AI/NLP
Zero-shot Learning이 가능한 GPT-2와 Few-shot Learning의 가능성을 제시한 GPT-3
- -
GPT-2
GPT-2를 살펴보기 전에 먼저 이전에 올렸던 GPT-1과 self-supervised learning의 설명을 기반으로 하므로 아래의 글을 참고하는 것을 추천한다.
Self-Supervised Model인 GPT-1과 BERT 분석 및 비교
Self-Supervised Pre-Training Model 이번 포스팅에서는 이전에 설명한 transformer의 self-attention block을 기반으로 하는 대표적인 self-supervised pre-training model인 GPT-1과 BERT에 관해 알아보고자 한..
glanceyes.tistory.com
GPT-2의 특징
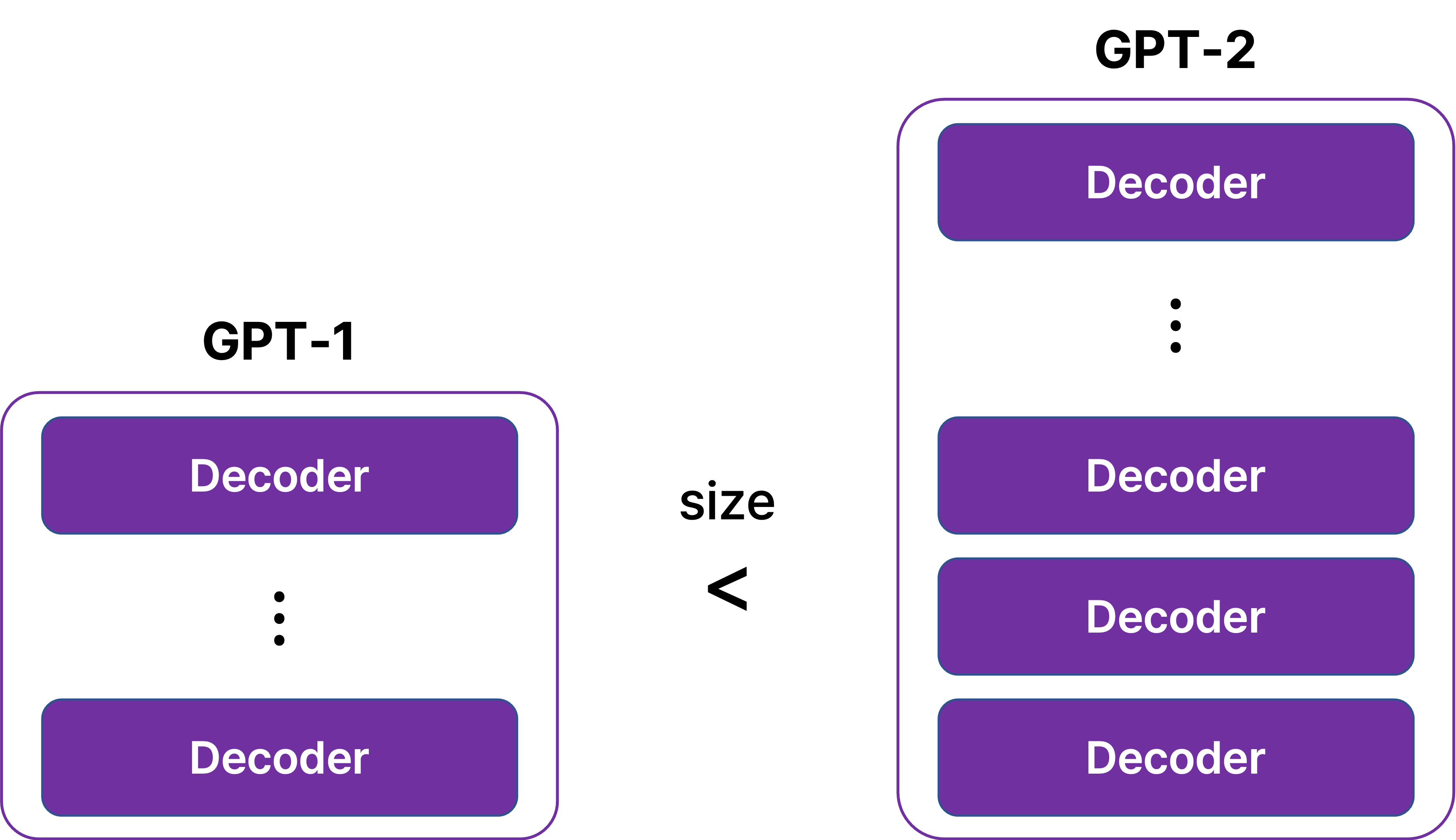
GPT-2는 모델 구조 면에서는 GPT-1과 큰 차이가 없지만, transformer에서 decoder에 해당되는 layer를 GPT-1보다 더 깊게 쌓아서 크기를 키웠다.
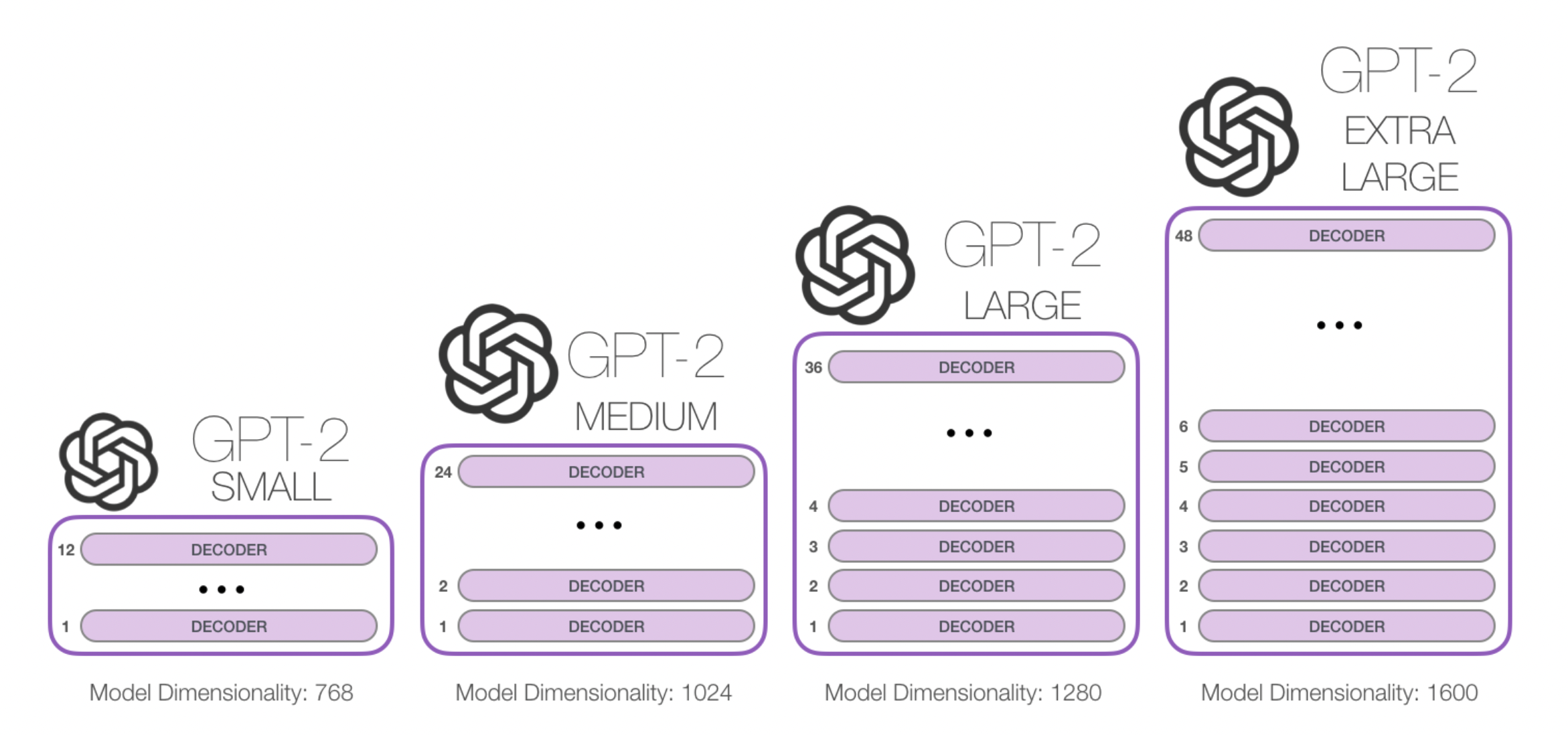
[출처] https://jalammar.github.io/illustrated-gpt2, Alammar, J (2018)
또한 이 decoder를 쌓은 개수와 파라미터 차원의 수 등 모델의 크기에 따라 small, medium, large, extra large의 네 가지 GPT-2 버전을 사용할 수 있다.

[출처] https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf, Language Models are Unsupervised Multitask Learners
또한 GPT-1과 마찬가지로 pre-training task로서 다음에 올 단어를 예측하는 language modeling task를 사용하며, GPT-2는 pre-training 과정에서 GPT-1보다 더 큰 40GB 용량의 WebText라고 일컫는 데이터셋을 학습했다.
주목할 점은 흔한 출처라는 이유로 인해 위키피디아의 모든 문서를 사용하지 않는 등 좋은 품질의 대용량 데이터셋을 학습 과정에 사용하려는 흔적이 보이는데, 이는 좀 더 잘 쓰인 텍스트로부터 다양한 지식을 효과적으로 학습하고자 한 노력의 일환이다.
[출처] https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf, Improving Language Understanding by Generative Pre-Training
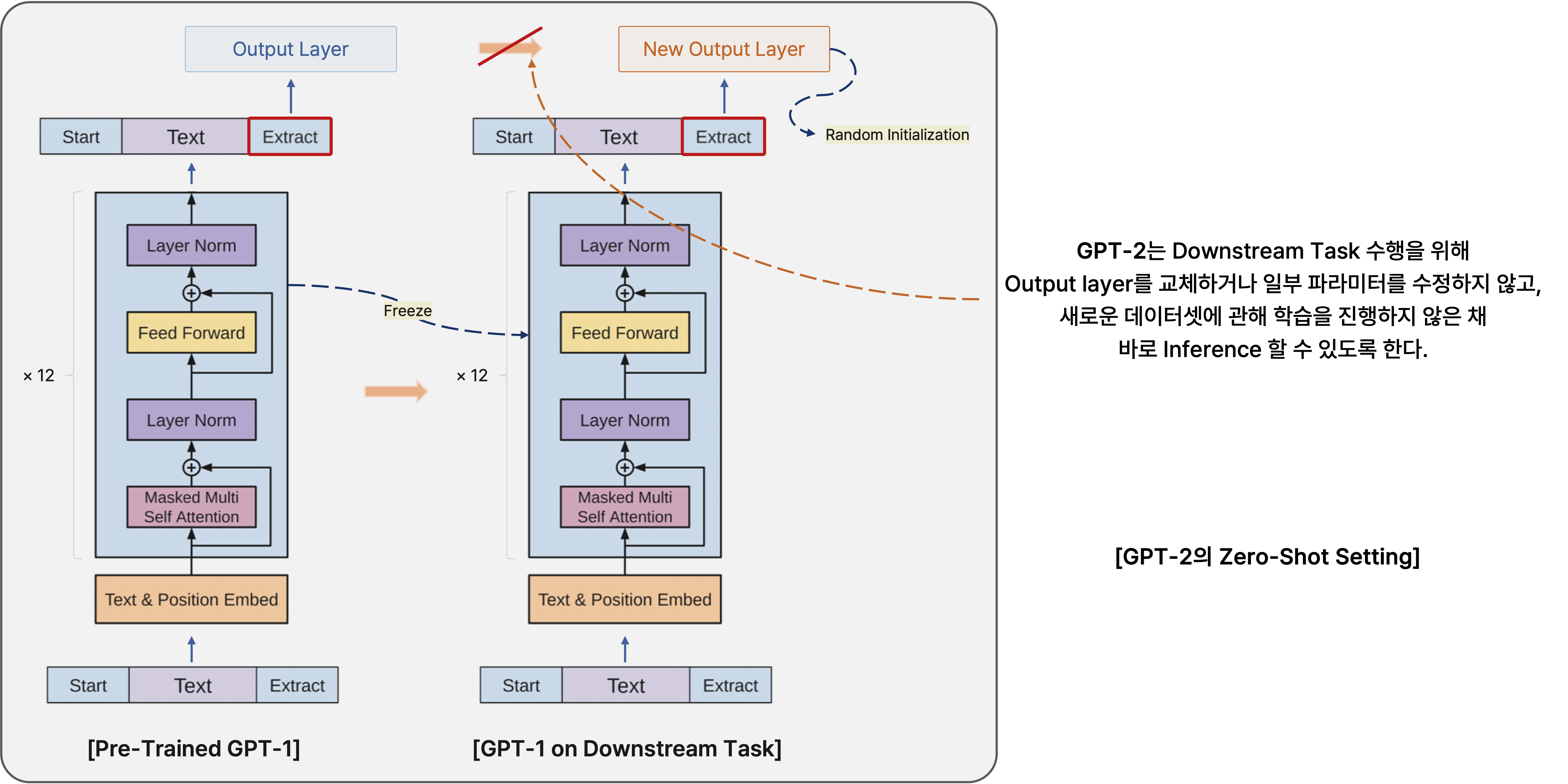
그리고 이 language model을 사용할 때 일부 파라미터나 구조의 수정 없이 여러 down-stream task가 zero-shot setting일 때도 수행될 수 있는 의의를 지니고 있다.
놓치지 말아야 할 점은 GPT-2는 GPT-1처럼 기본적으로 다음에 올 단어를 예측하는 language modeling task로 기학습되므로, 어떠한 지문이 주어졌을 때 이후 다음에 등장할 단어를 예측하면서 어떤 내용을 지니는 글을 서술해 나갈 수 있다는 것이다.
DecaNLP
[출처] https://arxiv.org/pdf/1806.08730.pdf, The Natural Language Decathlon: Multitask Learning as Question Answering
DecaNLP로 불리는 'The Natural Language Decathlon: Multitask Learning as Question Answering'는 GPT-2에 영향을 준 논문이다.
이는 GPT-2에서 다양한 downstream task를 위해 모델 구조 또는 파라미터를 일부 수정하지 않더라도 다음에 올 단어를 예측하여 생성하는 task만으로도 감정 분석, entailment 등 새로운 여러 task를 수행할 수 있는 아이디어를 제공했다.
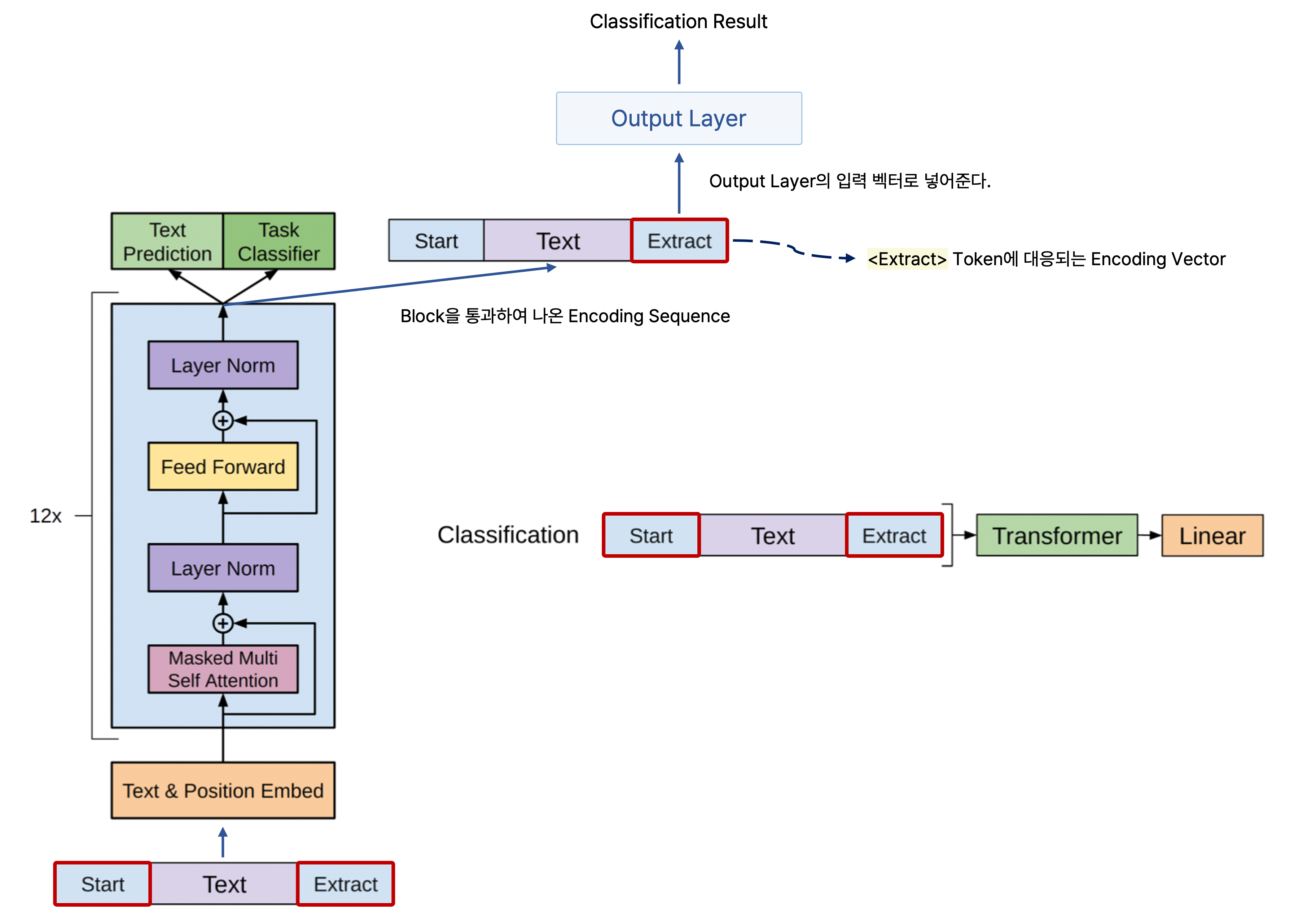
원래 GPT-1에서는 주어진 문장이 긍정인지 부정인지를 예측할 때는 주어진 문장을 인코딩하고, 여기서 <CLS> token을 사용하여 binary classification을 수행한다.
또한 downstream task 중 하나로서 어떤 문장이 주어졌을 때 대답으로 올 수 있는 바람직한 문장을 생성하는 task도 존재하는데, 이는 앞서 문장에 관해 긍정 또는 부정을 예측하는 task와 비교할 때 output의 형태가 다르므로 딥 러닝 모델 관점에서 모델 구조가 상이하다.
그렇지만 이 논문에서는 모든 종류의 자연어 처리에 관한 task들이 다음에 올 단어를 예측하여 생성하는 방식을 통해 질의응답을 예측하는 task의 형태로 바뀔 수 있다는 아이디어를 바탕으로 다양한 task를 통합하여 학습을 수행할 수 있는 방법을 제시했다.
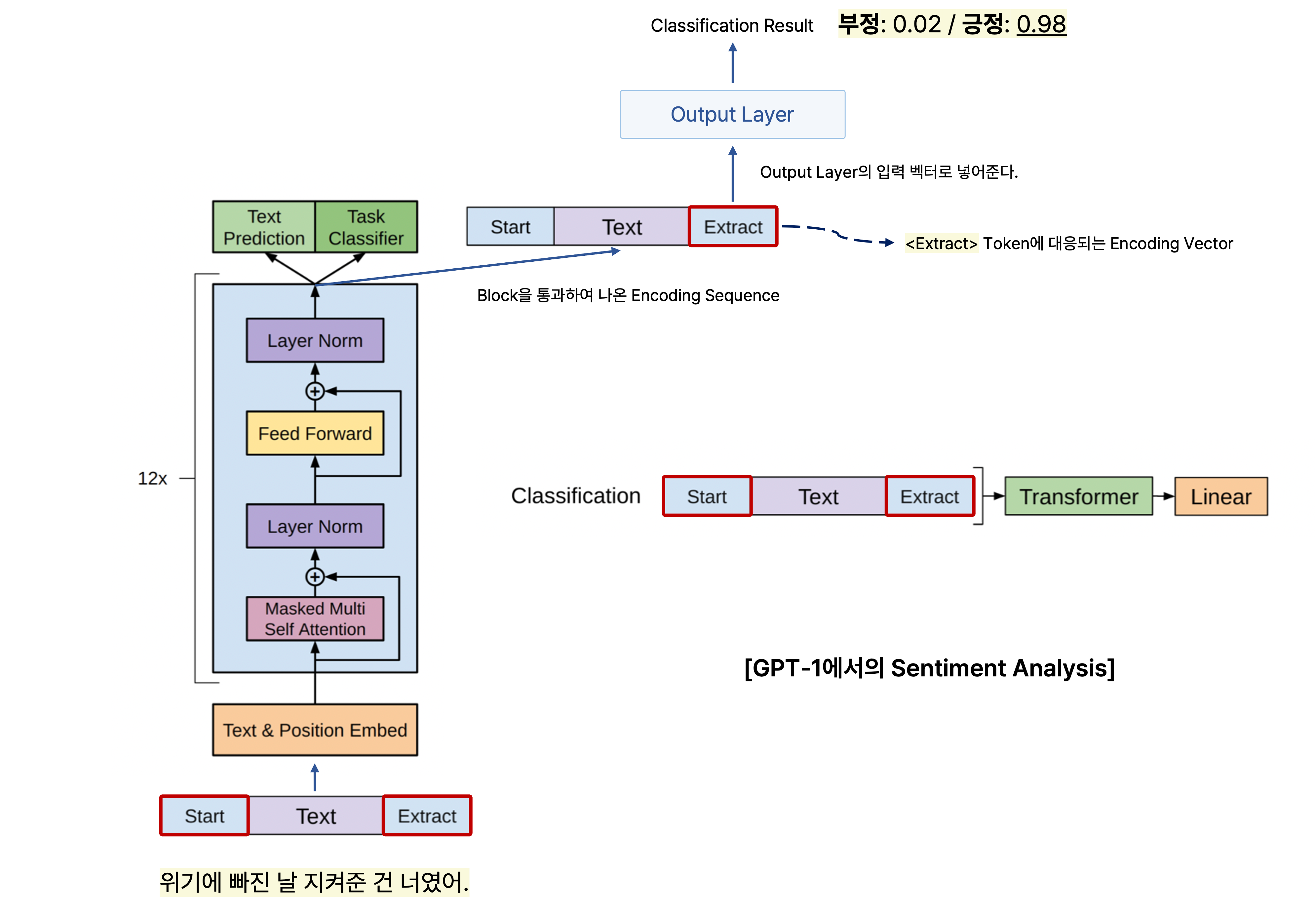
예를 들어, "위기에 빠진 날 지켜준 건 너였어."라는 문장에 관해 긍정 또는 부정을 예측하는 task를 수행한다고 가정한다.
기존의 GPT-1 또는 BERT에서 pre-training task처럼 해당 문장을 인코딩하고, 인코딩한 문장에서 <Extract> 또는<CLS> token을 사용하여 문장에 관한 긍정 또는 부정을 예측할 수 있다.
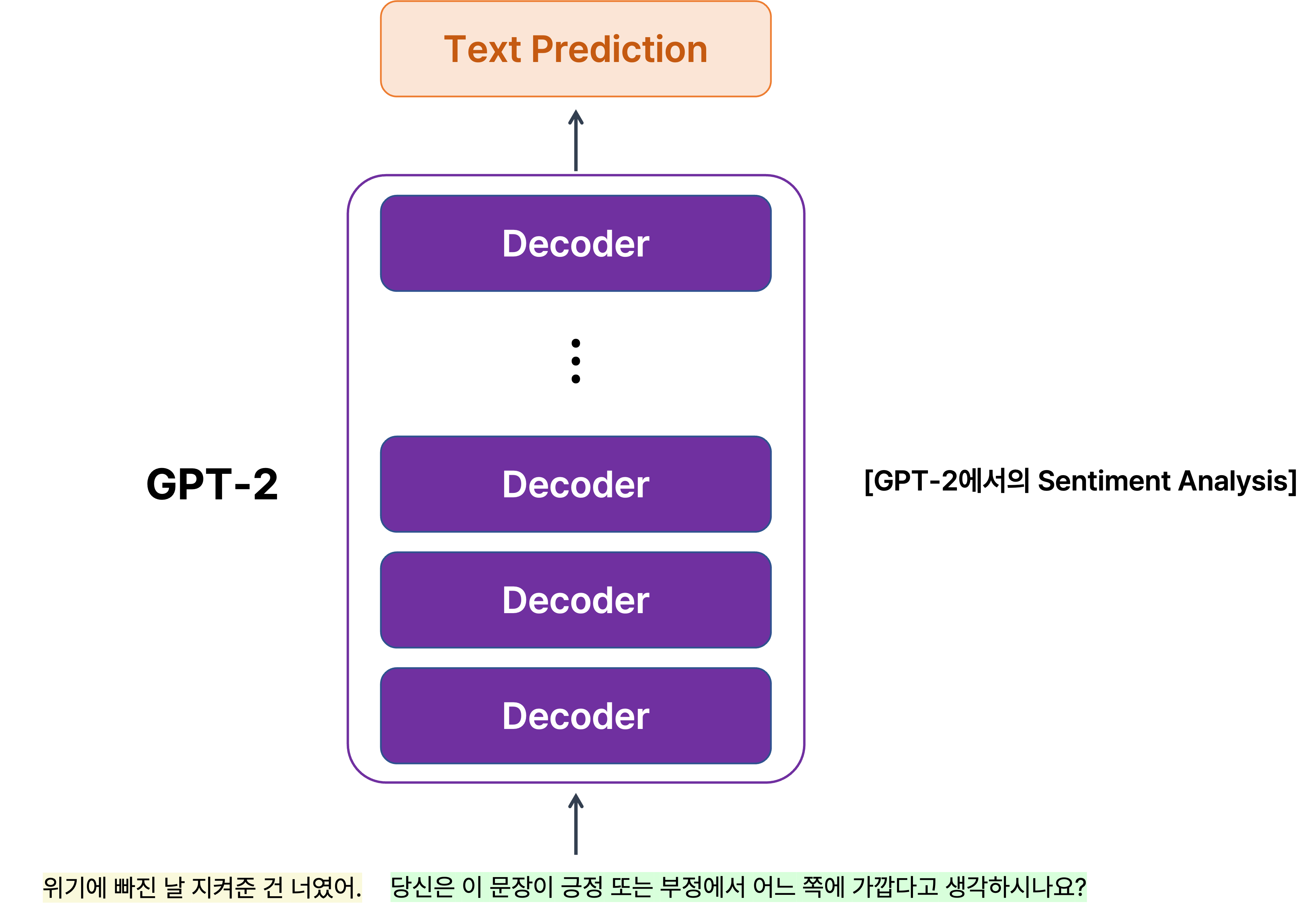
그러나 이 논문에서 제안한 방법은 위의 문장을 준 후 "당신은 이 문장이 긍정 또는 부정에서 어느 쪽에 가깝다고 생각하시나요?"라는 질문을 다음 문장으로 새로 던지고 그 다음에 올 답변을 예측하도록 하여 language model task와 동시에 자연스럽게 긍정 또는 부정을 예측하는 task도 수행할 수 있도록 하는 것이다.
또한 어떠한 텍스트를 요약하는 task에서는 주어진 문단에 관해서 마지막에 "이 문단을 어떻게 요약할 수 있을까요?"라는 문장을 추가하여 다음 문장을 예측하면서 동시에 문단에 관한 요약을 생성하도록 한다.
그리고 번역 task에서도 유사하게 주어진 텍스트 뒤에 "이 문장을 영어로 번역하면 어떻게 될까요?"라는 문장을 추가하여 번역된 문장을 생성할 수 있게끔 한다.
즉, 별도의 모델 구조 변형 없이 다음에 올 단어를 예측하는 language modeling만으로 감정 분석, 요약, 번역 등 다양한 down-stream task를 수행할 수 있는 것이다.
그래서 GPT-2에서는 이처럼 다양한 task를 자연어 생성의 형태를 지니는 질의응답 task로 통합할 수 있는 방법에서 영감을 얻어 고품질의 데이터셋을 만들었다.
특히 많은 질의응답이 오고 가는 플랫폼인 Reddit이라는 커뮤니티에서 데이터를 수집했는데, 질의응답에 첨부된 링크도 데이터셋으로 사용했다.
일례로 어떠한 질문에 관한 답변에서 외부 링크를 첨부한 reply가 존재하고 사용자로부터 3개 이상의 추천(karma)를 받았을 때, 이 외부 링크에 있는 텍스트가 해당 질문에 관해 좋은 정보를 제공하는 글일 가능성이 높다고 판단하여 외부 링크의 글도 학습 데이터로 활용한 것이다.
또한 BERT에서의 WordPiecec처럼 sub-word level에서의 word embedding인 byte pair encoding을 사용했다.
GPT-2의 모델 구조
모델 관점에서 분석해 보면 첫 번째로 layer normalization이 각각의 sub-block의 input 부분으로 이동했고, 추가적인 layer normalization이 마지막 self-attention block의 뒤에 추가되었다.
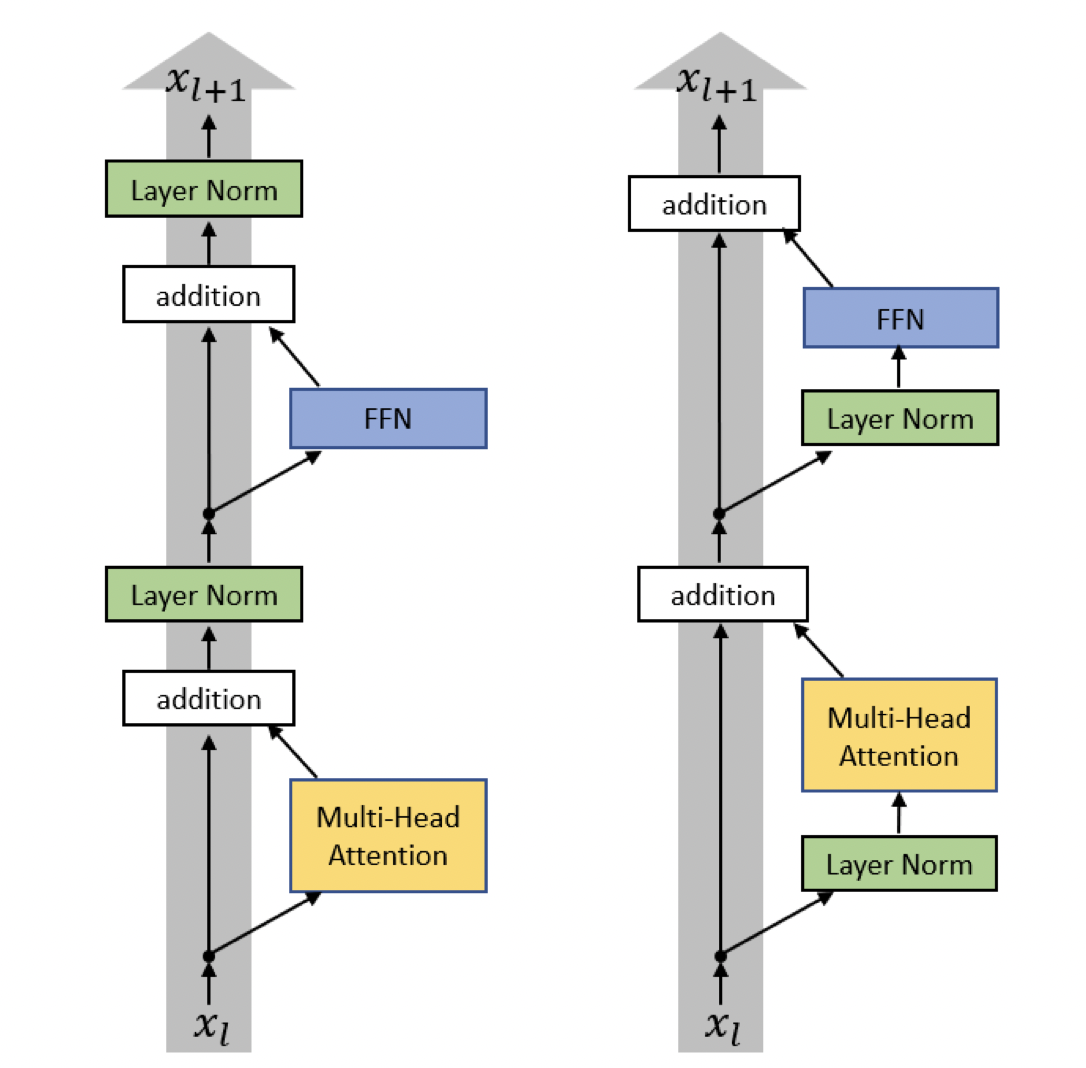
[출처] https://arxiv.org/pdf/2002.04745.pdf, On Layer Normalization in the Transformer Architecture
이는 Ruibin Xiong의 "On Layer Normalization in the Transformer Architecture"에서 layer normalization을 multi-head attentionr과 feedforward layer의 뒤에 주는 것보다 입력부인 앞에 두는 것이 gradient를 고르게 할 수 있다는 아이디어에서 가져온 것이다.
또한 각 layer를 임의로 initialization할 때 layer가 위로 가면 갈수록 layer의 index에 반비례하여 초기화되는 값을 더 작게 만들었다.
이는 레이어가 깊어지면 깊어질수록 선형 변환 등 여러 과정에서 사용되는 파라미터들이 0에 가까워지게끔 하여 더 위쪽에 있는 레이어가 지니는 역할을 줄이고자 한 것이다.
그리고 모델의 residual layer의 수를
GPT-2의 Zero-Shot
앞서 말한 GPT-2의 특징에서 zero-shot setting이 있었는데, 이는 어떠한 새로운 down-stream task에 관해 별도의 fine-tuning을 거치지 않고도 해당 task에 관한 예측을 수행할 수 있도록 하는 것이다.
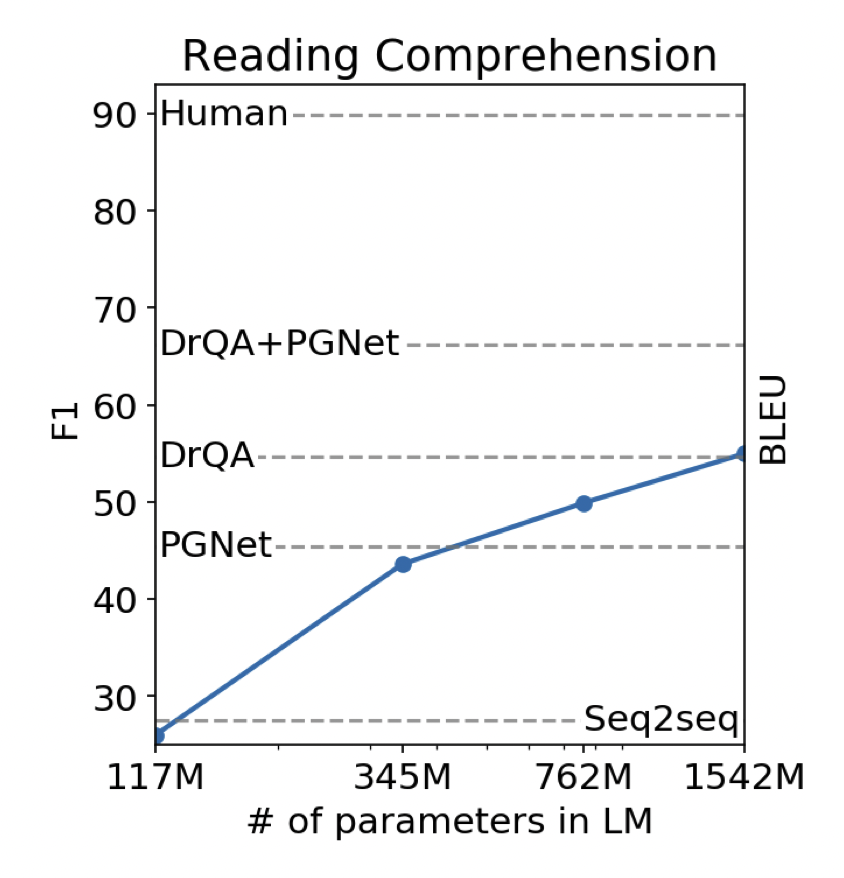
[출처] https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf, Language Models are Unsupervised Multitask Learners
실제로 대화형 질의응답 데이터셋인 CoQA를 사용하여 별도의 fine-tuning 과정을 거치지 않고 질문에 관한 적절한 답변을 예측하도록 했을 때, GPT-2는 약 55만큼의
당연히 fine-tuning된 BERT의

[출처] https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf, Language Models are Unsupervised Multitask Learners
또 다른 예시로 요약을 수행하는 task에서도 fine-tuning 과정 없이 zero-shot setting으로 바로 inference를 수행할 수 있다.
GPT-2는 기본적으로 다음에 올 단어를 예측하는 task를 수행하므로 pre-training에서 사용하는 학습 데이터에서 TL;DR:(Too long, didn't read)이라는 token이 나오면 그 다음 문장으로 앞의 내용의 요약이 주어졌을 것이다.
이를 통해 새로운 데이터셋에 관해 inference할 때 TL;DR:이라는 단어를 다음에 올 수 있는 단어들로 고침으로써 fine-tuning 없이 요약 task를 수행한다.

[출처] https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf, Language Models are Unsupervised Multitask Learners
마찬가지로 번역 task도 주어진 문장에 관해 별도의 fine-tuning 과정을 필요로 하지 않고 'wrote in French'과 같이 앞에 나온 문장을 번역하라는 요청을 추가하여 이후 문장에서 앞 문장에 관한 번역 결과를 생성할 수 있다.
GPT-3
GPT-3는 GPT-2보다 더 많은 파라미터를 학습할 뿐만 아니라 GPT-2에서 소개된 zero-shot learning에서 발전하여 few-shot learning의 가능성을 제시한다.
GPT-3의 특징
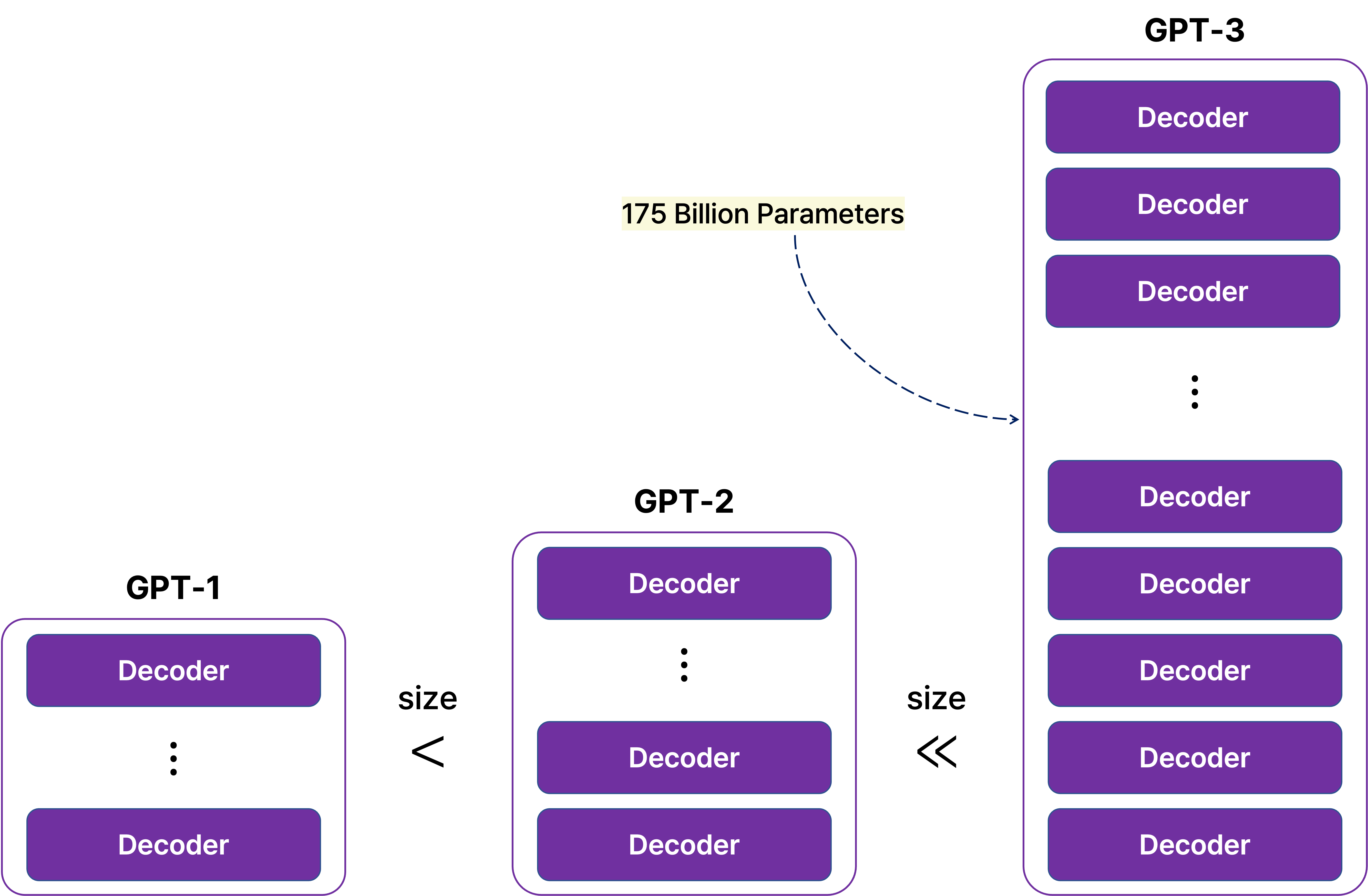
GPT-3는 GPT-2와 비교했을 때 모델 구조 자체에서 큰 차이가 있다기보다는 모델의 크기에서 차이가 생기는데, GPT-3는 96개의 self-attention block을 쌓아서 1,750억 개라는 비교할 수 없을 정도로 월등히 많은 파라미터를 지닌다.
또한 pre-training 과정에서 더 방대한 데이터와 320만이라는 더 큰 크기의 batch를 통해 학습을 수행하여 성능을 향상시킬 수 있었다.
그러나 GPT-3에서 짚어야 할 핵심은 바로 few-shot learner인데, 이는 매우 적은 데이터만으로 task-agnostic performance, 즉 어떤 task든 상관없이 모델에 적용했을 때 나타나는 성능을 향상시킬 수 있음을 보여주었다.
GPT-3의 Few-Shot Learner
[출처] https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf, Improving Language Understanding by Generative Pre-Training
GPT-2에서는 별도의 fine-tuning을 필요로 하지 않고 down-stream task에 적용할 수 있는 zero-shot에 관한 가능성을 보여주었다면, GPT-3에서는 few-shot learner로서의 가능성을 더 높게 끌어올렸다는 점이 주목할 만하다.
Zero-shot setting 뿐만이 아니라 fine-tuning 없이 굉장히 적은 예시의 데이터만을 주고 새로운 데이터셋에 관한 inference의 결과 품질을 끌어올릴 수 있는 one-shot 또는 few-shot settting의 가능성을 제시했다.
One-shot 또는 few shot setting은 down-stream task를 위한 학습 데이터의 양이 매우 적다는 것도 있지만 기존의 새로운 데이터셋에 관해서 fine-tuning하는 것과 근본적으로 차이가 있는데, 바로 down-stream task를 위한 학습 과정에서 output layer 추가하기 등 모델의 구조를 일부 변경하는 작업을 거치지 않는다는 것이다.
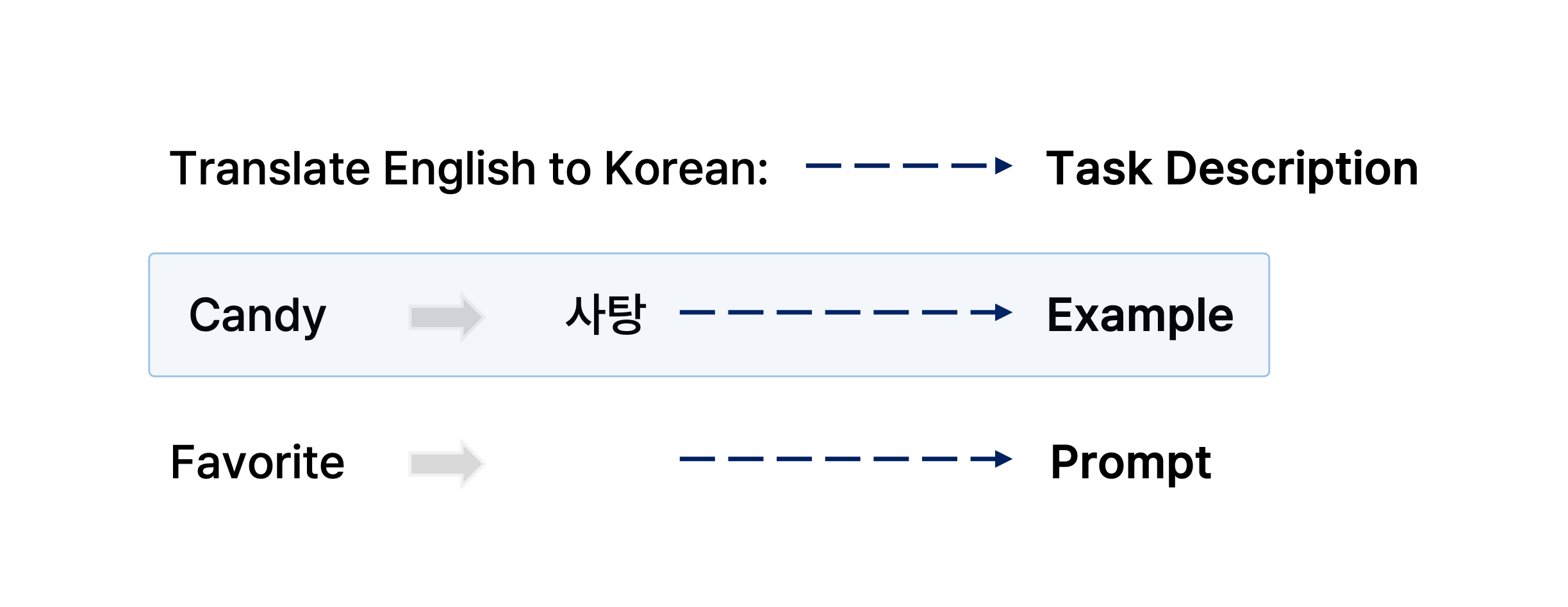
예를 들어, 영어로 어떠한 문장이 주어지고 이를 번역하려는 task를 수행하고자 할 때 어떤 영단어 하나와 그에 대응되는 한국어 단어를 예시 데이터로 주면, down-stream task를 위한 아무런 학습 데이터를 주지 않았을 때보다 번역 생성 문장의 품질이 더 좋아진다는 것이다.
[출처] https://arxiv.org/pdf/2005.14165.pdf, Language Models are Few-Shot Learners, NeurIPS’20
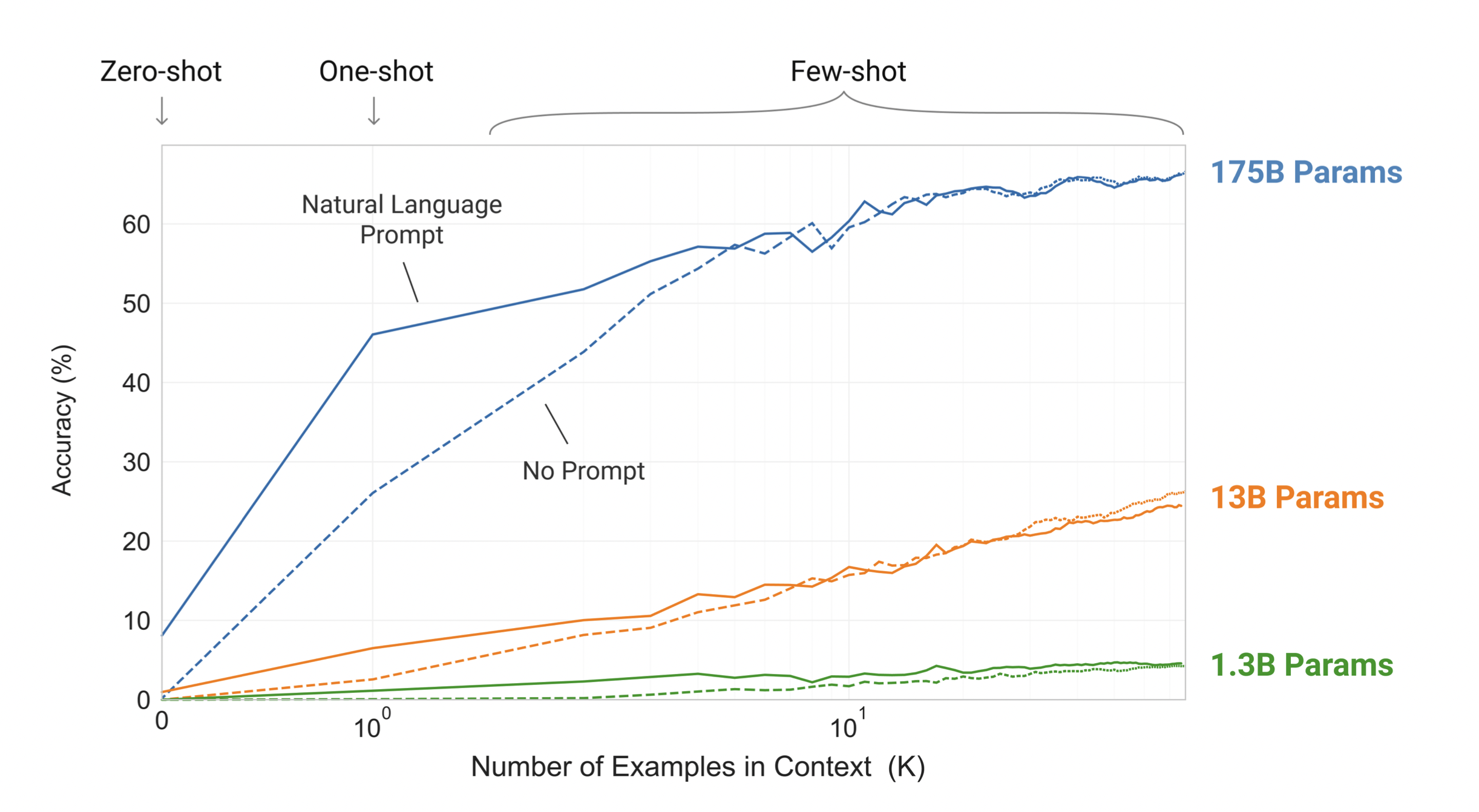
Down-stream task를 위한 학습 데이터 예시를 한 개만이 아니라 여러 개를 주는 few-shot setting에서 더 좋은 성능을 보이는 것을 확인할 수 있다.
[출처] https://arxiv.org/pdf/2005.14165.pdf, Language Models are Few-Shot Learners, NeurIPS’20
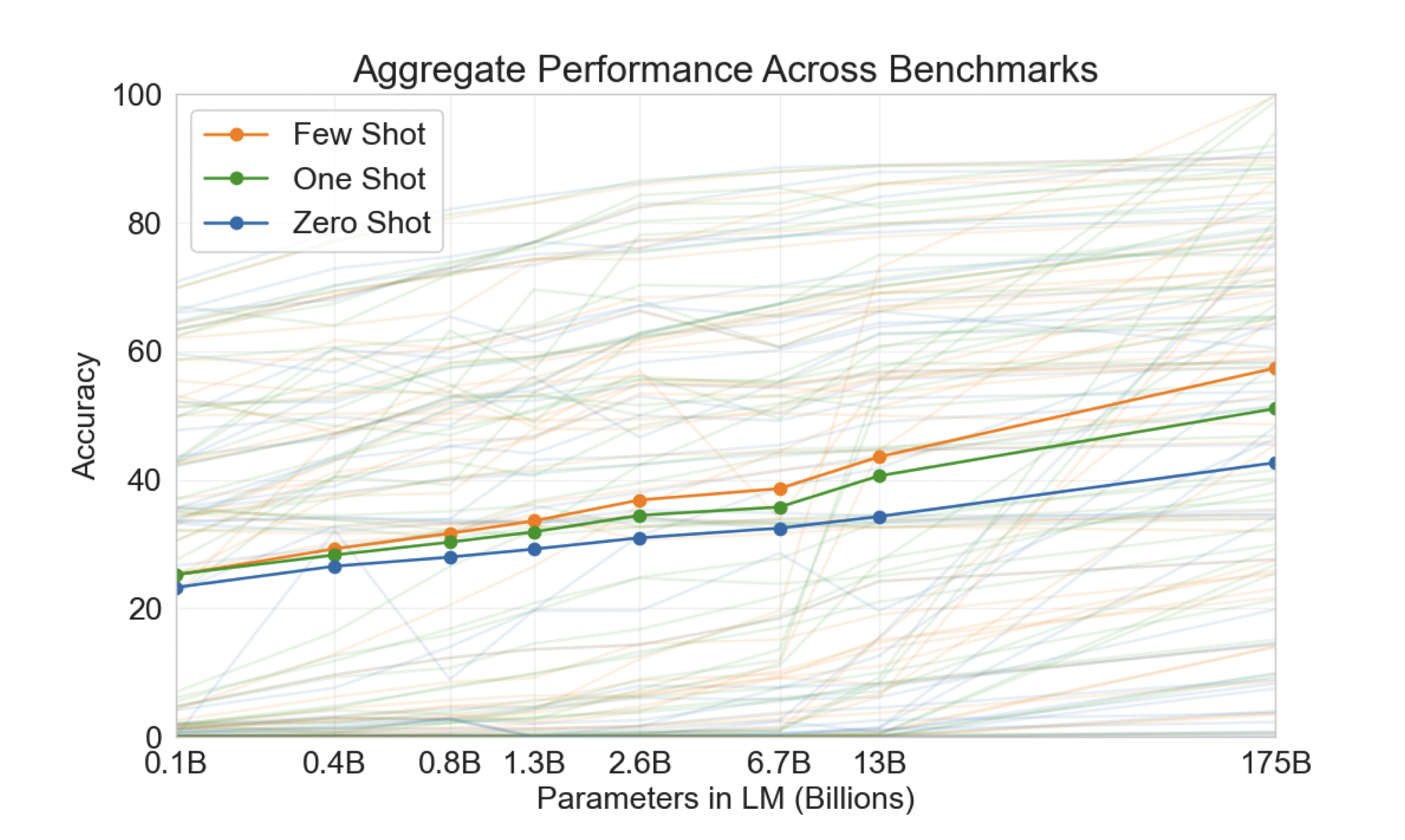
더 흥미로운 사실은 GPT-3 모델의 크기를 키우면 키울수록 zero-shot, one-shot, few-shot의 성능이 더 좋아지며, few-shot의 성능 향상 속도가 zero-shot과 one-shot보다 더 빠르게 증가한다는 점이다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech NLP Track 주재걸 교수님 기초 강의
Contents
소중한 공감 감사합니다.