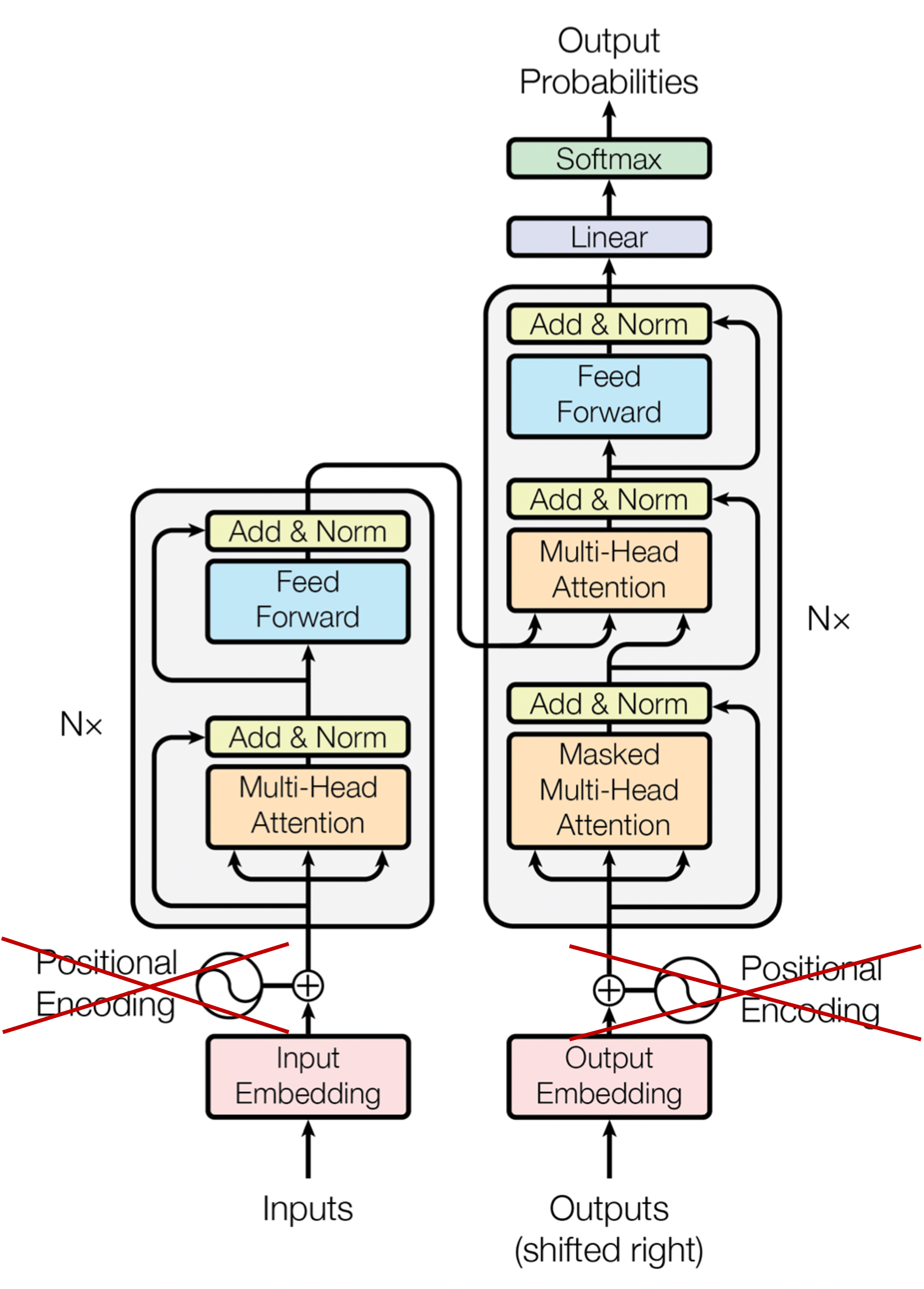
Transformer에서는 모든 token에 관하여 각 token이 다른 token을 참조하는 self-attention이 이루어지므로 근본적으로 순서를 학습하지는 않는다.
다만 순차 데이터에 관한 학습을 수행하고자 일반적으로 positional encoding을 통해 Transformer 모델이 순서도 학습할 수 있도록 하지만, 순서에 상관없이 동일한 결과를 보여줘야 한다면 이 positional encoding을 없애버려도 된다.
그래서 sequence가 어떠한 순서로 주어지더라도 모두 같은 결과를 보여줘야 할 때 Transformer의 positional encoding을 제거하여 이를 해결한 사례가 종종 있다.
Predicting Molecular Properties
Predicting Molecular Properties | Kaggle
www.kaggle.com
대표적으로 분자의 여러 정보들을 통해 원자 간 결합 상수를 찾는 대회에서 우수한 성적을 달성한 solution을 주목할 필요가 있다.
BERT in chemistry - End to End is all you need
Predicting Molecular Properties | Kaggle
www.kaggle.com

[출처] https://www.kaggle.com/c/champs-scalar-coupling, Description in Overview, Predicting Molecular Properties
이 대회에서는 데이터로 주어진 원자 쌍의 순서가 달라져도 그 내용이 같으면 원자 쌍이 이루는 분자는 동일하므로 같은 결과를 출력해야 하는데, 일반적으로 sequential 모델에서는 이를 극복하기가 어렵다.
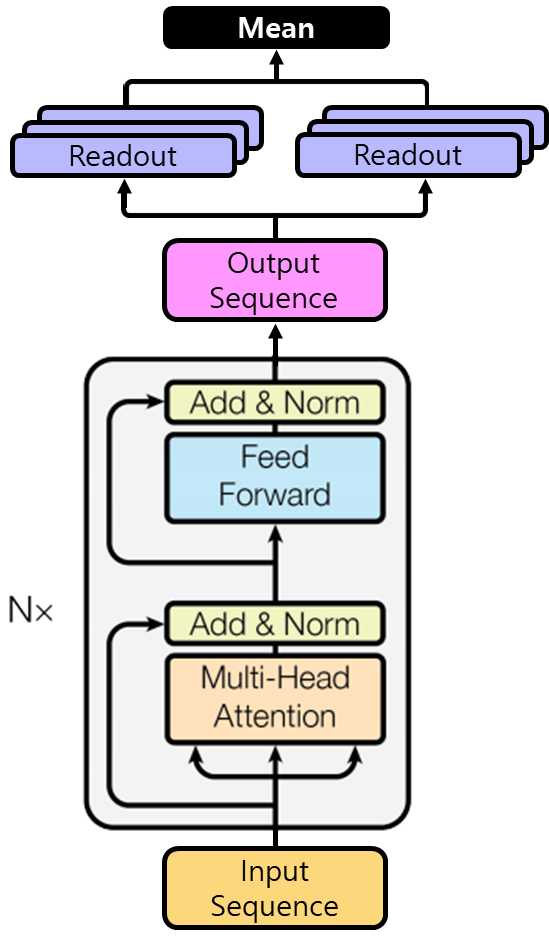
[출처] https://www.kaggle.com/c/champs-scalar-coupling/discussion/106572, YouHan Lee
그래서 Transformer에서 positional encoding을 사용하지 않는 대신에 feature의 vector를 embedding하는 방법에 주목했다.
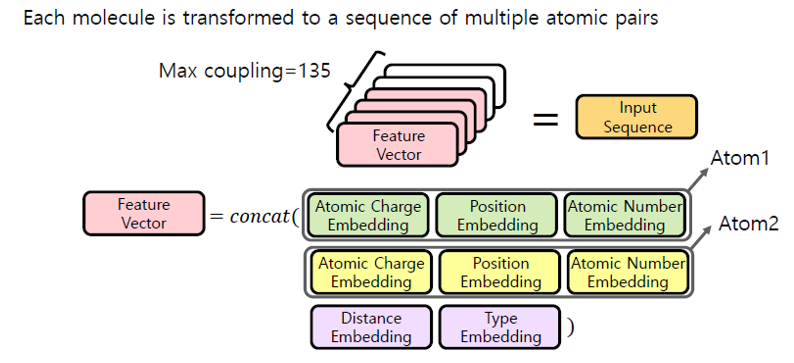
[출처] https://www.kaggle.com/c/champs-scalar-coupling/discussion/106572, YouHan Lee
분자 별로 원자 쌍이 최대 135개이므로, 원자 쌍을 나타내는 각 feature vector를 모아서 135 길이로 고정된 sequence를 input으로 사용할 수 있다.
각 feature vector는 Atom1, Atom2 두 개의 원자 각각의 정보와 두 원자 사이의 관계 정보를 concatenate한 결과이다.
각 원자 정보는 원자의 전하(Atomic Charge Embedding), 위치(Position Embedding), 원자 번호(Atomic Number Embedding)를 임베딩하여 concatenate하여 구성하고, 두 원자의 관계 정보에서는 두 원자 사이의 거리(Distance Embedding)와 결합 종류(Type Embedding)을 concatenate하여 구성한다.
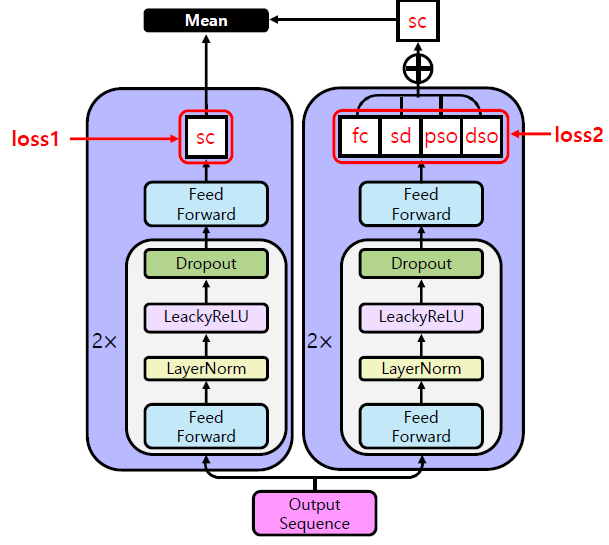
[출처] https://www.kaggle.com/c/champs-scalar-coupling/discussion/106572, YouHan Lee
또한 모델을 두 개 만들어서 한 모델은 최종적으로 예측해야 하는 scaling constant인 sc를 학습하여 예측하고, 다른 모델은 sc를 구성하는 4개의 요소인 fc, sd, pso, dso를 예측한다.
후자의 모델에서는 이 4개의 요소를 concatenate하여 sc를 구하고, 이를 다른 모델에서 구한 sc와 평균을 내서 최종적인 예측 결과로 만들어 제출했다.
이는 여러 모델을 학습하여 좀 더 일반화 성능이 좋은 결과를 기대할 수 있는 앙상블(Ensemble) 기법과 유사하다고 볼 수 있다.
Sequence 길이를 반으로 줄인다.
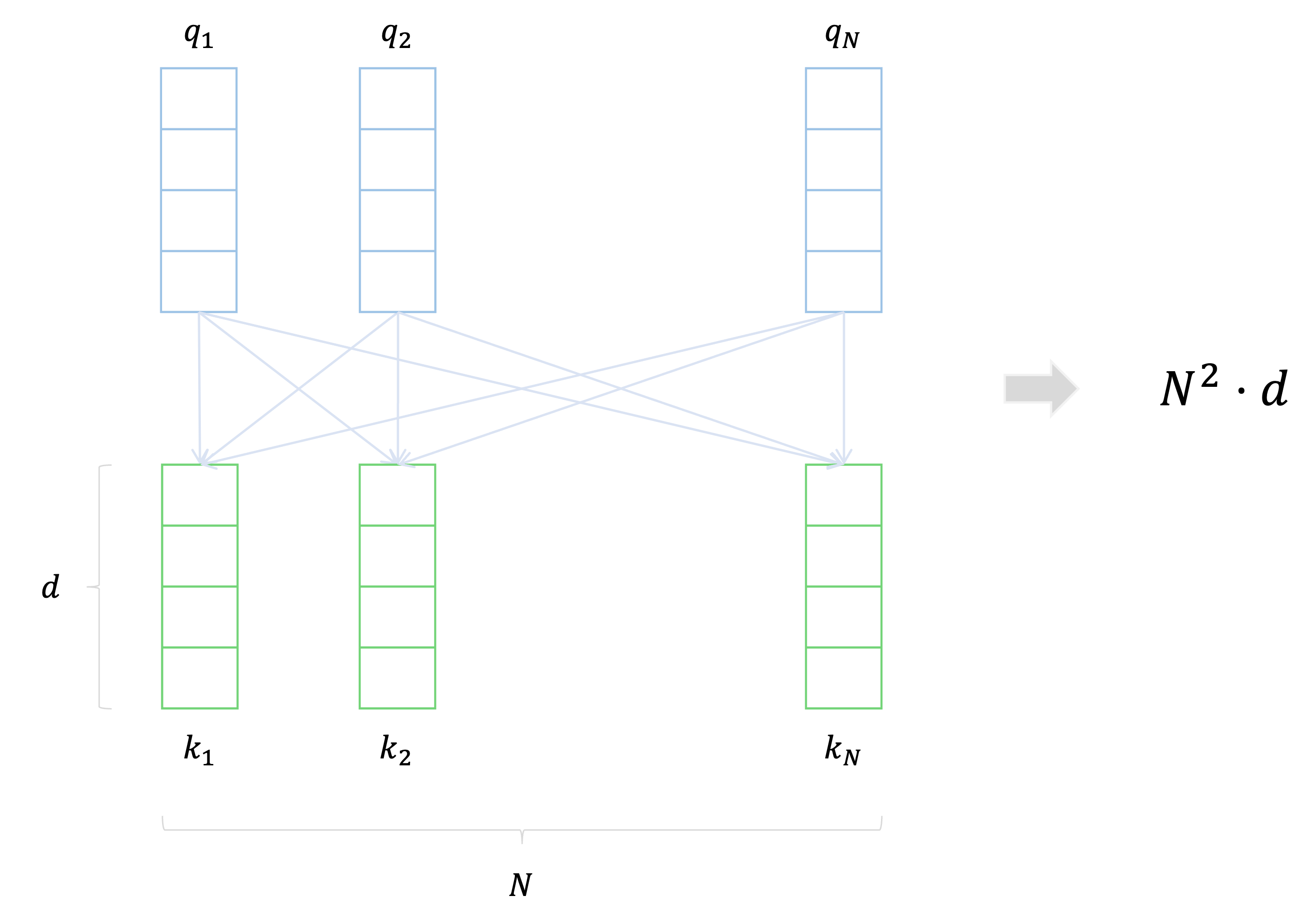
Transformer에서 학습에 사용할 수 있는 데이터의 양이 많으면 많을수록 일반적으로 우수한 일반화 성능을 보이지만, 데이터의 양이 증가함에 따라 time complexity가 증가한다는 단점이 있다.
특히 Transformer에서 Self-Attention을 사용할 때 sequence의 길이가 $n$이고 임베딩 차원이 $d$이면 시간복잡도가 $O(n^2 \cdot d)$이다.
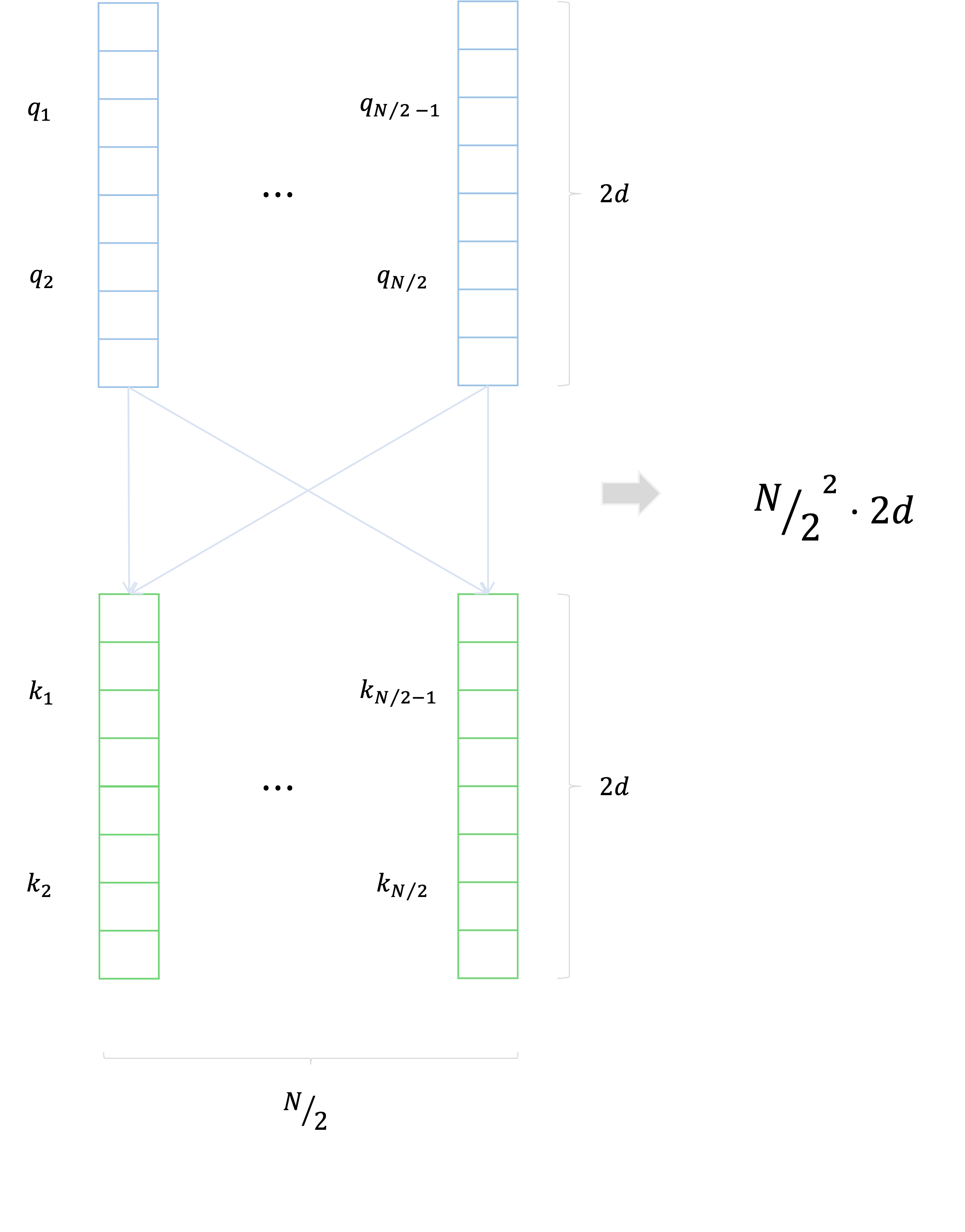
이를 해결하기 위한 방법으로는 임베딩된 두 개의 token을 하나로 이어붙여 sequence의 길이는 반으로 줄이고, 대신에 하나의 임베딩 차원을 두 배로 늘려서 token 당 더 많은 정보를 가지고 학습을 시킬 수 있다.
시간복잡도는 sequence의 길이의 제곱과 임베딩 차원에 비례하므로 결과적으로 시간 복잡도가 이전에 비해 $\frac{1}{2}$배로 감소한다.
마지막 Query만 사용한다.
일반적으로 Transformer는 inductive bias가 약해서 많은 양의 데이터를 요구하지만, 시간복잡도가 sequence의 길이 $N$에 제곱에 비례하므로 사용할 수 있는 자원이 충분치 않다면 Transformer를 사용하는 게 부담이 될 수 있다.
이러한 한계를 극복하고자 사용자의 문제 풀이 이력을 통해 학습 수준을 파악하는 DKT(Deep Knowledge Tracing) task의 Riddi 대회에서 좋은 성과를 보인 solution이 존재하며, 그중 Transformer의 encoder의 마지막 Query만 사용한 Last Query Transformer RNN solution에 주목할 필요가 있다.
여기서 DKT란 어떤 한 사용자가 문제를 푼 이력을 바탕으로 다음 문제를 맞힐지를 예측하는 task이며, 이 대회에서는 모든 위치의 token을 예측하는 것이 아니라 마지막 문제에 관해 사용자가 과연 정답을 맞힐지 틀릴지의 여부를 예측한다.
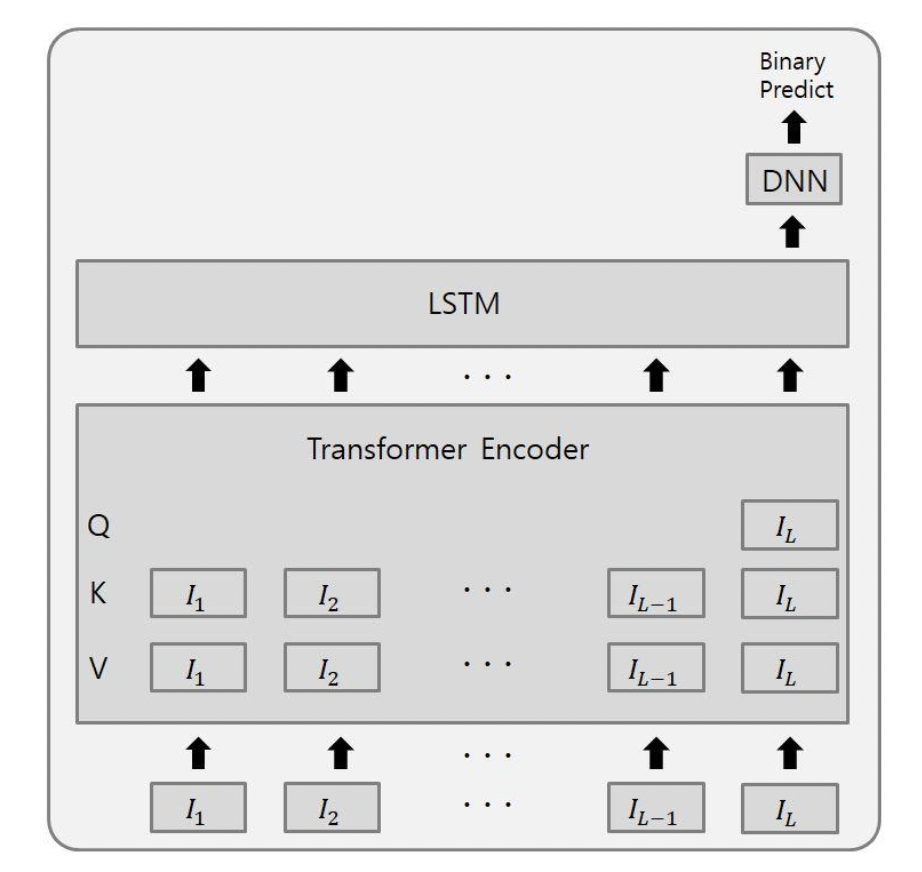
[출처] https://arxiv.org/pdf/2102.05038.pdf, Last Query Transformer RNN for knowledge tracing, SeungKee Jeon
기본적으로 앞단에 positional encoding을 제외한 Transformer encoder를 두어서 사용자가 푼 문제 풀이 이력 token 간의 특징을 파악한다.
이때 encoder에서 self-attention을 통해 각 token의 output vector를 가중 평균하지 않고 이를 그대로 LSTM의 input으로 넣는다.
LSTM에서는 문제를 푼 이력인 sequence의 순차 정보를 뽑아내고, 마지막의 hidden state vector에서 DNN을 통해 sequence별로 마지막으로 주어진 문제를 사용자가 맞힐지 여부를 예측한다.
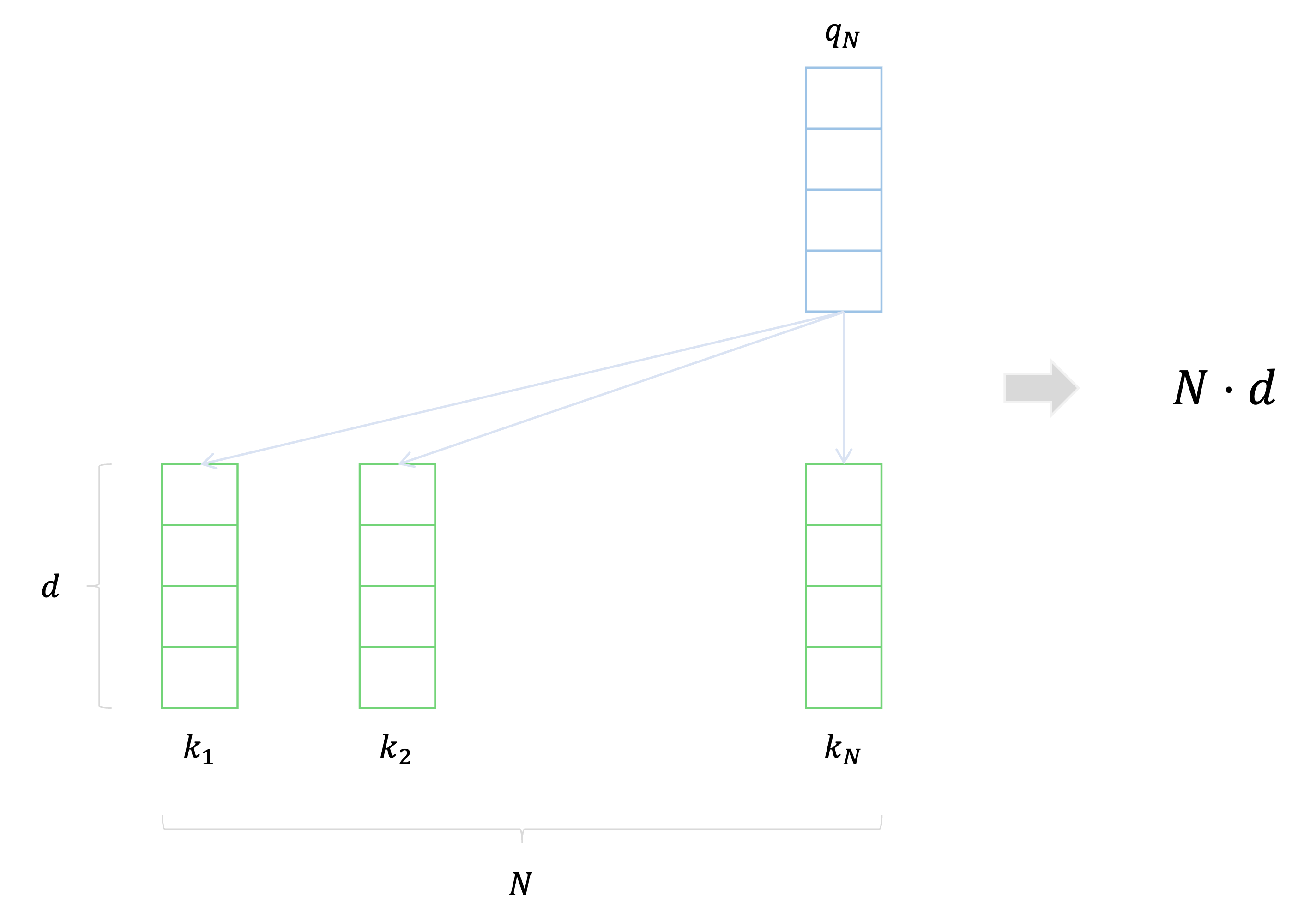
이 solution의 가장 큰 특징은 바로 Transformer의 encoder에서 마지막 token에 해당하는 query만 사용했다는 것이다.
그러면 모든 각각의 token에 관해 다른 모든 key token과 내적을 구하지 않고 오직 마지막 token의 query vector에 관해서만 수행하므로 시간복잡도가 기존의 $O(L^2d)$에서 $O(Ld)$로 줄어든다.
이는 사실 이 대회에서의 DKT task의 의미를 분석하면 합리적인 solution이라고 해석할 수 있는데, 이번 task에서는 마지막 문제에 관해서만 정답 여부를 예측하는 것이므로 마지막 문제가 앞서 어떠한 token에 좀 더 주의를 기울이는지를 아는 것이 중요하다.
그러므로 모든 token의 query vector를 사용하는 것보다는 시간복잡도도 줄일 수 있고 대회의 최종 목표에 좀 더 가깝다고 볼 수 있는 마지막 query만을 이용하는 것만으로도 task 수행 목적만을 고려했을 때 좋은 결과를 낼 수 있다고 볼 수 있다.
추가로 사용자가 문제를 어떠한 순서로 풀었고 틀렸는지에 관한 정보도 학습하고자 단순히 Transformer 뿐만이 아니라 LSTM도 같이 사용하여 순차 정보도 학습할 수 있도록 한 점도 주목할 만하다.
Transformer를 사용하지 않은 경우
1D-CNN를 사용한다.
앞서 언급한 feature와 label 수에 비해 주어진 데이터가 부족한 경우에서의 문제점을 CNN(Convolutional Neural Network)로 극복한 사례가 있는데, 대표적으로 MoA(Mechanisms of Actions) 대회에서 좋은 성과를 보인 solution 중 하나이다.
https://www.kaggle.com/c/lish-moa/discussion/202256
Mechanisms of Action (MoA) Prediction | Kaggle
www.kaggle.com
MoA는 약물을 투여했을 때 데이터의 여러 특징에 따라 200여 개의 화학 반응 중 어떤 반응이 나타날지를 예측하는 task를 수행해야 하는데, 다음과 같은 한계로 인해 Transformer가 제대로 작동하지 않았다고 한다.
- 주어진 데이터를 Sequence로 묶기가 어렵다.
- 학습 데이터에서 사람에게 투여한 약물에 관한 정보와 그 약을 투여 받은 사람의 정보를 같이 학습하는데, 이 둘 사이의 정보는 사실상 연관관계가 없다. 앞서 설명한 분자의 예시에서는 분자를 구성하는 임의의 두 원자 각각의 정보와 두 원자가 어떻게 결합했는지에 관한 정보는 서로 연관되어 분자를 대표한다고 볼 수 있지만, 이 대회에서는 약물 정보와 약물을 투여 받은 사람의 정보를 연관짓기에는 어려움이 존재한다.
- Feature의 수가 너무 많다.
- 학습할 데이터의 feature 수가 875개에 달하는데, 이는 약 24,000개의 데이터에 비해 데이터를 표현하는 feature의 수가 너무 많아 과적합 문제를 발생할 가능성이 있다.
- 데이터에 비해 예측해야 할 클래스가 많다.
- 어떤 반응이 나타나는지를 예측해야 하는 클래스 수가 207개였는데, 이 또한 클래스를 매우 세분화하여 예측해야 하므로 학습이 제대로 되지 않거나 또는 과적합이 이루어질 가능성이 있다.
그래서 이 대회에서 좋은 성적을 보인 아래의 solution에서는 1D-CNN을 사용하는 방법을 택했다.
Mechanisms of Action (MoA) Prediction | Kaggle
www.kaggle.com
먼저 약물을 투여받는 사람의 feature와 세포 생존 정보에 관한 feature를 각각 PCA를 통해 50차원과 15차원의 vector로 embedding했다.
이를 기존의 feature에 concatenate하여 새로운 feature embedding vector로 만들었다.
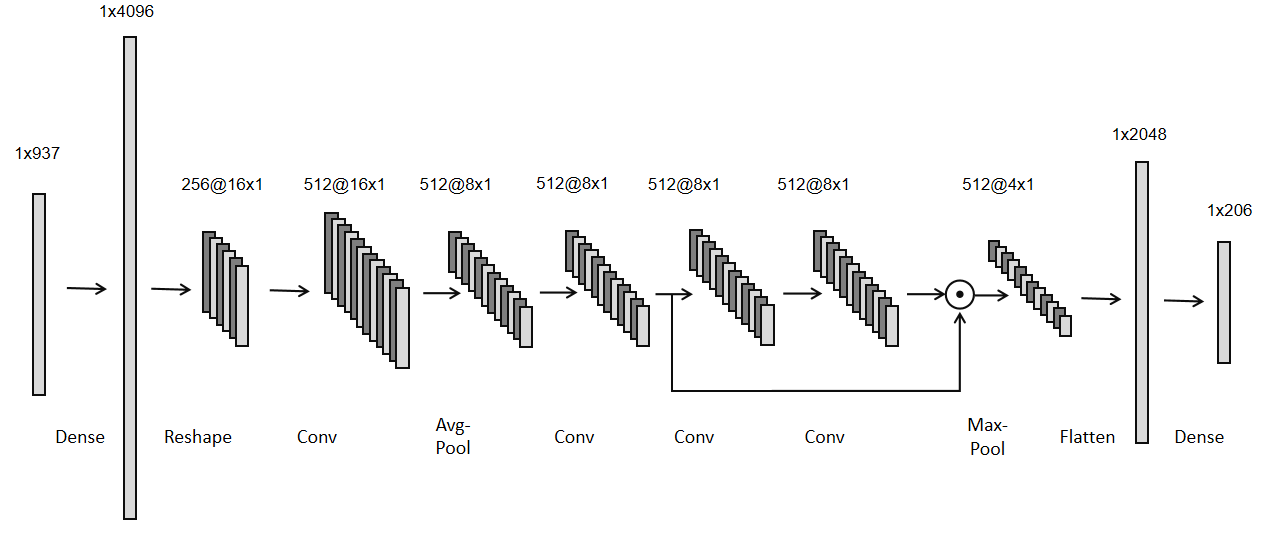
[출처] https://www.kaggle.com/c/lish-moa/discussion/202256, tmp
이후 데이터를 1차원의 배열 형태로 사용하고자 linear layer를 거치게 했는데, 이는 CNN를 사용하면서 이미지처럼 데이터를 활용하고자 데이터의 차원을 늘려서 충분히 많은 양의 pixel을 만들어 주기 위함이라고 볼 수 있다.
또한 생성된 데이터 안에서 feature가 정렬되는 효과를 줄 수 있으며, linear layer가 fully connected로 구현되면서 각 벡터의 원소가 가지는 의미를 동일하게 만들어 준다.
이후 짧은 길이의 여러 채널을 지니는 1차원 배열의 데이터로 변환하여 convolution 1D layer를 통과하면서 결과를 생성했다.
이는 sequence data 자체를 이미지 데이터처럼 고려하여 CNN에서 커널을 이동하면서 하는 것처럼 학습시킬 수 있음을 보여준다.
정리하자면 항상 Transformer가 만능은 아니며, 해결해야 할 task와 주어진 데이터의 특성에 맞게 적재적소로 변형하거나 효율적인 모델을 사용하는 것이 중요하다.
개인적으로 이러한 이유로 인해 너무 한 모델에만 매몰되지 않고 다양한 모델을 사용해보면서 여러 task를 경험해 보는 것이 AI를 공부하는 데 있어서 중요하다는 생각을 가지게 된다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech NLP Track 주재걸 교수님 기초 강의
2. 네이버 커넥트재단 부스트캠프 AI Tech RecSys Track 이영수 마스터님 DKT 대회 강의
'AI > AI 기본' 카테고리의 다른 글
| Transformer의 Multi-Head Attention과 Transformer에서 쓰인 다양한 기법 (4) | 2023.04.11 |
|---|---|
| [인공지능 기초] Adversarial Search - Minimax Search와 Alpha-beta Pruning (0) | 2022.10.09 |
| Transformer의 Self Attention에 관한 소개와 Seq2Seq with Attention 모델과의 비교 (0) | 2022.07.23 |
| Attention 기법을 사용한 Seq2Seq with Attention (0) | 2022.07.14 |
| 생성 모델(Generative Model)과 VAE 그리고 GAN (1) | 2022.02.17 |
Contents
소중한 공감 감사합니다.