AI/AI 수학
확률(Probability)과 딥 러닝(Deep Learning)
- -
딥 러닝과 확률론
딥러닝의 학습 방법은 확률론에 기반을 두고 있다.
특히, 기계학습의 손실함수는 데이터 공간을 통계적으로 해석하여 유도하게 된다.
즉, 예측이 틀리는 것을 최소화하도록 데이터를 학습하는 원리를 가진다.
예를 들어, 회귀 분석에서 손실함수로 사용되는
또한 분류 문제에서 사용되는 교차엔트로피(cross-entropy)는 모델 예측의 불확실성을 최소화하는 방향으로 학습을 유도한다.
기계학습에서 사용되는 모든 손실함수는 실제 데이터의 분포와 모델을 예측하는 분포의 차이를 줄이려고 하는 것이며, 이 두 대상을 측정하는 방법은 통계학을 기반으로 한다.
확률분포(Probability Distribution)
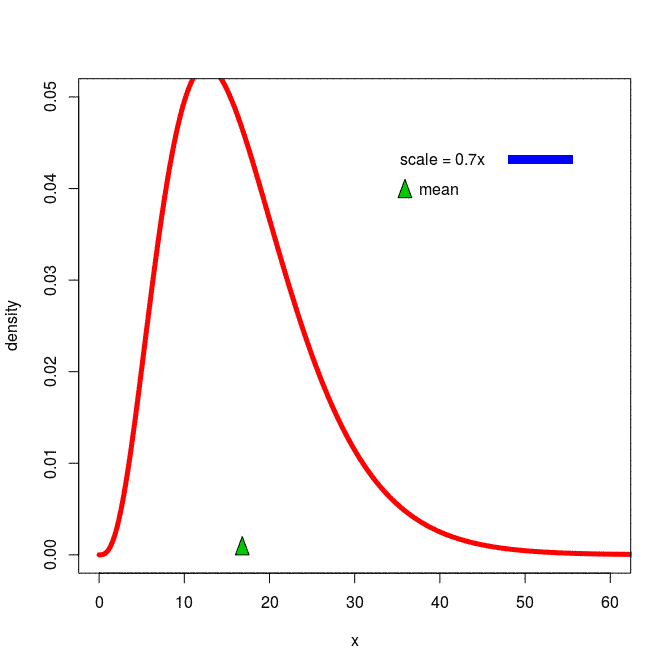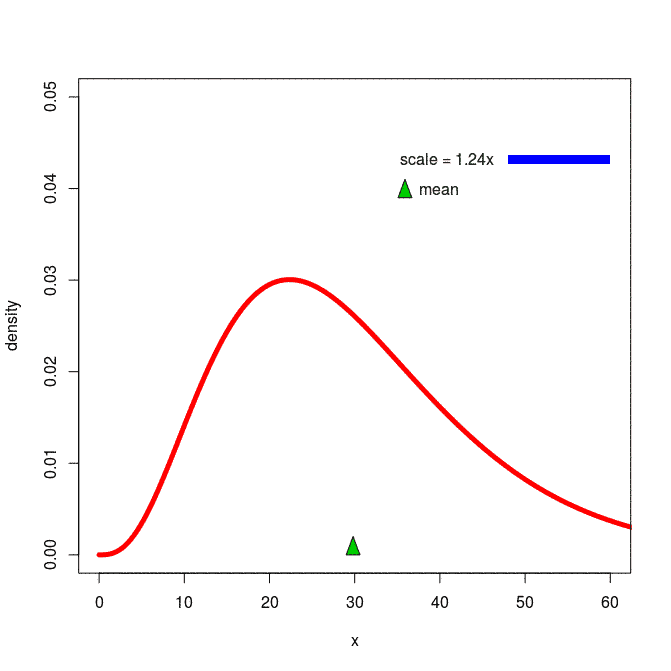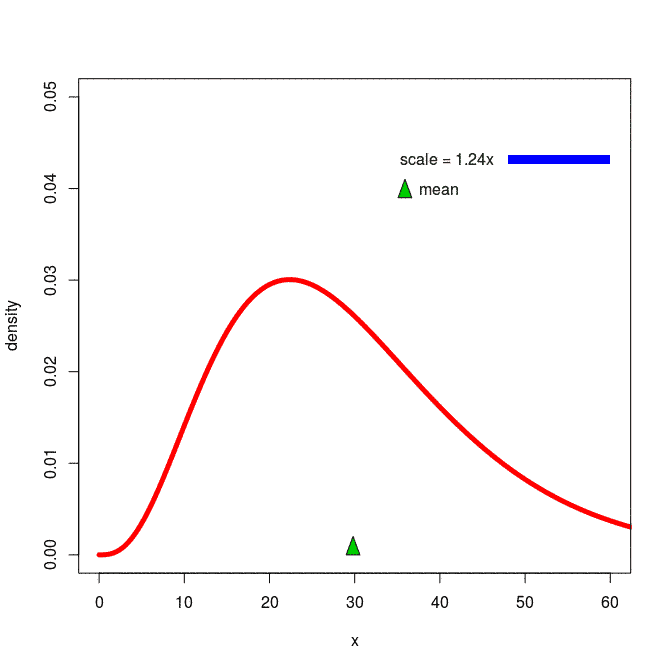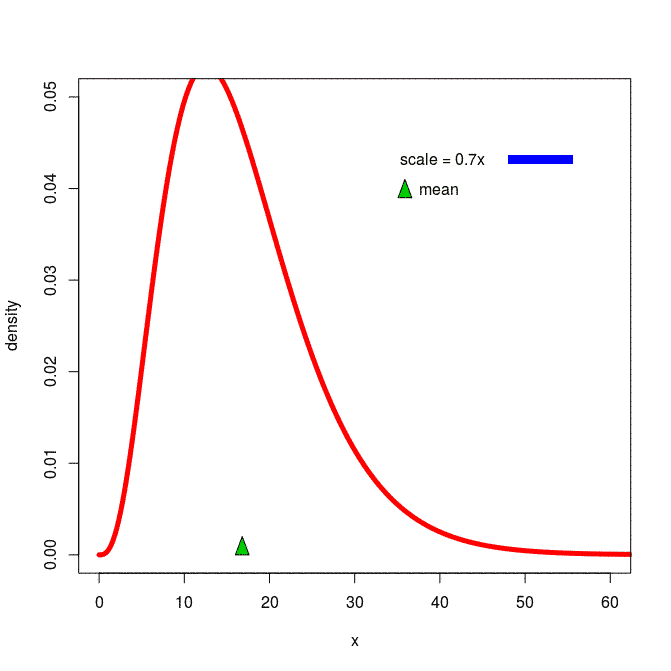
[출처] https://commons.wikimedia.org/wiki/File:Effects_of_a_scale_parameter_on_a_positive-support_probability_distribution.gif, Walwal20
확률분포는 데이터 공간에 위치하는 데이터들을 이해하기 위한 일종의 초상화이다.
하지만 실제 데이터가 생성되는 확률분포
즉, 실제 데이터의 확률 분포는 알 수 없으므로 머신러닝을 통해 실제 확률분포에 근사하는 함수를 찾아야 한다.
확률변수(Random Variable)
랜덤변수(확률변수)에 관한 자세한 설명은 다음 글을 참고.
https://glanceyes.tistory.com/entry/인공지능-기초-Uncertainty-1-확률적인-추정을-위한-확률과-사건-그리고-명제
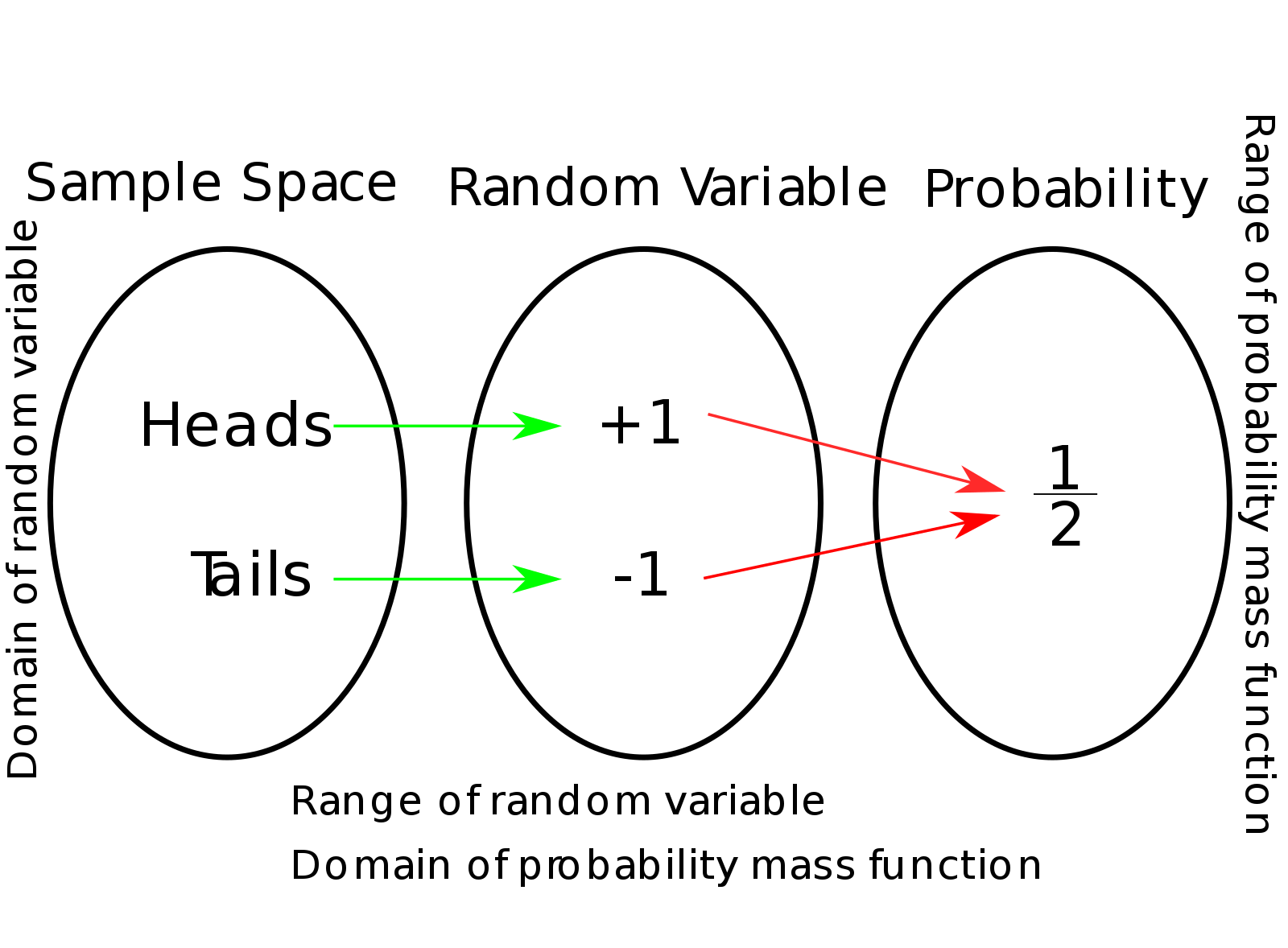
[출처] https://commons.wikimedia.org/wiki/File:Random_Variable_as_a_Function-en.svg, Niyumard
확률변수는 데이터 공간 상에서 관측 가능한 데이터이다.
변수가 1개인 지도학습을 상정했을때, 데이터 공간은
확률변수는 이 공간상에서 관측되는 원소들이다.
확률변수는 함수에 의해 해석되며, 이 함수는 임의로 데이터 공간상에서 관측하게 되는 함수이다.
데이터 공간상에서 데이터를 추출할 때 확률변수를 사용하게 되며, 이렇게 추출된 데이터의 분포
이산확률변수와 연속확률변수
데이터 공간으로부터 확률변수에 의해 추출된 데이터는 분포를 가지며, 확률분포
이 확률분포
이는 데이터 공간
즉, 확률변수의 분포가 이산형인지 연속형인지에 따라 이산확률변수 또는 연속확률변수라고 한다.
예를 들어, -0.5와 0.5 중 한 값을 지니는 데이터 분포가 있을 때, -0.5와 0.5는 실수 데이터 공간을 지니지만 연속형이 아닌 이산형 확률변수를 가진다고 할 수 있다.

이산형 확률변수는 확률변수가 가질 수 있는 모든 경우의 수를 고려하여 확률을 모두 더해 모델링한다.
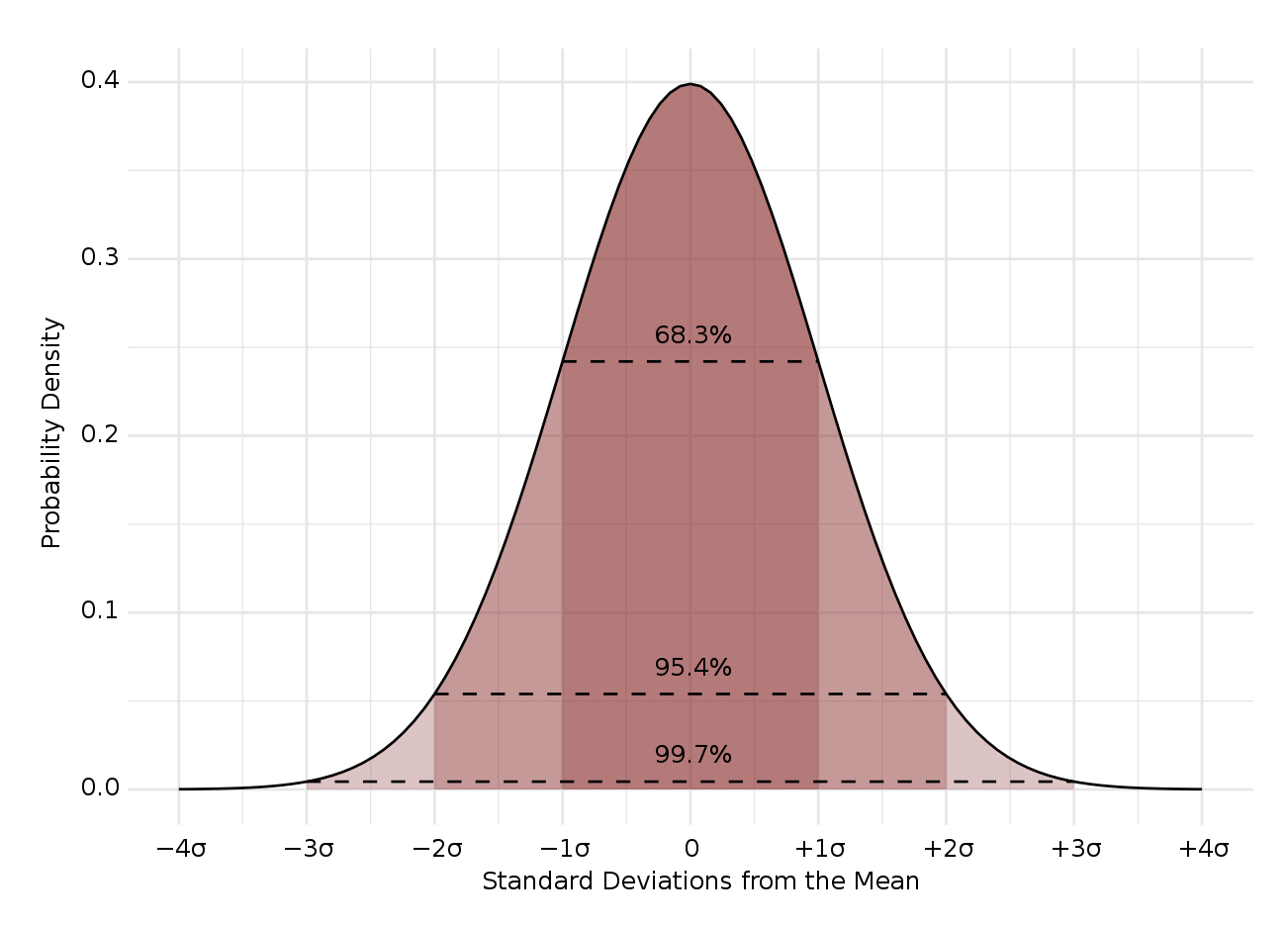
[출처] https://commons.wikimedia.org/wiki/File:Standard_Normal_Distribution.svg, D Wells
연속형 확률변수는 데이터 공간에 정의된 확률변수의 밀도의 적분을 통해 모델링한다.
여기서의 밀도는 누적확률분포의 변화율을 모델링하는 것이며, 이는 확률과는 다르다.
즉, 특정 값에서의 확률값은 알 수 없고, 구간을 통해서 데이터가 그 구간에 속할 가능성을 구하는 것이다.
모든 확률변수가 항상 두 가지로 구별되는 것은 아니라는 점에 주의한다.
확률분포의 종류
확률분포에 관한 자세한 설명은 다음 글을 참고.
https://glanceyes.tistory.com/entry/인공지능-기초-Uncertainty2-결합-확률과-조건부-확률-그리고-베이즈-정리?category=1069509
[인공지능 기초] Uncertainty(2) - 결합 확률과 조건부 확률 그리고 베이즈 정리
지난 글에서 우리는 이 세상의 많은 일들이 확률에 의존한다는 것을 알았고, 사건에 관한 확률을 다룰 때 명제로 표현하여 사용한다는 점을 확인했다. 또한 증거(evidence)가 기존에 알고 있던 정
glanceyes.com
결합분포(Joint Distribution)
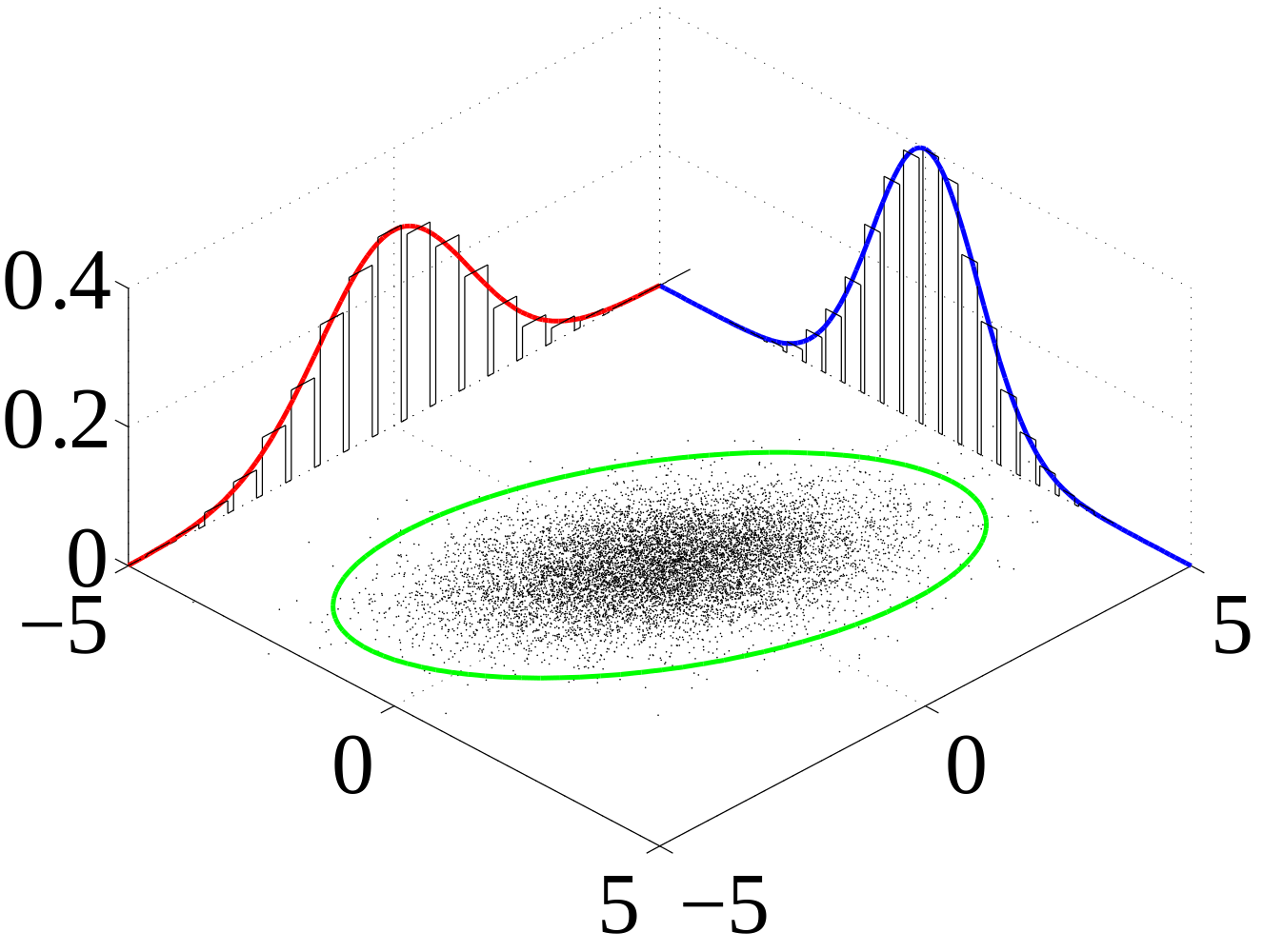
[출처] https://commons.wikimedia.org/wiki/File:Multivariate_normal_sample.svg, IkamusumeFan
결합분포는 주어진 데이터로부터 확률변수
즉, 결합분포
주변확률분포
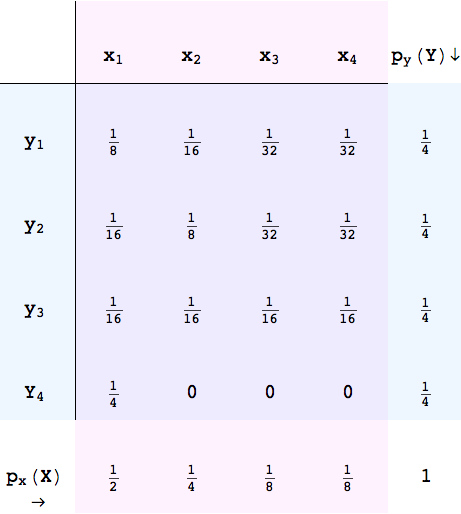
[출처] https://commons.wikimedia.org/wiki/File:Jointdist_twodepvars.PNG, CaitlinJo
오직
이는 변수의 특성에 따라 다음과 같이 정의된다.
조건부 확률분포(Conditional Distribution)
이는 데이터 공간에서 입력
단, 연속확률분포일 경우에는
조건부확률과 기계학습
로지스틱 회귀에서 사용했던 선형모델과 softmax 함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용된 것이다.
분류 문제에서
즉, Input
조건부 기대값
회귀문제의 경우에는 특정
조건부 기대값인
조건부 기대값은 밀도함수인 조건부 확률분포에서
기댓값(Expectation)
기댓값은 데이터를 대표하는 통계량이며, 다른 통계적 수치를 계산하는데 사용된다.
기댓값을 이용해 분산, 첨도, 공분산 등 여러 통계량을 계산할 수 있다.
딥 러닝과 특징패턴
딥러닝은 주어진 데이터
이때, 특징패턴을 학습하기 위해 어떤 손실함수를 사용할지는 기계학습의 문제와 모델에 의해 결정되는 것이다.
몬테카를로 방법(Monte Carlo method)
기계학습에서는 확률분포를 대체로 모를 때가 많다.
이때, 데이터를 이용해 기댓값을 계산하는 방법으로 몬테카를로 샘플링을 이용한다.
데이터를 여러 번 독립추출하면 대수의 법칙에 따라 이들의 기댓값(샘플링의 기댓값)은 실제 데이터 분포의 기댓값에 수렴하며, 이는 이산형 또는 연속형 확률변수에 무관하게 사용 가능하다.
단, 샘플링하는 데이터의 크기가 어느 정도 커야 한다.
Contents
소중한 공감 감사합니다.