AI/추천 시스템
Autoencoder를 응용한 추천 시스템
- -
2022년 3월 7일(월)부터 11일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
Autoencoder를 응용한 추천 시스템
Autoencoder
입력 데이터를 출력으로 복원(reconstruct)하는 비지도(unsupervised) 학습 모델이다.
중간 hidden layer를 input data의 feature representation으로 활용한다.
주어진 입력에 대해서 reconstructed input과의 차이를 줄이는 것을 목표로 한다.
Denoising Autoencoder(DAE)
입력 데이터에 random noise나 dropout을 추가하여 학습시키는 것이다.
Noisy input을 더 잘 복원할 수 있는 robust한 모델이 학습되어 전체적인 성능이 향상된다.
학습 데이터에만 overfitting되지 않고 이를 극복하여 더 좋은 일반화 성능을 보일 수 있도록 한다.
AutoRec
Autoencoder를 CF에 적용하여 기본 CF 모델에 비해 표현력은 증가시키고 복잡도는 줄인 모델이다.
Rating Vector를 입력과 출력으로 하여 Encoder & Decoder Reconstruction 과정을 수행한다.
유저 또는 아이템 벡터를 저차원의 latent feature로 나타내 이를 사용하여 평점을 예측한다.
Autoencoder의 representation learning을 유저와 아이템에 적용한 것이다.
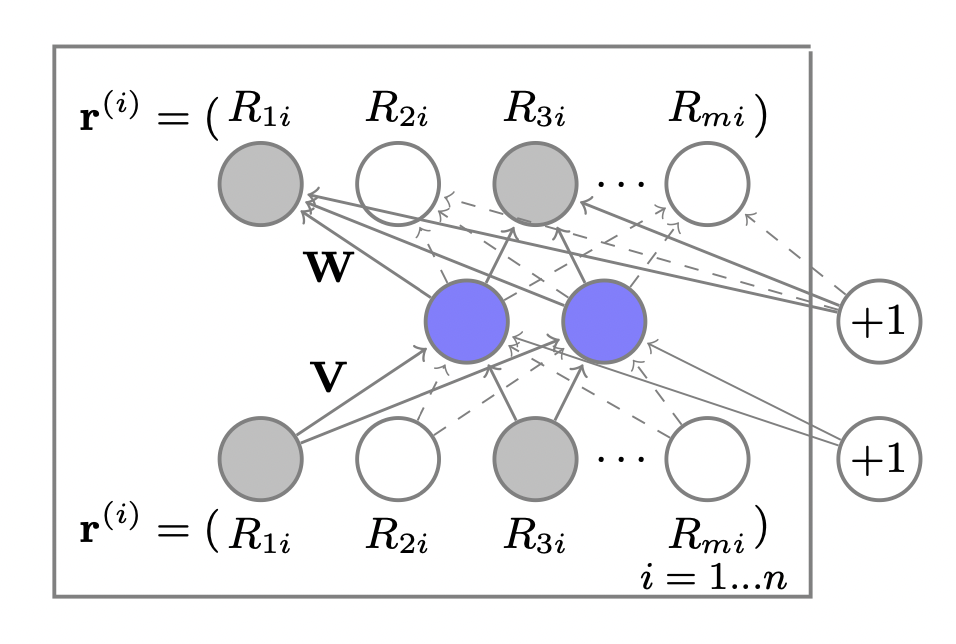
[출처] https://users.cecs.anu.edu.au/~akmenon/papers/autorec/autorec-paper.pdf, AutoRec: Autoencoders Meet Collaborative Filtering
MF는 linear하고 low-order한 interaction을 통해 representation이 학습되지만, AutoRec은 non-linear activation function이 사용된다.
아이템과 유저 중 한 번에 하나에 대한 임베딩만을 진행한다.
기존의 rating과 reconstructed rating의 RMSE를 최소화하는 방향으로 학습된다.
관측된 데이터에 관해서만 역전파 및 파라미터 업데이트를 진행한다.
$$ \underset{\theta}{\min} \underset{r \in S}{\sum} \| \mathbf{r} - h(\mathbf{r}; \theta)\|_2^2 $$
$$ h(\mathbf{r}; \theta) = f(\mathbf{W} \cdot g(\mathbf{Vr} + \mathbf{\mu}) + \mathbf{b}) $$
$g(\mathbf{Vr} + \mathbf{\mu})$처럼 원래의 rating $\mathbf{r}$에 encoder의 가중치인 $\mathbf{V}$를 곱하고, $\mu$라는 bias를 더해서 $g$라는 activation function을 씌우게 되면, 이는 가운데에 있는 representation이 된다.
여기에 decoder의 가중치인 $W$를 곱하고, 가중치 bias인 $\mathbf{b}$를 더하여 $f$라는 activation function을 씌우게 되면 최종적으로 reconstructed representation이 된다.
Reconstructed rating과 실제 rating 사이의 차이를 최소화하는 방법으로 각각의 파라미터인 $\mathbf{W}$, $\mathbf{V}$, $\mu$, $\mathbf{b}$가 업데이트된다.
대체로 Hidden unit의 개수가 많아질수록 RMSE가 감소함을 보인다.
Collaborative Denoising Auto Encoder(CDAE)
Denoising Autoencoder를 CF에 적용하여 Top-N 추천에 활용하는 것이다.
AutoRec이 Rating Prediction(평점 예측)을 위한 모델이라면, CDAE는 Ranking을 통해 유저에게 Top-N 추천을 제공하는 모델이다.
문제 단순화를 위해 유저-아이템 상호 작용 정보를 이진(0 또는 1) 정보로 바꿔서 학습 데이터로 사용한다.
그래서 개별 유저에 대해서 아이템의 rating이 아닌 preference를 학습하게 된다.
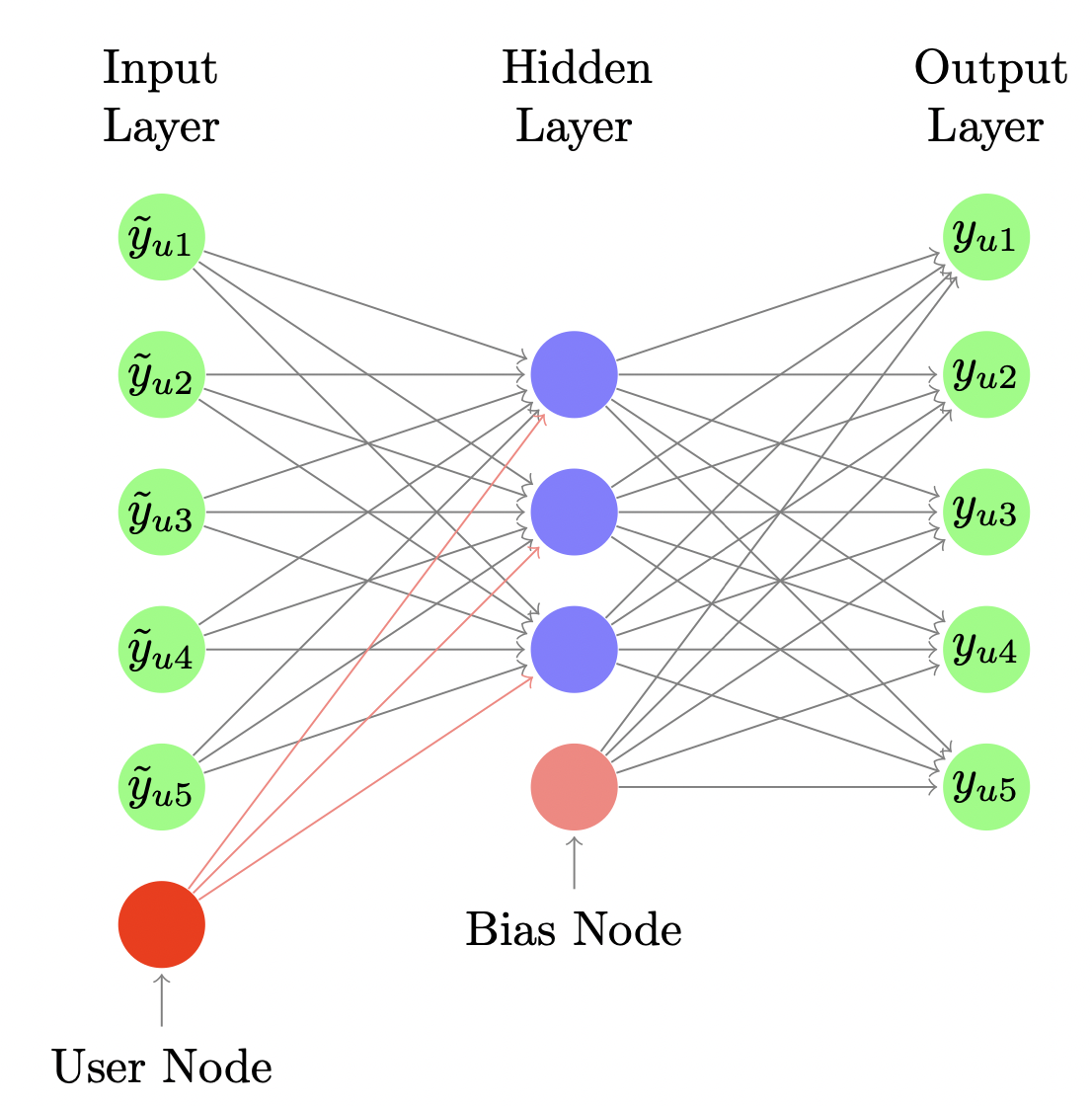
[출처] https://alicezheng.org/papers/wsdm16-cdae.pdf, Collaborative Denoising Auto-Encoders for Top-N Recommender Systems
AutoRec과는 달리 DAE(Denoising Autoencoder)를 사용하여 noise를 추가한다.
$$ P(\tilde{y}_u = \delta y_u) = 1 - q, P(\tilde{y}_u = 0) = q $$
$\tilde{y}_u$는 $q$의 확률에 의해 0으로 drop-out된 벡터이다.
어떤 벡터는 $q$의 확률에 0으로 되고 다른 어떤 벡터는 $1-q$의 확률에 의해 기존 평점 값에 $\delta$를 곱한 값을 갖는다.
개별 유저에 관해서 $V_u$를 학습하는데, 다시 말해서 유저에 따른 특징을 해당 파라미터 $V_u$가 학습하고 Top N 추천에 사용한다.
인코더로 latent representation $z_u$를 생성하고 디코더로 regenerate한다.
$z_u = h(W^T + V_u + b)$
$\hat{y}_{ui} = f({W'}_{i}^{T} z_u + b'_i)$
VAE와 Autoencoder 차이점
다음 자료를 참고하면 VAE와 AE의 자세한 차이점을 확인해볼 수 있다.
참고 자료 -딥러닝 개념 1. VAE(Variational Auto Encoder)
딥러닝 개념 1. VAE(Variational Auto Encoder)
AE와 VAE의 차이점은 AE는 잠재공간 z에 값을 저장하고 VAE는 확률 분포를 저장하여 (평균, 분산) 파라미터를 생성한다는 점이다. VAE의 decoder는 encoder가 만들어낸 z의 평균, 분산을 모수로 하는 정규
velog.io
생성 모델(Generative Model)과 VAE, 그리고 GAN
2022년 2월 7일(월)부터 11일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거
glanceyes.tistory.com
Autoencoder에서 encoder를 통과한 Latent vector를 다시 원래 차원의 데이터로 생성하는 것을 decoder가 담당한다
VAE(Variational Auto Encoder)는 Autoencoder에서 파생된 것이다.
VAE의 가장 큰 차이점은 차원 축소용으로 주로 쓰이는 Auto Encoder와는 달리, VAE는 Encoder 부분에서 latent space에서 sampling할 때 latent vector를 뽑아내서 확률분포를 찾아내 데이터를 새로 생성하는 부분에서 차이가 있다.
구체적인 차이점은 다음과 같다.
- VAE는 latent variable의 분포를 정규분포 형태로 나타내고, 그 분포에서 샘플링한다.
- VAE는 AE와 달리 생성모델이다. (AE는 입력 데이터를 재구성할 수 있지만, 그대로 생성 모델로 적용하기 어렵다.)
- VAE는 prior에 대한 condition을 부여하므로 z vector가 prior과 같은 분포를 따른다.
- 예를 들어, prior가 정규분포라면 z vector도 같은 분포를 갖는다.
- AE는 'prior에 대한 조건(condition)'이 없기 때문에 의미있는 z vector의 space가 계속 바뀌게 된다.
- 즉 새로운 이미지를 생성할 때 z 값이 계속해서 바뀌게 된다.
'AI > 추천 시스템' 카테고리의 다른 글
| Context 기반 추천 모델인 FM(Factorization Model)과 FFM(Field-aware Factorization Machine) (0) | 2022.03.19 |
|---|---|
| RNN 계열의 GRU 모델을 활용한 GRU4Rec (0) | 2022.03.19 |
| 딥 러닝을 사용한 추천 시스템과 대표적인 예시인 유튜브 영상 추천 (0) | 2022.03.13 |
| ANN(Approximate Nearest Neighbor)과 ANNOY (0) | 2022.03.13 |
| Word2Vec을 응용한 Item2Vec (0) | 2022.03.13 |
Contents
소중한 공감 감사합니다.