AI/CV
PIFu: Pixel-aligned Implicit Function을 사용하여 single image로부터 clothed human 3D model을 예측하는 모델
- -
사람을 촬영한 이미지만 사용하여 그 사람의 3D Human을 모델링하는 digitization은 metaverse의 AR, VR 등 다양한 사례에 응용하여 적용할 수 있다. 예를 들어, 우리 각자 개인의 selfi만을 사용하여 가상환경에서의 캐릭터를 바로 생성할 수 있는 것처럼 말이다. PIFu는 2D 이미지만을 input으로 받아서 implicit function을 학습하는 neural network를 통해 그에 대응되는 사람의 3D model을 reconstruction 할 수 있는데, naked body 뿐만이 아니라 옷과 악세사리를 착용한 모습도 기존에 제안된 방법들보다 높은 quality로 모델링할 수 있다. 이번 논문에서는 PIFu(PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization, Shunsuke Saito)에서 핵심이 되는 pixel-aligned implicit function을 자세히 알아보고, 그 외에 어떠한 방법을 논문에서 사용했는지 알아보려고 한다.
PIFu란?

PIFu는 end-to-end 방식으로 deep learning을 통해 옷을 입은 사람을 찍은 단일 이미지 또는 여러 방향에서 찍은 둘 이상의 2D 이미지만을 가지고 3D surface와 texture를 추론하여 그 사람을 표현하는 3D model을 예측할 수 있는 3D Human Digitization을 수행하는 모델이다. 즉, 3D space에서의 human model에 관한 정보를 주지 않고도 2D에서의 사람을 찍은 하나 혹은 여러 장의 사진만으로도 그 사람의 얼굴, 몸, 착용한 옷과 악세서리를 갖춘 3차원의 사람 모델로 reconstruction 할 수 있는 모델로 볼 수 있다.
Background
PIFu가 제안되기 이전에는 사람을 표현할 수 있는 parametric model을 구하거나 여러 데이터로부터 모델링하고자 하는 대상의 geometric 정보를 학습하는 data-driven technique이 많이 쓰였다. 즉, 이전에 학자들이 연구했던 사람의 몸과 움직임을 표현할 수 있는 어떠한 template model을 기반으로 이미지로부터 사람의 feature 또는 attribute를 추출해서 파라미터를 확률적으로 조절하는 방법으로 구현한 것이다. 사람의 체형, 자세 등 사람을 표현할 수 있는 정보에 관한 parametric model은 이제까지 적지 않게 연구되었고 사람을 좀 더 정확히 표현할 수는 있으나, 기본적으로 사람의 머리카락은 잘 표현하지 못하고 옷이나 악세사리를 착용하지 않은 naked-human body에 관해서만 섬세한 표현이 가능하다는 치명적인 단점을 지니고 있다. 또한 어디까지나 사전에 정의된 template을 사용하는 것이어서 general shape을 표현하거나 예측하는 데 있어서는 크게 두각을 보이지 못했다.
이를 극복하고자 deep learning을 사용하여 다양한 시도가 지속되어 왔지만, memory efficiency에서 좋은 결과를 보이지 못하거나 괄목할 만한 성능을 보이지 못하는 경우가 대다수였다. 첫 번째로 단순히 'fully-convolutional' network를 사용하는 architecture는 이미지와 3D domain의 output에서의 spatial alignment를 유지하는 데 어려움을 겪었다. (보통 2D 이미지를 convolutional layer 통과시켜서 해당 대상의 3D 정보를 얻는다는 건 쉬운 일이 아니다.) 두 번째로 3D space에서의 voxel-grid를 예측하는 voxel representation을 학습하는 방법이 있는데, 이는 2D 이미지로부터 사람의 체형이나 자세 등 필요한 정보를 추출하고 이를 바탕으로 3차원 공간에서 그 사람의 occupancy를 예측하는 것이다. 직접 voxel-grid를 예측하므로 표현력은 높아질 수 있으나 complexity가 cubic하게 늘어나므로 memory resource를 과도하게 사용해서 3D representation의 해상도를 높이는 것이 쉽지 않다. 이러한 memory efficiency를 보완할 수 있는 global representation을 사용하는 방법도 있지만, 이는 세밀한 정보를 학습하는 데는 어려움을 겪는다.
Multi-view 3D human digitization은 여러 방향에서 찍은 사람 이미지를 바탕으로 완전한 3D 사람 모델을 생성하는 접근인데, 이는 여러 방향에서 동시에 사람을 촬영할 수 있는 특수한 스튜디오 세팅이나 캘리브레이션된 여러 개의 카메라를 설치할 수 있는 공간이 요구된다. 그러나 이를 수행할 수 있는 넓은 공간이 필요하고 적지 않은 세팅 비용이 문제가 되어 flexibility 면에서 문제가 된다.. 또한 많은 수의 카메라를 사용하면 사용할수록 reconstruction의 성능은 높아질 수 있지만, 사람의 옷이 접히는 것처럼 오목한 부분에 관해서는 다루기 어렵다는 단점도 지니고 있다.
그래서 논문에서 저자는 pixel-algined implicit function을 사용하여 pixel level에서의 각각의 local feature를 전반적인 사람의 global context와 align 시킴으로써 과도한 memory resource 사용 없이 단지 하나의 2D image만으로도 섬세한 3D reconstruction을 수행할 수 있는 모델을 제안했다. 게다가 단순히 하나의 이미지만을 사용하는 것보다 여러 방향에서 찍은 복수 이미지를 사용해서 각각의 view point에 대응되는 latent feature를 구하여 이를 aggregation 하는 방법을 사용해서 보다 visual fidelity를 높이는 접근도 함께 제시했다.
Contribution
PIFu의 contribution을 요약하면 다음과 같다.
1. Template-based가 아닌 3D reconstruction에 관한 implicit function을 모델링하는 neural network를 사용했다.
2. Arbitray topology를 지니는 대상에 관해서도 pixel-aligned implicit function을 통해 detail을 보존하면서 보다 정확한 surface와 texture를 표현할 수 있다.
3. Voxel-grid를 global feature로 학습하지 않고 논문에서 제안한 spatial sampling 방법을 통해 3D world의 모든 point가 아닌 pixel과 align 되는 일부 샘플링된 3D point의 occupancy와 color를 예측하여 memory efficiency를 높일 수 있다.
Method
Pixel-aligned Implicit Function
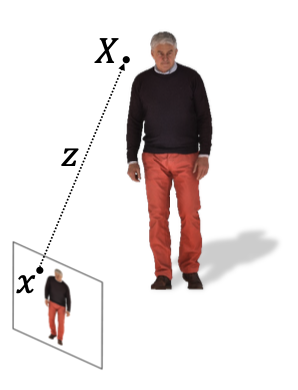
이 논문에서는 pixel-aligned implicit function이라는 함수를 학습하여 3D space 상에서의 occupancy와 color를 예측하는데, 우리가 하고자 하는 건 입력으로 주어진 2D 이미지를 encoder에 통과시켜서 그 image feature를 얻고, 그러한 feature를 occupancy field로 mapping 해주는 implicit function을 지니는 모델을 학습하는 것이다. 여기서 왜 implicit function에 'pixel-aligned'라는 이름이 붙은 이유를 이해하려면 논문에서 정의한 함수를 자세히 살펴 볼 필요가 있다.
위의 식에서 각각의 기호가 설명하는 바를 정리하면 다음과 같다.
즉, 우리는 2D 이미지만을 보고 3차원 공간 상에서 임의의 point
Occupancy를 예측하는 경우는
앞에서는 임의의 point
Pipeline
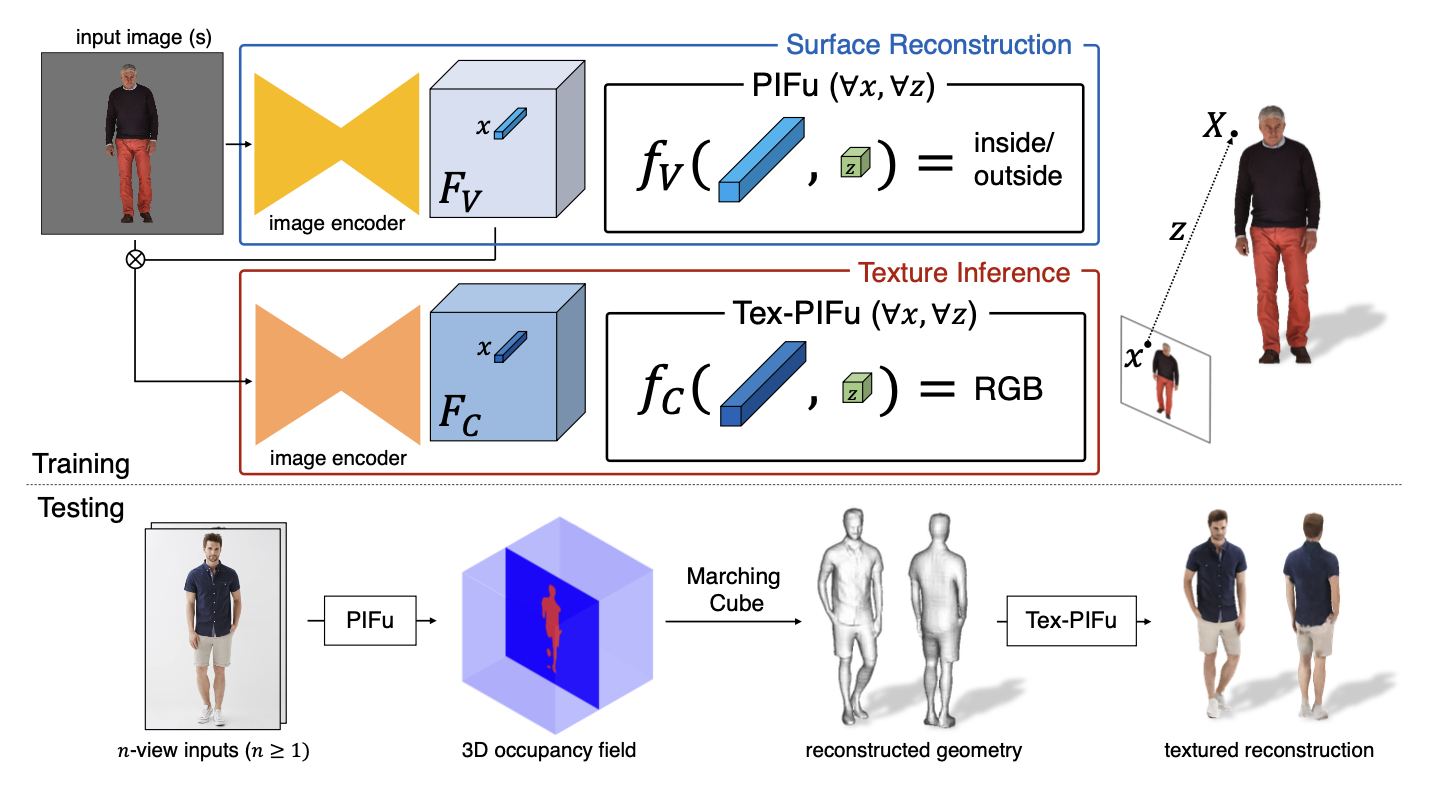
전반적인 파이프라인을 설명하는 그림을 보면 더 쉽게 이해할 수 있다. 먼저 3차원 상에 digitization 하려는 사람을 찍은 2D 이미지를 input으로 받는다. 이를 image encoder에 통과시켜서 image feature
앞선 부분까지는 occupancy를 예측하는 과정이었고, 이제 그 surface에서의 RGB color를 예측하는 texture inference도 수행한다. 여기서는 앞서 occupancy를 예측하는 방법과 유사한데, occupancy에서 사용한 것과는 다른 image encoder를 통해 image feature
테스트할 때는 test 대상의 human을 여러 방향에서 찍은
개괄적인 학습과 테스트 내용을 살펴봤고, 이제는 각각의 세부적인 구현 내용을 알아보고자 한다.
Details
Single-view Surface Reconstruction
위의 pixel-aligned implicit function에서 이미 3D occupancy field를 예측하기 위한 ground truth인
여기서
실제 occupancy 값은
Spatial Sampling
실제로 3D grid 상의 모든 point들을 뽑아서 예측하는 것은 불가능에 가깝고, 그중 일부만을 샘플링하여 iso-surface를 얻어야 한다. 논문에서는 sampling strategy가 최종적인 reconstruction quality에 큰 영향을 끼친다고 말한다. 예를 들어, 만약 3D space에서 uniform 하게 point를 샘플링 한다면 대다수의 sample point는 iso-surface에서 거리가 먼 점들일 텐데, 이러면 네트워크가 iso-surface가 아닌 그 바깥쪽에 관해 예측하는 데 가중치를 두게 되는 꼴이다. 반면에 너무 iso-surface 주위에서만 샘플링하면 모델이 overfitting 될 수 있다. 그래서 저자는 이 두 방법을 적절히 섞은 sampling strategy를 사용하고 있다고 설명한다.
Surface geometry 부근에서 뽑는 샘플과 uniform 하게 뽑은 샘플을 16:1 비율로 하는데, surface geometry 주위의 샘플을 봅을 때는 그 surface geomary 위에 존재하는 sample point들을 랜덤하게 뽑고, 거기에 평균이 0이면서 분산이
Texture Inference
Texture inference에서도 surface reconstruction에서와 유사한 절차로 수행한다. 대신 pixel-aligned implicit function에서 occupancy 예측에서는
그러나 실제로 위처럼 naive 하게 정의하면
여기서
Multi-view Stereo
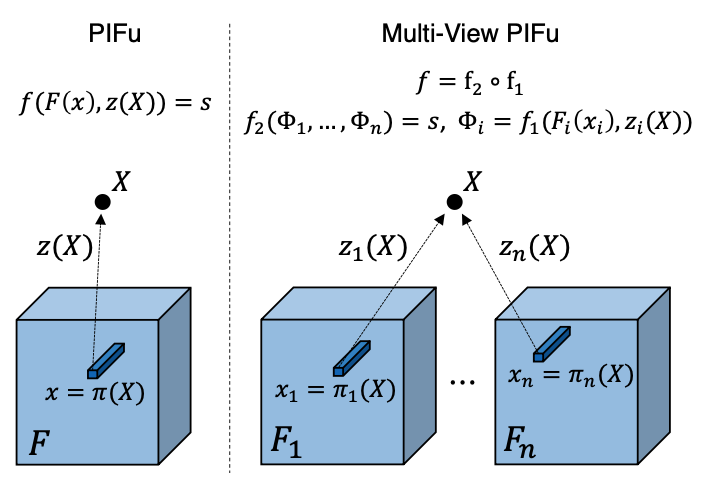
논문에서는 PIFu를 단순히 하나의 이미지만으로부터 뿐만이 아니라 다양한 viewing direction에서 촬영한 이미지를 사용하여 더 좋은 visual fidelity를 보일 수 있는 Multi-view PIFU 방법도 제안했다. 이를 위해 기존의 implicit function을 두 개의 네트워크로 decomposition 했는데, 하나는 featue embedding function
즉, 우리가 앞서 보았던 single-view surface reconstruction도 multi-view stereo의 일종으로 볼 수 있으며, 단일 이미지 뿐만이 아니라 다양한 view의 이미지를 사용하는 작업으로 확장할 수 있음을 내포한다.
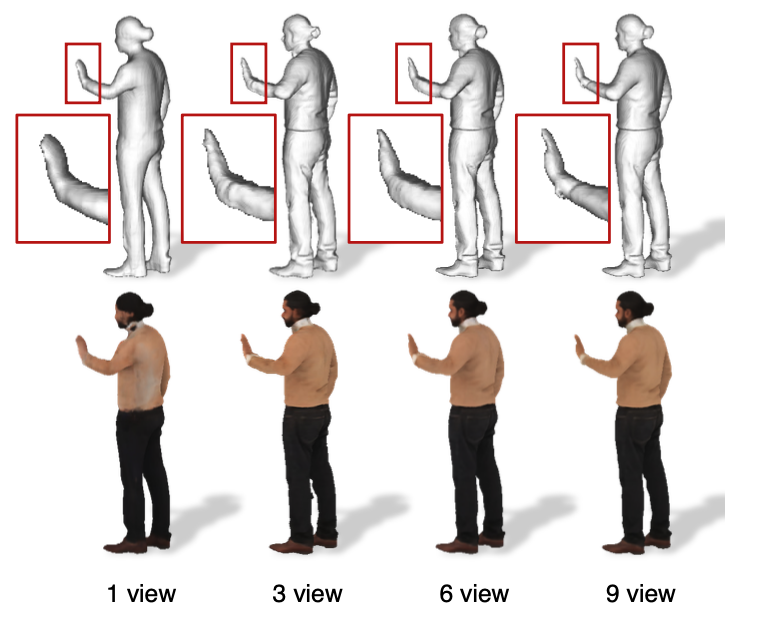
실제로 더 많은 view에서 찍은 이미지를 추가하면 추가할수록 더 좋은 reconstruction 결과를 낸다는 사실을 알 수 있다.
Experiments
논문에서는 PIFu의 reconstruction accuracy 관점에서의 우수성을 입증하기 위해 세 가지 metric을 사용했다. 첫 번째는 point-to-surface Euclidean distance(P2S)의 평균을 측정하는 방법이다. 이는 reconstructed surface에 위치한 point가 실제 ground truth에 얼마나 가까운지를 Euclidean distance로 구하는 것이다. 두 번째는 Chamfer distance인데, 이는 reconstruction 결과와 ground truth의 surface를 각각 이루는 point cloud 간의 거리를 거리를 계산하는 지표이다. 마지막은 normal reprojection error인데, reconstructed 3D model를 ground truth에 대응되는 2D 이미지에 projection 시켜서 norma map을 구하고, 그들의 차이를 L2 distance error로 구하는 것이다.
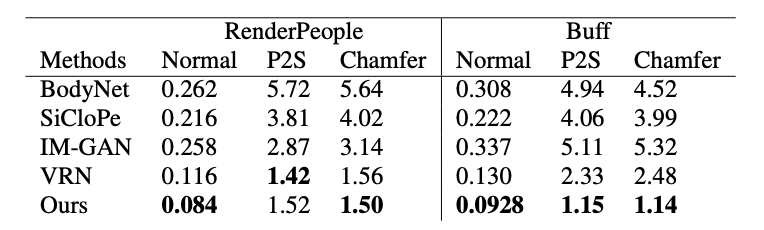
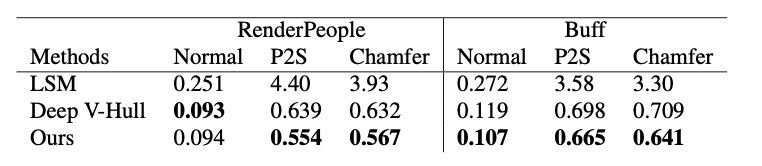
논문에서 정리한 실험 결과 표를 살펴보자. 위의 표는 single-view reconstruction을, 아래의 표는 multi-view reconstruction을 실행한 결과를 나타낸다. 이 실험에서는 RenderPeople과 Buff 데이터셋을 사용했고, Nomal(normal reprojeciton error), P2S(point-to-surface Euclidean distanc ), Chamfer(Chamfer distance) 값은 모두 작을수록 좋다. PIFu가 대다수의 지표에서 우수한 지표를 보이고 있다.

위의 그림은 PIFu를 포함한 여러 모델에 관해 single 이미지를 사용한 digitization 수행 결과와 실제 surface normal 간의 point-to-surface error를 시각화한 것이다.
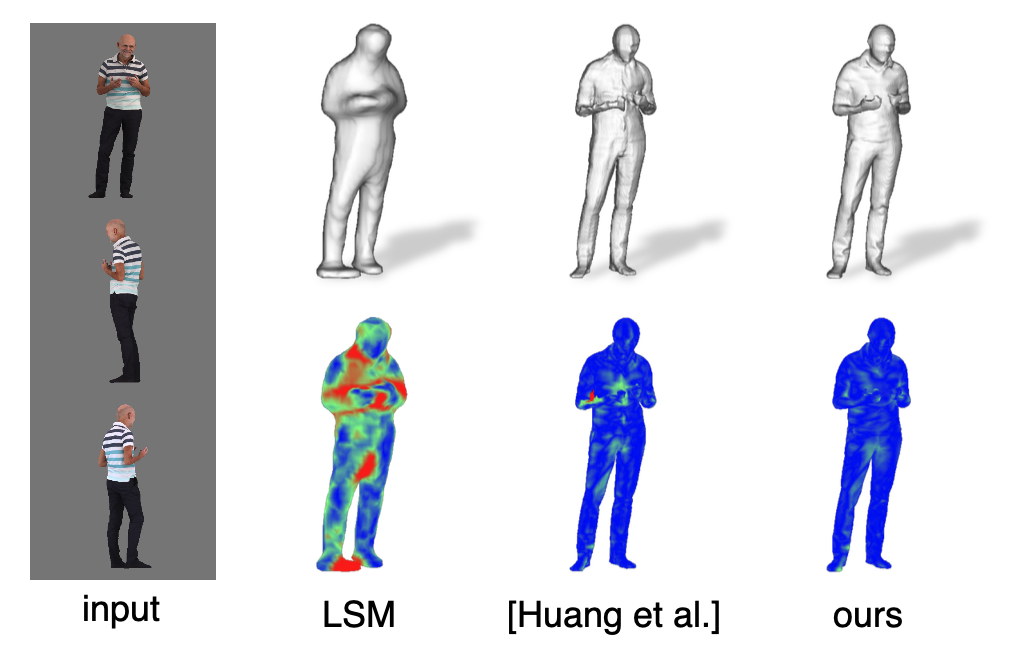
Template-based 방법뿐만이 아니라 neural network를 사용하여 학습하는 다른 learning-based 방법과도 비교했을 때 질적으로나 양적으로 모두 좋은 결과를 보이고 있다.
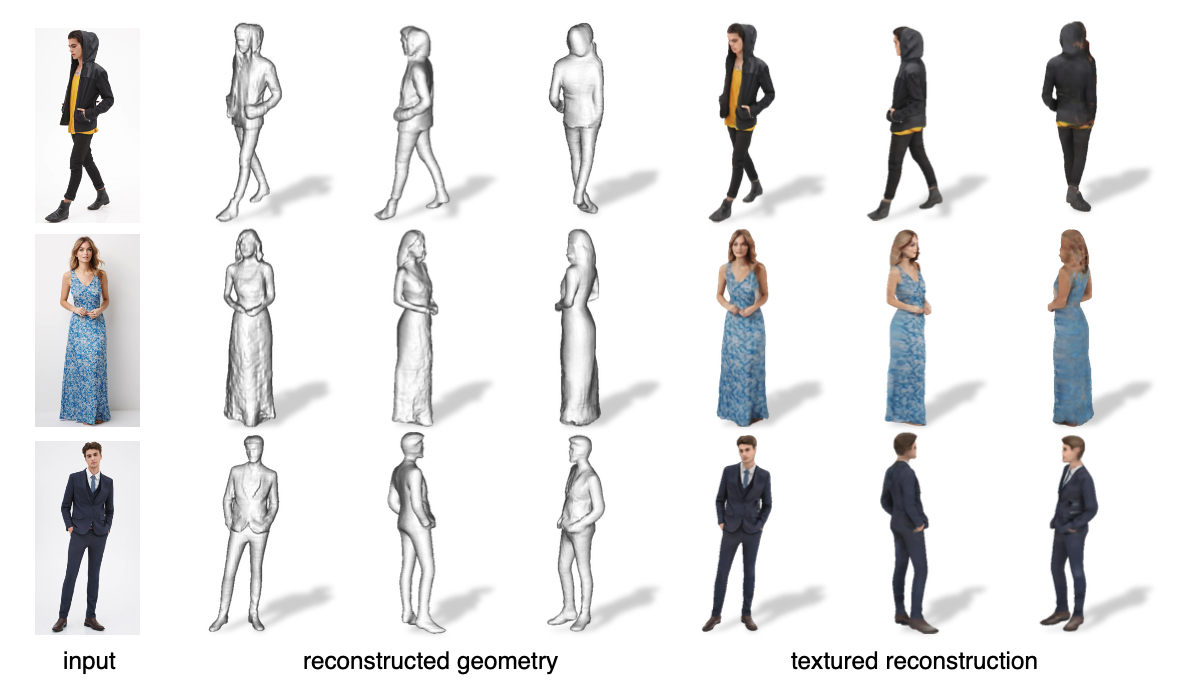
위의 그림은 DeepFashion dataset을 사용했을 때 real-image 샘플 데이터에 관해 single-view digitization 수행 결과인데, quality 면에서 surface 뿐만이 아니라 옷의 섬세한 texture도 잘 표현한다는 걸 확인할 수 있다.
Future Work
PIFu는 하나의 이미지 또는 여러 view 이미지로부터 옷 또는 악세서리를 착용한 사람의 3D model을 reconstruction 하면서 우수한 성능을 증명했지만, 다음과 같은 한계와 개선의 여지를 보여주고 있다.
1. 더 높은 해상도의 appearance로 reconstruction 하는 건 어렵다. 이는 GAN을 사용하거나 단순히 input image resolution을 높임으로써 해결할 수 있지 않을까 하고 저자는 추측했는데, 이점을 해결한 모델이 그 다음 연도에 PIFuHD로 제안되었다. 이에 관해서도 추후 리뷰를 해 볼 예정이다.
2. Reconstruction 수행 시 ground truth의 scale setting에 맞게 align 시켜야 한다는 것이다. 즉, 이미지를 촬영한 거리가 달라져서 카메라와 대상 사이의 거리가 달라졌을 때 분명 2D 이미지에서의 대상과 그 3D model의 크기도 변화하는데, 논문에서 제시한 방법으로는 이를 감안하여 reconstruction을 수행하기는 어렵다는 것이다. 이는 optimization 수행을 위해 정의한 objective function에서 ground truth와 prediction의 각 좌표가 일대일 대응된다고 고려하여 error를 계산했을 뿐, 두 모델의 scale이 다르면 이를 제대로 구할 수 없으며 그러한 scaling 요소를 추론하거나 학습하는 부분이 제시되지 않았다.
3. 이 논문에서 실험한 예시는 occlusion을 고려하지 않았다. 즉, real-world에서는 사람의 일부가 어떠한 물체에 의해 가려지는 경우처럼 unconstrained setting인 경우가 적지 않을 텐데, 이를 reconstruction 하는 데 있어서는 보장할 수 없다.
다음에는 좀 더 고해상도로 3D reconstruction이 가능한 PIFuHD(PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization)에 관해 알아볼 예정이다.
출처
1. https://shunsukesaito.github.io/PIFu/
Contents
소중한 공감 감사합니다.