AI/추천 시스템
추천 시스템에서의 Implicit Feedback
- -
추천 시스템에서의 Implicit Feedback
Implicit Feedback
Implicit feedback은 explicit feedback과는 달리 사용자의 선호에 대한 암시적인 정보만을 제공하지만, 그것의 수집 효율성 및 generality 덕분에 사용자의 실제 선호를 추정하는 데에 더욱 효율적일 수 있다.
예를 들어, 어떤 한 사용자가 앱을 이용하여 상품을 구매했을 때 리뷰를 작성하는 시나리오를 가정한다.
이때 평점을 작성해야 하는 경우에는 사용자에게 귀찮은 일이 될 수 있으므로 실제로 많은 feedback이 수집되기에는 한계가 있다.
반면에 implicit feedback은 사용자의 모든 기록된 행위를 사용하기 때문에 방대한 양의 데이터를 활용할 수 있으며, 이를 오히려 잘 분석하여 explicit feedback보다 비즈니스의 목적을 더 잘 달성할 수 있다.
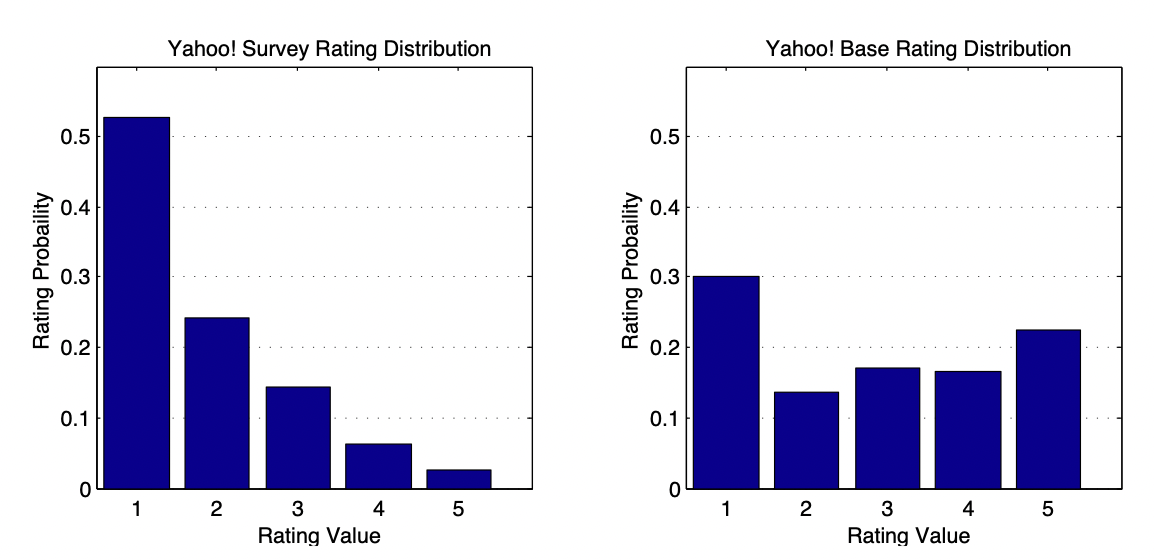
[출처] https://arxiv.org/pdf/1206.5267.pdf, Collaborative Filtering and the Missing at Random Assumption
Explicit feedback을 사용한 추천 시스템에서는 주로 관측된 데이터로부터 관측되지 않은(unseen) 데이터를 예측해야 하는데, 관측된 평점 분포와 랜덤 평점 분포 사이에 불일치가 존재하면 이로 인해 generalizable 하지 않을 수 있음을 유추할 수 있다.
최근 대부분의 추천 연구도 단순 평점 예측보다는 Top-K ranking 추천 문제를 주로 다루고 있을 정도로 implicit feedback이 더 활발히 연구되고 있다.
이는 보다 풍부한 데이터를 활용할 수 있으며, 사용자가 다음에 무엇을 클릭할지를 예측하는 게 주 목표일 때 implicit feedback이 이러한 추천 태스크에 더 적합하기 때문이다.
또한 비즈니스 목표와의 직접적인 연관성이 explicit feedback보다는 좀 더 높다고 볼 수 있다.
Explicit feedback을 사용하여 RMSE를 최적화하는 것이 과연 추천에 도움이 되는지에 관해 의문점이 있다고 볼 수 있는데, 이는 RMSE 기준으로 추천되는 영화가 사용자의 입맛에는 맞더라도 다양하고 새로운 콘텐츠를 발견해줄 수 있는지에 관해서는 만족스럽지 못할 수 있어서다,

그러나 주로 E-Commerce 업체에서는 명확하고 세분화된 사용자 선호를 반영하는 explicit feedback의 강점을 이용하는 경우가 많다.
예를 들어, Coupang에서는 제품을 구매한 사용자가 리뷰에 평점을 매길 수 있는데, 이를 바탕으로 사용자에게 개인화된 추천을 해줄 수 있다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech RecSys Track
Contents
소중한 공감 감사합니다.