AI/추천 시스템
Embarrassingly Shallow Autoencoders for Sparse Data: EASE 모델이 희소 데이터에 강한 이유
- -
Introduction
한 달이라는 긴 시간동안 네이버 부스트캠프 AI Tech 3기에서 진행했던 Movielens 데이터 기반의 영화 추천 대회 프로젝트가 마무리되었다. 팀원들과 밤낮으로 회의하면서 어떠한 모델을 사용하는 게 좋을지 고민했었는데, 순차 데이터보다는 좀 더 일반적인 데이터에 강한 autoencoder 기반의 여러 모델을 중심으로 앙상블한 것을 바탕으로 inference 결과를 제출했다.
그중에서 EASE(Embarrassingly Shallow Autoencoders for Sparse Data, ESAE)라는 모델이 매우 신기했는데, 다른 autoencoder 기반의 모델보다 상대적으로 성능이 좋을 뿐더러 매우 짧은 실행 시간을 가지는 특징을 지닌다. Hidden layer이 존재하지 않아 학습 파라미터의 수가 한 개로 매우 작다는 것도 눈여겨 볼 만하다.
사실 EASE를 대회에서 시도해 본 것도 EASE 모델 자체가 sparse한 데이터와 cold start problem에 강해서 특히 Million Song Dataset에서 다른 모델보다 압도적으로 좋은 성능을 보인다는 글을 보고 적용한 것인데, 예상보다 성능이 매우 좋게 나와서 팀원들 사이에서 놀랍다는 반응이 많이 나왔다. 실제로 paperswithcode.com에 올라온 평가 지표 결과를 봐도 EASE가 우수한 성능을 낸다는 걸 볼 수 있다.
[Million Song Dataset을 기반으로 평가한 모델 성능 비교]
https://paperswithcode.com/sota/collaborative-filtering-on-million-song
Papers with Code - Million Song Dataset Benchmark (Recommendation Systems)
The current state-of-the-art on Million Song Dataset is EASE. See a full comparison of 6 papers with code.
paperswithcode.com
Million Song Dataset에서는 EASE가 RecVAE보다도 압도적인 성능을 보인다.
[Movielens 20M을 기반으로 평가한 모델 성능 비교]
https://paperswithcode.com/sota/collaborative-filtering-on-movielens-20m
Papers with Code - MovieLens 20M Benchmark (Recommendation Systems)
The current state-of-the-art on MovieLens 20M is VASP. See a full comparison of 15 papers with code.
paperswithcode.com
Movielens 20M에서는 EASE가 H+Vamp Gated, RecVAE 등 다른 SOTA 모델보다는 성능이 좋지 못한 것으로 나오지만, 이번 대회에서는 Movielens 20M에 무작위로 마스킹을 하여 데이터가 더 희소해지면서 cold start problem 현상이 생겨서 EASE 단일 모델 성능이 RecVAE, H+Vamp Gated보다도 더 좋은 성능을 냈다. 여기서 cold start problem이란 어떤 유저의 활동 이력이 충분치 않아서 해당 유저에게 적절한 새로운 아이템을 추천하기 어려운 현상을 의미한다.
그런데 왜 EASE는 딥 러닝 모델이라고 보기 힘든 단순한 모델임에도 불구하고 희소 데이터에서 두드러지는 모습을 보이는지 궁금했다. 대회를 진행할 때는 시간에 쫒겨서 모델 자체를 제대로 분석하지 못했는데, 대회도 끝난 겸 궁금증을 참고만 있을 수가 없어서 이 모델이 소개된 다음 논문을 공부해봤다.
EASE(Embarrassingly Shallow Autoencoders for Sparse Data, ESAE)란?
모델명에서 shallow는 어떤 의미인가?
추천 시스템 논문을 보면 모델명에 모델의 특징이 포함되어 있는 경우가 종종 있다. 이 모델도 마찬가지로 이름을 직역하면 희소한 데이터를 위한 당황스러울 정도로 얕은 Autoencoders인데, 여기서 'embarrassingly shallow'는 것은 hidden layer가 존재하지 않는 선형 모델임을 의미한다. ('shallow' 자체에 관해서만 정확히 말하자면, hideen layer가 1개이거나 매우적은 모델을 shallow라고 말할 수 있을 것이다.)
일반적으로 autoencoder는 input 데이터를 encoder layer에 통과시켜서 latent space로 보내고, 이를 다시 decoder layer에 통과시켜서 재생성된 output이 얼마나 input과 유사한지를 비교하면서 학습을 진행한다. 그래서 autoencoder 기반의 모델에서는 encoder와 decoder라는 hidden layer가 존재한다. 이는 encoder layer에 input 데이터를 통과시켜서 나오는 latent space의 샘플링 분포의 모수인 평균과 분산을 추출하는 variational autoencoder 기반의 생성 모델에서도 마찬가지이다.
반면에 ESAE에서는 hidden layer를 필요로 하지 않아서 모델이 굉장히 단순하다. 실제로 모델 코드를 보면 다소 어이가 없을 정도로 간단하다. 논문에서는 이 모델의 별칭을 EASE로 사용하는데, 개인적으로 저자가 아마 이러한 특징을 노리고 이 모델의 약자인 ESAE를 역순으로 해서 '쉽다'는 의미의 EASE로 재치있게 이름을 붙인 게 아닌가 싶다.
그렇다고 Autoencoder은 아니다
이 논문에서 모델 이름에 autoencoder를 넣은 이유를 다음과 같이 설명하고 있다.
This is done by reproducing the input as its output, as is typical for autoencoders. We hence named it Embarrassingly Shallow AutoEncoder.
EASE는 input으로 받은 데이터가 어떠한 함수를 거쳐서 재생성된 output으로 나온다는 점에서 autoencoder와 유사하지만, 사실 엄밀히 말하면 autoencoder가 아니다.
EASE에서는 autoencoder와는 달리 input data를 latent space로 보내서 latent factor를 얻는 과정을 거치지 않지만, 단지 input 데이터가 output 데이터로 재생성된다는 점이 autoencoder과 닮아 있다. 즉, autoencoder와 닮아 있는 점이라고는 multi-hot vector로 이루어진 행렬 입력 데이터를 모델에 넣고 이를 출력 데이터로 재생성하여 원래의 입력 데이터와 loss를 비교하는 과정일 뿐이며, 정확히는 autoencoder 기반 모델이 아니다.
EASE의 특징
세 가지로 요약한 특징
논문에서 소개된 EASE의 특징을 세 가지로 요약하자면 다음과 같다.
- Hidden layer가 없다.
- Convex한 목적함수가 closed form solution이다.
- 학습 파라미터의 대각 성분이 0이다.
Hidden layer가 없다는 것은 앞에서 여러 번 언급되었지만, 목적함수가 closed form solution이라는 말은 잘 이해가 가지 않았다. 딥러닝에서는 이처럼 'closed form'이라는 말이 자주 등장하는데, closed form이 무엇인지 알아보았다.
Closed form(닫힌 형태)이란?
쉽게 말해 유한개의 방정식을 사용하여 어떠한 해를 해석적(analytic)으로 표현할 수 있는 종류의 문제를 의미하며, 간단하게
일반적으로 딥 러닝에서 목적함수를 통해 파라미터를 최적화 할 때는 관측해야 할 파라미터가 많아서 닫힌 형태로 정의되지 않는 경우가 많다. 그래서 목적함수를 미분하여 극대, 극소 등 임계점을 구하기가 어려워진다. 그래서 목적함수의 gradient를 구해서 해당 방향으로 이동하도록 파라미터를 업데이트하면서 극대 또는 극소에 도달하고자 하는 것이다.
그러나 EASE에서는 학습 파라미터의 최적해가 간단한 식으로 표현되는 closed form solution을 띤다. 그래서 EASE를 학습시키는 데 있어서 걸리는 wall-clock time이 Slim 모델을 학습시킬 때보다 몇 배로 더 적게 들 수 있다고 논문에서 말하고 있다. 여기서 wall-clock time은 실제로 모델이 학습하는 데 걸린 시간에 관해 사용자가 인지하기까지의 시간을 뜻한다.
EASE는 어떻게 학습할까?
입력 데이터
입력 데이터 행렬인
각 유저별로 어떠한 아이템을 클릭 또는 구매했는지에 관한 정보가 0 또는 1인 값으로 표현되어 있는데, positive feedback이 1의 값을 지닌다.
예를 들어, 다음과 같이 A, B, C 유저별로 a, b, c, d 아이템을 클릭한 데이터를 바탕으로
| 아이템 a | 아이템 b | 아이템 c | 아이템 d | |
|---|---|---|---|---|
| 유저 A | 0 | 1 | 1 | 0 |
| 유저 B | 1 | 0 | 1 | 1 |
| 유저 C | 0 | 0 | 0 | 1 |
학습 파라미터
앞서 말했듯이 EASE는 학습 파라미터가 한 개밖에 없는데, 이 학습 파라미터
이를 입력 데이터
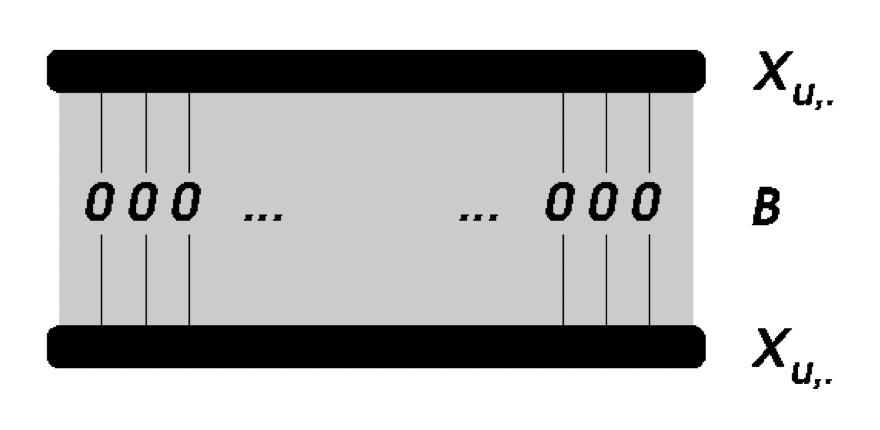
The self-similarity of each item is constrained to zero between the input and output layers.
논문에서도 여러 번 강조되지만 여기서 주의할 점은
이는 목적함수에서도 다루겠지만, 결국
출력 데이터
우리는 유저
목적함수
파라미터
논문에서는 closed-form solution을 만족하기 위해
그런데 multinomial likelihood와 같은 다른 손실함수를 사용하면 ranking의 정확도가 향상될 수도 있다고 첨언했는데, 이번 대회에서 square loss 대신에 다른 손실함수를 썼으면 점수가 더 오를 수 있지 않았을까 하는 아쉬움이 들었다.
목적함수를 최적화 하는 해 찾기
일반적인 딥 러닝 모델이라면
import torch
class EASE(nn.Module):
def __init__(self, n_items, lambda1, lambda2):
super(EASE, self).__init__()
self.B = torch.nn.Parameter(torch.Tensor(n_items, n_items))
self.lambda1 = lambda1
self.lambda2 = lambda2
def forward(self, X):
recon_matrix = X @ self.B # X와 B 행렬곱으로 재생성된 X'
loss = X.sub(recon_matrix)
loss = loss ** 2
loss = loss.sum()
regularization = torch.norm(self.B)
constraint = torch.sum((torch.diag(self.B) - 0) ** 2)
return loss + self.lambda1 * regularization + self.lambda2 * constraint
하지만 이럴 경우 보통 일반적인 딥 러닝 모델과 다르지 않아 효율이 떨어지고 학습 시간은 늘어날 수밖에 없다. 그래서 논문 저자는 closed-form solution을 제시하여 목적함수를 최소화 하는 해를 찾는 문제를 최적화 하는 방법을 제시했다.

논문에서 위에서 정의한
제약사항인
위에서
결국
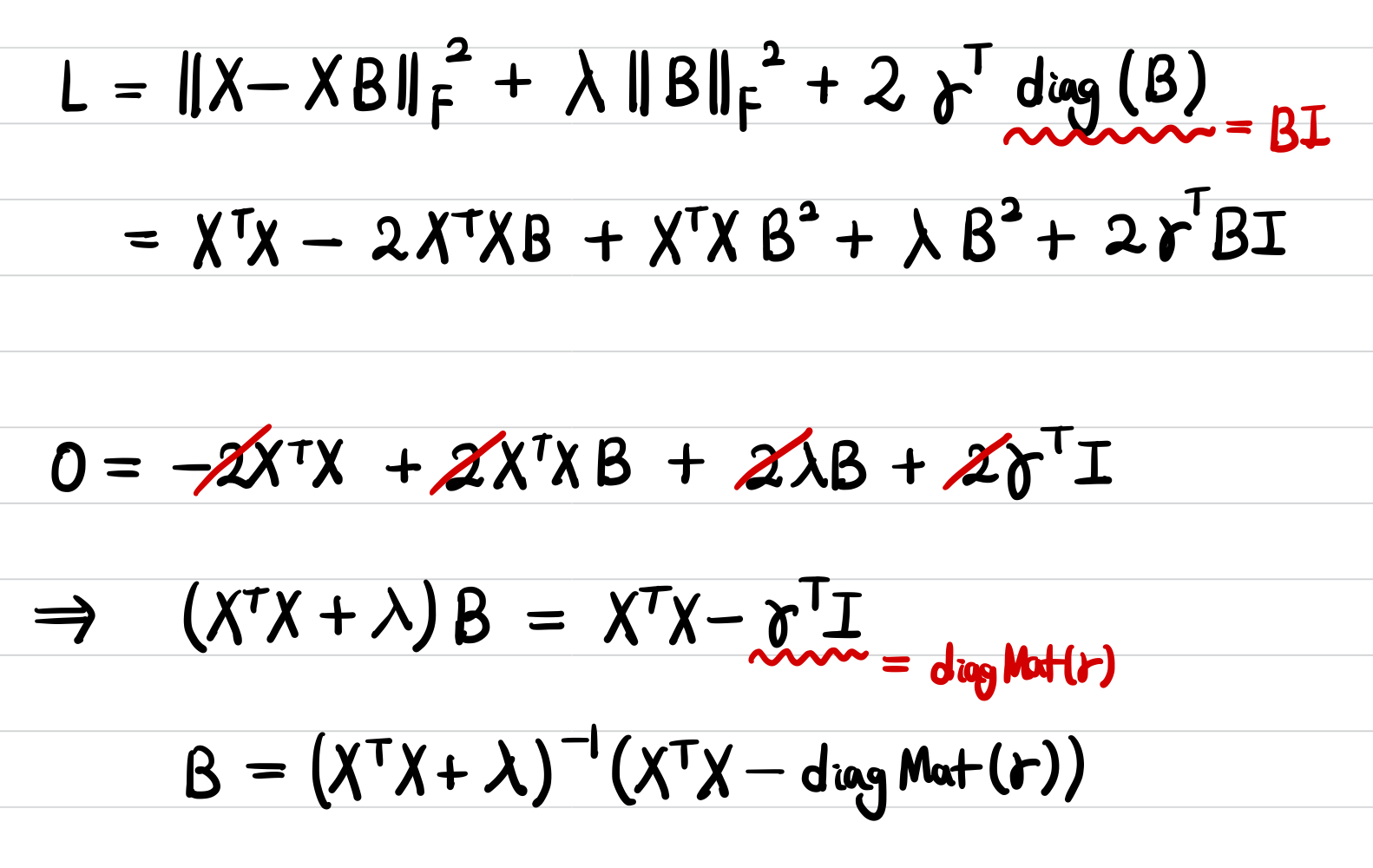
[행렬의 Norm의 제곱을 구하는 데 참고한 페이지]
Squared norm of matrix equal to squared norm of its transpose
With the definition of matrix norm as
math.stackexchange.com
[행렬의 Frobenius Norm 미분하는 방법]
https://math.stackexchange.com/questions/2128462/derivative-of-squared-frobenius-norm-of-a-matrix
Derivative of squared Frobenius norm of a matrix
In linear regression, the loss function is expressed as
math.stackexchange.com
이제 위의 식을 좀 더 깔끔하게 정리하기 위해 충분히 큰
위의 마지막 줄에서
여기서
이를 다시
학습되는 파라미터의 가중치인
만약에 앞에서
대각성분이 아닌 원소들은 모두
결국 입력 데이터에 의해
이
논문에서는 이 Gram-matrix가 co-occurrence matrix라고 말하는데, 이 co-occurrence matrix가 뭔지 싶어서 여러 군데를 찾아봤더니 NLP에서 주로 사용하는 개념이었다.
[NLP에서의 co-occurrence matrix]
자연어처리(NLP) 15일차 (GloVe)
2019.06.18
omicro03.medium.com
NLP에서는 어떤 한 단어와 함께 특정 단어가 몇 번 등장했는지를 나타내는 행렬로 정의하는데, 이 논문에서도 비슷하게 적용해볼 수 있다.
이 논문에서는
앞에서 들었던 예시를 다시 가져와서 적용해보면 좀 더 의미가 와닿을 것이다.
| 아이템 a | 아이템 b | 아이템 c | 아이템 d | |
|---|---|---|---|---|
| 유저 A | 0 | 1 | 1 | 0 |
| 유저 B | 1 | 0 | 1 | 1 |
| 유저 C | 0 | 0 | 0 | 1 |
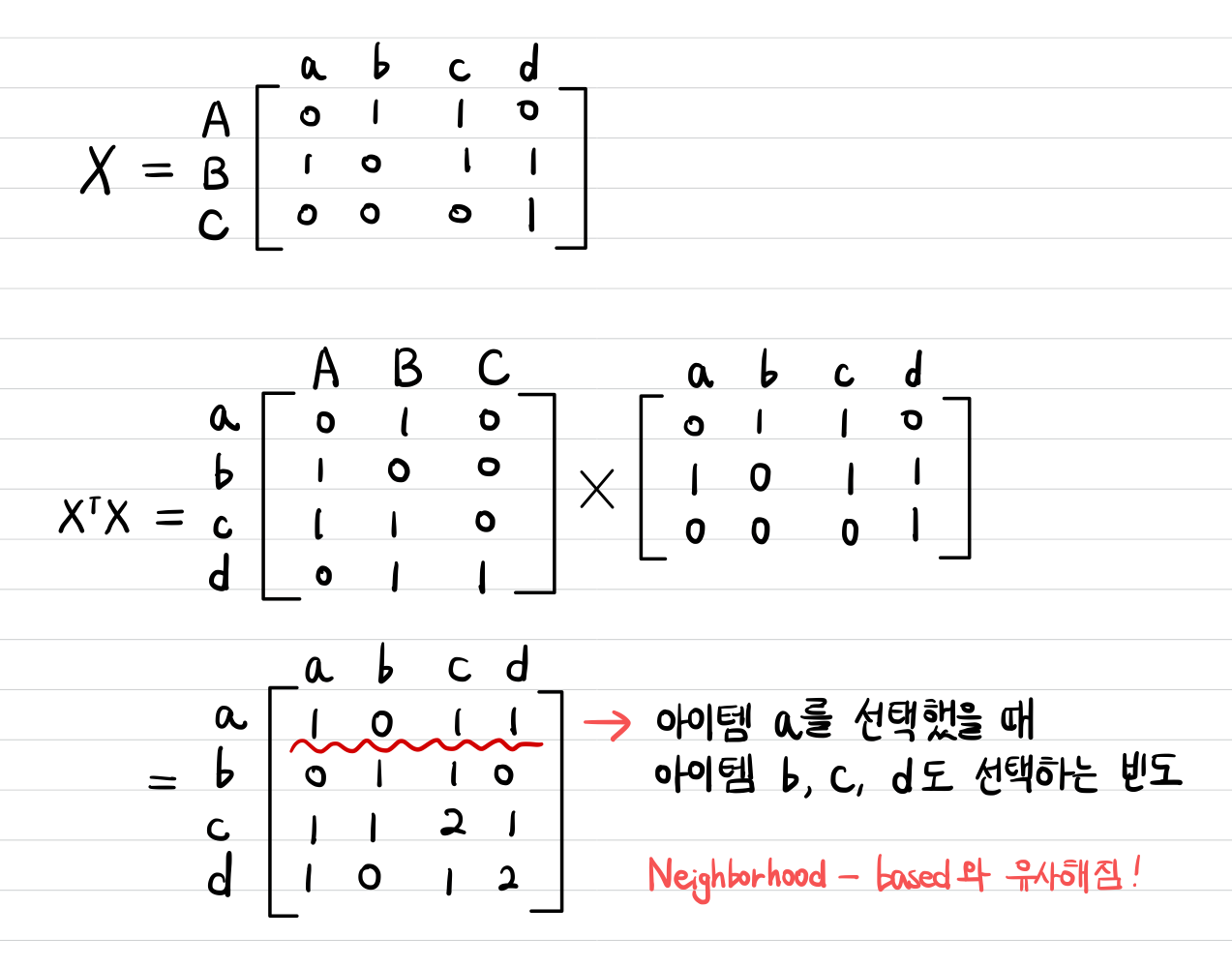
결국 co-occurrence matrix를 구하는 것이 아이템 간의 유사도를 구하는 Neighborhood-based Collaborative Filtering과 매우 유사함을 알 수 있는데, 논문에서도 기존의 Neighborhood-based 접근법의 한계를 지적하면서 EASE에서의 장점을 더 강조하고 있다. 이는 아래에서 소개할 것이다.
이 co-occurrence 계수인
또한 이 co-occurrence의 계수가 충분히 크면
Gram matrix와 EASE의 관계
흥미롭게도
- 활동량이 증가한 유저로 인해 더 밀도가 높아진 데이터
두 번째 요인에 주목해야 하는데, 이는 유저의 수가 증가하면 데이터의 sparsity가 어느 정도 보완될 수 있음을 시사하고 있다.
그래서 데이터에서 유저의 수가 충분히 크면
이것이 결론적으로 EASE가 왜 sparse한 데이터에 robust한 모델인지를 알려주는 핵심이라고 생각된다.
아이템이 유저보다 적으면 적을수록 연산 효율 증가
위처럼 목적함수를 최적화 하는 해를 구하는 것이 closed form solution이어서 굳이 딥 러닝을 사용할 필요 없이 단순 CPU로도 충분하여 컴퓨팅 자원이 적게 든다.
또한 파라미터를 업데이트하기 위해 결과적으로 유저와 아이템의 interaction 행렬인
학습 과정 구현
위의 내용을 종합하여 EASE 모델의 학습 과정을 코드로 구현하면 다음과 같다.
import numpy as np
# 딥 러닝 모델이 아니므로 nn.Module을 상속받을 필요가 없다.
class EASE:
def __init__(self, _lambda):
self.B = None
self._lambda = _lambda
def train(self, X):
G = X.T @ X # G = X'X
diag_indices = list(range(G.shape[0]))
G[diag_indices, diag_indices] += self._lambda # X'X + λI
P = np.linalg.inv(G) # P = (X'X + λI)^(-1)
self.B = P / -np.diag(P) # - P_{ij} / P_{jj} if i ≠ j
min_dim = min(*self.B.shape)
self.B[range(min_dim), range(min_dim)] = 0 # 대각행렬 원소만 0으로 만들어주기 위해
def forward(self, user_row):
return user_row @ self.B
입력 데이터에 관한 학습 과정은 매우 간단하다.
X = inputs # 학습 데이터
_lambda = 300
ease = EASE(_lambda)
ease.train(X)
이제 입력 데이터
result = ease.forward(X[:, :])
result[X.nonzero()] = -np.inf # 이미 어떤 한 유저가 클릭 또는 구매한 아이템 이력은 제외
주의할 점은 우리는
EASE와 다른 모델 간의 비교
Neighborhood-based CF 방법과의 비교
The closed form solution reveals that the inverse of the data Gram matrix is the conceptually correct similarity matrix.
위에서 구한 과정에서
EASE에 관하여 아직 더 정리해야 할 부분이 남아 있는데, 이는 추후에 계속 업데이트하여 완성할 예정이다.
EASE에 관하여 느낀 점
실제로 EASE 모델을 사용하면서 들었던 의문점이 있었는데, 우선 간략히 정리하고 추후에 글을 더 업데이트할 때 자세히 기록을 남길 예정이다.
- EASE의 입력 데이터에서 Positive feedback 값으로서 1이 아닌 0.9로 설정했더니 약간의 성능 향상을 경험할 수 있었다. 그런데 1보다 더 큰 값을 주면 오히려 성능이 낮아지는 것을 목격했다. 아마 positive feedback value가
- EASE를 이번 대회에서 사용했을 때 다른 모델에 비해 성능이 좋게 나왔던 것은 아무래도 대회에서 사용한 데이터가 sequential data가 아니라 중간 중간 빈 부분이 뚫려 있는 좀 더 sparse한 데이터에 가까워 cold start problem이 발생해서인 것으로 보인다.
코드 구현
RECJOON 프로젝트를 진행하면서 BOJ(백준 온라인 저지) 유저와 문제풀이 dataset을 가지고 EASE 모델을 통해 학습하고 inference을 수행하는 과정을 jupyter notebook으로 작성한 코드이다.
GitHub - Glanceyes/ML-Paper-Review: Implementation of ML&DL models in machine learning that I have studied and written source co
Implementation of ML&DL models in machine learning that I have studied and written source code myself - GitHub - Glanceyes/ML-Paper-Review: Implementation of ML&DL models in machine learnin...
github.com
출처
1. https://arxiv.org/abs/1905.03375
2. https://www.devchopin.com/blog/364
3. https://velog.io/@chwchong/Embarrassingly-Shallow-Autoencoders-for-Sparse-Data-ad26xu1w
4. https://xiaobaiha.gitbook.io/tech-share/machinelearning/embarassingly-autoencoder-suan-fa
5. https://www.kaggle.com/code/lucamoroni/ease-implementation
Contents
소중한 공감 감사합니다.