AI/AI 실습
PyTorch RNN 모델 사용 예제 - AG NEWS 기사 주제 분류
- -
현재 활동 중인 빅데이터 연합동아리인 BITAmin에서 RNN에 관한 세션에서 발표를 진행했는데, 그때 Vanilla RNN 사용과 함께 PyTorch로 RNN을 사용한 모델을 구현하는 내용도 같이 강의하려고 실습 자료를 직접 만들었다. 네이버 부스트캠프 AI Tech에서 유명한 과제 중 하나인 '부덕이 🦆'에 매우 큰 영감을 받아서 이 발표 자료를 제작할 때도 코드 한 줄마다 빼곡히 주석을 넣었을 뿐만이 아니라 대화체로 연관 개념들을 마크다운으로 설명을 적어놓았다. 처음에는 필자인 나 자신도 자료를 제작하면서 고통스럽고 오글거리는 말투로 인해 반응이 좋지 않을까 많이 걱정했는데, 다행히 강의에서 동아리원들이 괜찮은 반응을 보여줘서 굉장히 뿌듯했던 것 같다.
사실 어떠한 발표 자료를 만들 때 개인적으로 발표 대본에만 집중한 채 정작 청중을 이해시키고 내용을 쉽게 전달하는 데는 소홀했었다. 소위 말해 '자신이 아는대로만 말하는' 그런 발표만을 표방했었다. 그런데 부스트캠프에서 내가 모르고 있던 PyTorch 지식을 학습하면서 고생하던 시기에 이러한 사고의 전환점을 맞게 되었다. 이미 캠퍼들 사이에서 유명하던 '부덕이'라는 과제를 처음 보았는데, '과제는 다 무미건조하다'라는 고정관념을 완전히 깨 부수어 줬다. 어떤 한 개념이 등장할 때마다 그에 관한 설명을 자세하게 써 놓았고, 심화된 내용을 참고할 수 있는 링크 자료를 첨부해 놓아서 학구열을 자극시켰다. 무엇보다 활기찬 기분으로 옆에서 과제를 설명해주는 '부덕이'의 글이 술술 읽혀서 과제하는 시간이 지루하지 않았다. 그래서 앞으로 '부덕이' 과제를 발표 자료의 롤 모델로 삼아서 모든 경우는 아니지만 적어도 자세한 설명을 요구하는 발표에서의 PPT 또는 실습 자료를 '부덕이' 스타일로 제작해야겠다는 다짐을 했다.
실제 발표 자료로 쓴 파일은 아래의 링크로 올려놓았다. 포스팅 목적에 맞게 일부 내용을 수정했지만, 업텐션인 말투는 그대로 두었다. (사실 부덕이의 핵심이자 인기 요인은 바로 이 업텐션 대화체라고 생각한다... 😅)
PyTorch 코드 자료 (Colab으로 실행하기)
https://drive.google.com/file/d/1HqSnvBnqSEEugKZEvg84pQLX3f2s-ebS/view?usp=sharing
PyTorch_RNN_실습.ipynb
Colaboratory notebook
drive.google.com
(아래 포스트 내용 어체가 오글거릴 수 있는 점 양해바랍니다. 🙇🏻)
이번 포스팅에서는 RNN을 사용하여 순차 데이터의 label을 예측해볼 거에요.
여기서는 Tensorflow가 아니라 PyTorch를 사용하므로, 관련 모듈 또는 라이브러리가 설치되어 있어야 합니다.
Colab 환경에서는 별개의 설치 과정이 요구되지 않아서, 로컬 또는 서버에 설치하는 과정이 번거롭거나 불편하신 분들은 colab을 사용하시기를 권장드려요!
# 설치가 필요하신 분들만 실행해주세요.
# conda로 가상환경 인터프리터를 사용하시는 분들은 conda 가상환경에 맞게 설치해주시면 됩니다.
# (예) conda install pytorch torchvision
!pip install torch
!pip install torchtext
!pip install tqdm
!pip install numpy
!pip install pandasimport os
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torchtext
from tqdm.notebook import tqdm_notebook
from torch.utils.data import Dataset, DataLoader, random_split
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
RNN을 사용하여 뉴스 주제 분류하기 📰
순차 데이터를 학습하는 모델을 제작하려면 그에 맞는 데이터가 필요하겠죠? 우리는 torchtext.dataset에서 기본적으로 제공하는 AG_NEWS 데이터 셋을 사용할 거에요.
AG_NEWS Data Set은 뭔가요?
AG_News 데이터는 100만 개가 넘는 뉴스 기사를 모아놓은 것인데요.
ComeToMyHead가 1년 넘게 활동하면서 2,000개 이상의 출처에서 뉴스 기사를 수집하여 만든 것이라고 하네요.
ComeToMyHead는 학술 기사 검색 엔진인데, 20004년 7월부터 운영되어 왔습니다. 자세한 내용은 링크에서 확인해 보세요.
왜 뉴스 기사를 사용한 건가요?
뉴스 기사도 순차 데이터의 일종이라고 볼 수 있어요.
기사는 여러 문장이 모여서 하나의 주제를 담고 있는데, 이 문장의 순서가 주제를 예측하는 데 있어서 중요한 요인이 될 수 있죠.
참고 자료
이 링크는 포스팅을 제작하는 데 있어서 참고한 자료입니다.
사실 참고 자료에서는 Linear Layer로만 모델을 제작해서 RNN을 사용하는 실습에 억지로 끼워 맞춰서 자연스럽지 못한 점이 있는데, 이점 양해 부탁드려요. 🥺
또한 위의 자료에서는 Custom한 Dataset, Validation 과정이 없는데, 저희 실습에서는 PyTorch를 경험해보기 위해 이 코드를 새로 작성하여 추가했습니다.
# 불러온 데이터를 저장할 위치를 지정해주세요.
data_dir = './data' # TODO
split 파라미터는 무엇인가요?
AG_NEWS는 학습을 위한 train 데이터, 학습한 모델을 테스트하기 위한 test 데이터 두 가지가 있어요.
우선 데이터가 어떤지를 파악해야 하므로 둘 중 아무거나 하나 가져오도록 할게요!
dataset = torchtext.datasets.AG_NEWS(root=data_dir, split='train')
next()? iter()? 이건 뭔가요? 🤔
Python에는 iterable object라는 게 존재해요.
말 그대로 반복할 수 있는 객체라는 의미인데요.
iter() 메소드는 불러온 dataset을 반복할 수 있는 객체로 새로 만들겠다는 뜻이죠.
그러면 이 새로운 객체는 한 시점에 element라는 요소 하나를 반환할 수 있게 됩니다.
next() 메소드는 순서대로 다음 요소를 하나 불러오겠다는 의미입니다.
즉, 우리가 이를 호출한 이유는 데이터 셋의 맨 처음 요소가 어떻게 되어있는지를 확인하기 위해서죠.
next(iter(dataset))출력 결과
(3,
"Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again.")
dataset의 가장 첫 번째 요소를 불러왔더니, 숫자와 긴 문장의 텍스트가 나오네요.
텍스트에서 'wall', 'bears', 'claw', 'back'이라는 단어, 뒤에서 한 번 더 나오니까 잘 기억해두세요!
텍스트가 기사 내용인 건 알겠는데, 앞의 숫자는 뭔지 잘 모르겠어요... 🤔
이 실습이 뉴스 기사를 분류하는 걸 목표로 한다고 했으니, 아마 그 분류의 레이블을 숫자로 나타낸 게 아닌가 싶어요.
한 번 확인해 볼까요?
1 : World (세계) 2 : Sports (스포츠) 3 : Business (경제) 4 : Sci/Tec (과학/기술)
이 데이터의 분류는 4개의 문자열로 된 레이블로 존재한다는 걸 알았어요.
그러면 저 3이라는 의미는 위의 리스트에서 세 번째 원소에 해당되는 'Business' 주제 기사임을 나타낸다는 것이네요.
그래서 문장에서 'Short-sellers'라는 말이 나오는 등 비즈니스 주제 분위기를 물씬 풍겼군요... 😮
잠깐만요, 그런데 과연 AI 모델이 텍스트를 학습해서 수학적으로 최적의 파라미터 값을 구할 수 있을까요?
텍스트는 수가 아니라 문자열이잖아요.
컴퓨터는 텍스트를 바로 해석할 수 있는 휴먼(👤...)과는 다릅니다.
그러면 이 텍스트를 수로 바꿔야하지 않을까요...? 🤔
문장 전체를 수로 변환하는 건 무리인 것 같고, 문장 자체도 여러 단어로 된 순차 데이터이니까 단어 자체를 수로 나타내면 어떨까요?
그러면 그전에 텍스트 문장을 단어 단위로로 쪼개야겠네요.
그래서 단어로 쪼개기 위해 필요한 도구를 소개할게요!
하나의 단어장 구축하기
여러분, 외국어 공부할 때 단어장 많이 사용하시나요?
필자는 영어를 잘 하지 못해서 모르는 단어가 나오면 단어장을 자주 찾아보는데요... 🥲
AI 모델에게도 단어장이 필요합니다!
텍스트는 수가 아니라 문자열이니, AI 모델이 해석할 수 있도록 텍스트에 대응되는 수를 찾아주는 단어장 말이죠.
그러면 AI 모델을 위한 단어장을 만들어볼까요? 😆
※ 단어장은 고차원의 벡터를 저차원의 벡터로 임베딩하기 위해 미리 앞서 plain한 텍스트를 unique한 고차원의 벡터로 변환시키는 작업을 수행하기 위해 사용합니다.
Tokenizer
tokenizer는 말 그대로 텍스트 문장을 단어라는 token(토큰) 단위로 쪼개주는 역할을 하는 도구입니다.
우리는 학습 데이터에서 문장을 쪼개서 나온 단어로 단어장을 만들고, 이를 AI 모델에게 학습시키려고 해요.
tokenizer를 직접 구현할 수도 있지만, 이미 정의되어 있는 걸 가져오는 게 편할 거 같아요.
다행히 torchtext.data.utils 모듈에 이미 구현된 tokenizer가 있다네요.
우리의 학습 데이터는 영어로 되어 있으므로, 'basic_english'라는 인자를 넘겨서 가져와볼게요.
tokenizer = get_tokenizer('basic_english')
tokenizer('I love you!')출력 결과
['i', 'love', 'you', '!']
가져온 tokenzier에 예시 문장을 넣었더니 역시 단어별로 잘 쪼개는 걸 확인할 수 있네요!
tokenizer는 문장을 단어 단위로 쪼개주는 역할도 하지만, 문자 자체를 소문자로 바꿔주는 역할도 하는 걸 볼 수 있어요.
그럼 앞에서 우리가 가져온 dataset의 요소는 label과 텍스트로 되어 있었는데요.
이를 for loop으로 돌면서 텍스트만 뽑아서 tokenizer에 넘겨주면 쪼개진 단어의 리스트를 받을 수 있겠네요!
이는 yield_tokens라는 함수로 직접 구현해봅시다.
def yield_tokens(data):
for _, text in data:
yield tokenizer(text)
이제 AI 모델을 위한 단어장을 만들어 볼게요.
단어장을 만드는 건 쉽지 않은 일이니까... 미리 구현된 것을 가져와 사용해볼까요?
위에서 tokenizer를 사용하여 데이터를 단어로 쪼개주는 yield_tokens 함수를 가지고 다음과 같이 만들 수 있어요. 😁
vocab = build_vocab_from_iterator(yield_tokens(dataset), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])
"<unk>"는 뭘까요?
크게 중요한 건 아닌데, 단어장에 찾고자 하는 단어가 없으면 유효한 단어가 없다는 뜻에서 'UNKNOWN'을 의미하는 태그라고 해요.
앞으로 테스트 데이터를 가지고 모델을 검증할 때, 학습 데이터를 가지고 만든 단어장에 모든 단어가 있다는 보장이 없잖아요.
그래서 대응되는 단어를 찾지 못하면 "응, 몰라~ 🤪" 하고 반환해주기 위한 것입니다.
그러면 dataset의 맨 첫 번째 요소의 텍스트에 있던 'wall', 'bears', 'claw', 'back' 단어가 과연 우리가 만든 단어장에도 잘 존재하는지 확인해볼까요?
vocab(['wall', 'bears', 'claw', 'back'])출력 결과
[431, 1607, 15333, 113]
vocab() 함수에 찾기를 원하는 단어 데이터를 넘기니까 해석 불가능한 수(Number)가 나왔어요.
단어장이 어떠한 규칙으로 단어에 대응되는 수를 만드는지는 모르겠지만, 그래도 한 단어마다 대응되는 하나의 수만을 갖는 걸 예상해볼 수 있겠네요.
단어장도 만들었으니, 이제 본격적으로 앞에서 불러온 데이터 셋을 가지고 모델 학습에 필요한 Dataset 클래스를 만들어볼까요?
def text_preprocess(x):
return vocab(tokenizer(x))
그전에 text_preprocess()라는 함수를 정의해서 텍스트 데이터를 입력받을 때 단어장에 의해 번역된 수의 리스트로 변환해주는 걸 간단하게 실행하려고 해요.
def label_preprocess(x):
return int(x) - 1
label_preprocess(x) 함수는 사실 큰 의미는 없어요.
단지 label이 1부터 4까지 정수로 존재하는데, 이를 0부터 시작하도록 바꾸려고 해요.
Python도 어찌 보면 zero-based numbering이니까요.

Dataset 만들기
와, 이제 본격적으로 우리만의 데이터 셋을 만들 차례에요! 🤩 앞에서도 데이터를 간단한 메소드로 불러올 수 있었지만, 그냥 불러오는 것보다는 직접 만들어 보는데 의미를 두려고 해요. 피곤하고 귀찮으시겠지만😫, 그래도 이해하면 재미를 느끼실 수 있을 거에요!
앞에서 데이터를 불러와서 저장하신 거 기억 나시나요?
그 디렉토리 위치에서 필요한 데이터를 가져와 볼게요.
그전에 우리가 학습용 데이터만 불러왔으니 테스트용 데이터도 불러와서 저장 해야겠네요.
dataset = torchtext.datasets.AG_NEWS(root=data_dir, split='test').
└── data
└── AG_NEWS
├── test.csv
└── train.csv
데이터를 모두 가져오면 데이터를 저장한 위치의 디렉토리 구조는 위와 같이 되는데요.
train.csv는 학습용 데이터, test.csv는 테스트용 데이터가 저장된 파일이에요.
BASE_AG_NEWS_PATH = data_dir + '/AG_NEWS'
TRAIN_AG_NEWS_PATH = os.path.join(BASE_AG_NEWS_PATH, 'train.csv')
TEST_AG_NEWS_PATH = os.path.join(BASE_AG_NEWS_PATH, 'test.csv')
Dataset이란?
우리가 학습할 모델의 입력으로 주어지는 데이터의 형태와 접근 방식을 정의하는 클래스이에요.
이렇게 얘기하면 잘 와닿지가 않지만, 우리가 하고 있는 실습을 예시로 들어볼게요.
앞에서 언급한 것처럼 컴퓨터(💻)의 일종인 AI 모델은 텍스트를 그대로 학습할 수 없어요.
그래서 AI 모델이 텍스트를 단어 단위로 쪼개서 해석할 수 있도록 단어장을 만들었던 것 기억하시나요?
이처럼 모델이 데이터를 잘 읽고 소화할 수 있도록 먹이를 만들어주는 feeding 역할을 하는 클래스로 이해하시면 돼요!
그러면 이번 실습에서 앞에서 정의한 텍스트를 단어에 대응되는 수의 리스트로 바꿔주는 작업을 Dataset 클래스에서 진행해주면 되겠네요.
그렇다고 무작정 처음부터 아무것도 없이 Dataset을 정의하기는 어렵잖아요.
다행히 PyTorch에서는 torch.utils.data라는 모듈을 통해 Dataset의 기능을 이용할 수 있도록 해줘요.
그래서 아래의 코드를 보면 CustomDataset을 정의할 때 torch.utils.data에서 import한 Dataset을 상속받고 있네요.
CustomDataset은 단순히 우리가 만들 Dataset의 클래스 이름이어서 큰 의미는 없어요.
다른 Dataset을 정의할 때 본인이 원하는 클래스명으로 정의하면 돼요.
나머지는 코드를 보면서 말씀드릴게요! 😌
주석을 참고하며 코드를 이해해주세요.
# CustomDataset을 정의할 때 torch.utils.data에 정의된 Dataset을 상속받습니다.
class CustomDataset(Dataset):
# CustomDataset의 생성자를 지정합니다.
# CustomDataset 클래스의 인스턴스를 만들 때 자동으로 호출됩니다.
def __init__(self, path: str ='./data/AG_NEWS/train.csv', train=True):
tqdm_notebook.pandas(desc="PROGRESS>>")
# 인스턴스로 자주 사용할 변수들을 정의합니다.
# `.csv` 파일을 읽어올 때 '클래스(레이블)', '제목', '설명' 컬럼 데이터로 읽어와 data 멤버 변수에 저장합니다.
self.data = pd.read_csv(path, sep=',', header=None, names=['class','title','description'])
# 현재 Dataset이 학습용인지 테스트용인지를 저장합니다.
self.train = train
# 불러올 `.csv` 파일의 경로를 저장합니다.
self.path = path
# '제목'과 '설명' 컬럼을 합쳐서 학습할 데이터로 지정합니다.
data = self.data['title'] + ' ' + self.data['description']
# 모델에 학습할 데이터를 X로 지정하여 저장합니다.
self.X = list()
# '제목' + '설명' 데이터를 한 줄씩 읽으면서 데이터 X에 넣어줍니다.
for line in data:
self.X.append(line)
# 데이터의 레이블을 y에 저장합니다.
self.y = self.data['class']
# dataset.classes를 출력하면 현재 데이터의 분류 레이블의 의미가 무엇인지 알 수 있도록 합니다.
self.classes = ['World', 'Sports', 'Business', 'Sci/Tech']
# len(dataset)을 호출하면 데이터 셋의 크기(길이)를 반환해줍니다.
def __len__(self):
len_dataset = None
len_dataset = len(self.X)
return len_dataset
# dataset[idx]처럼 인덱스로 dataset에 접근했을 때 해당 인덱스(idx)에 있는 데이터를 반환할 수 있도록 합니다.
def __getitem__(self, idx):
X,y = None, None
X = self.X[idx]
if self.train is True:
y = self.y[idx]
# idx번째 있는 데이터를 (레이블, 텍스트)로 반환합니다.
return y, X
# 이런 형태 어디서 많이 보지 않으셨나요?
# 위에서 next(iter(dataset))을 출력했을 때 반환되는 형태와 똑같습니다.
# 결국 우리가 하고자 하는 건 위에서 사용했던 dataset을 따라서 직접 구현해보는 것과 같습니다.
# 학습 데이터와 검증 데이터를 분리할 때 사용합니다. val_ratio는 검증 데이터를 분리할 비율 값을 의미합니다.
def split_dataset(self, val_ratio = 0.2):
data_size = len(self)
val_set_size = int(data_size * val_ratio)
train_set_size = data_size - val_set_size
# torch.utils.data의 random_split 메소드를 사용하여 데이터를 원하는 크기로 분리할 수 있습니다.
train_set, val_set = random_split(self, [train_set_size, val_set_size])
# 앞의 건 학습 데이터, 뒤의 건 검증 데이터로 반환합니다.
return train_set, val_set
Dataset과 DataLoader의 flow chart를 보면서 이해해볼까요?
밑의 flow chart의 Dataset 부분을 참고해주세요!
저기서 Dataset의 __init__, __len__, __getitem__을 위에서 직접 구현한 것이네요.
여기서 각 메소드의 기능을 다시 정리할게요.
- __init__(): 초기 데이터를 어떻게 불러오고 생성하는지를 지정합니다.
- __len__(): 데이터의 전체 길이를 반환합니다.
- __getitem__(): index 값에 위치한 하나의 데이터를 불러올 때 어떻게 반환할 것인지를 정의합니다.
이제 학습 데이터 셋의 객체를 생성하고, 이를 진짜 모델에 학습할 데이터 셋과 검증용으로 사용할 데이터 셋으로 분리하겠습니다.
CustomDataset 클래스에서 정의한 split_dataset을 가지고 (학습용 데이터 셋):(검증용 데이터 셋) = 8:2로 분리하려고 해요.
dataset = CustomDataset(TRAIN_AG_NEWS_PATH, train=True)
train_dataset, val_dataset = dataset.split_dataset(0.2)
학습 데이터 셋인 train_dataset과 검증 데이터 셋인 val_dataset이 어떻게 생겼는지 궁금하네요.
앞에서 사용한 next(iter())를 사용해서 확인해볼게요.
next(iter(train_dataset))출력 결과
(3,
'Windows Users Want Results, Not Ballmer Promises ORLANDO, Fla.Windows users said actions speak louder than words when it comes to Microsoft CEO Steve Ballmer #39;s promise that Microsoft will fix the various security vulnerabilities in his company #39;s computing platform.')'NBA' 단어가 나오는 것보니까 역시 레이블 2인 스포츠 관련 기사임을 알 수 있네요. 🏀
next(iter(val_dataset))출력 결과
(1,
"India says U.S. lifts nuclear, space export curbs (Reuters) Reuters - India said on Saturday the United States had lifted export restrictions on equipment for India's commercial space programme and nuclear power facilities, opening the way for greater cooperation in the two sectors.")
'Stocks', 'investors' 단어가 나오는 것 보니 역시 레이블이 3인 비즈니스 관련 기사임을 알 수 있어요. 🏢
len(train_dataset), len(val_dataset)출력 결과
(96000, 24000)
CustomDataset에서 __len__ 메소드로 정의했던 것을 여기서 len()으로 호출해서 사용했어요.
학습 데이터 셋의 길이는 96000, 검증 데이터 셋의 길이는 24000인 걸 알 수 있네요.
text_preprocess(train_dataset[0][1])출력 결과
[314,
332,
915,
521,
3,
62,
3205,
2586,
2803,
3,
1631,
1,
314,
332,
26,
4360,
5237,
47631,
72,
2356,
90,
25,
1100,
4,
77,
591,
1162,
3205,
12,
9,
3127,
17,
77,
33,
2672,
2,
4199,
99,
4467,
7,
32,
54,
12,
9,
1898,
1694,
1]
이 무시무시한 수는 뭐죠? 😖
앞서 정의한 text_preprocess() 함수 기억하시나요?
train_dataset에서 가장 앞에 있는 데이터의 텍스트를 단어장으로 번역한 것인데요.
그래서 'NBA ROUNDUP Recovering Hill Powers ~' 문장을 AI 모델이 이해할 수 있도록 해석한 것이라고 볼 수 있어요.
여기서 또 중요한 건 train_dataset의 가장 앞쪽의 데이터를 접근할 때 인덱스를 사용한 것인데요.
마찬가지로 앞서 CustomDataset에서 정의한 __getitem__() 함수를 사용한 결과입니다.
그래픽 카드 사용하기 🧑🏻💻
머신러닝, 딥러닝은 연산을 위해 많은 컴퓨팅 리소스를 요구한다고 알려져 있습니다.
이때 CPU보다는 병렬 처리에 유리한 NVIDIA 그래픽 카드를 이용하면 학습과 검증을 빠른 속도로 진행할 수 있어요.
그러기 위해서는 데이터, 모델 등을 그래픽카드에 올려놓을 수 있어야 하는데요.
아래는 이를 올려놓을 장치를 지정하기 위한 코드입니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")Colab에서 런타임의 런타임 유형 변경을 선택하시면 CPU 대신 GPU로 실행할 수 있습니다.
이 포스트의 코드는 많은 연산을 요구하지는 않으므로 CPU를 사용하여 진행해도 상관 없습니다.
대신 GPU를 이용할 수 있으면 "cuda"라고 뜹니다.
DataLoader 설정하기
모델이 소화할 수 있도록 먹이로 줄 데이터는 만들었는데, 이걸 어떻게 먹여야 할지는 잘 모르겠네요. PyTorch에서 제공하는 DataLoader로 모델에게 먹이를 주는 "수저"를 만들어봅시다.
DataLoader란?
데이터를 모델에 입력으로 넣을 때 batch 단위로 가공하여 입력으로 넣어주는 클래스입니다.
다시 말하면, 데이터를 batch 단위로 잘게 썰어서 모델에게 학습시키는 것입니다.
그런데 왜 전체 데이터를 입력으로 한 번에 넣지 않고 batch 단위로 잘게 썰어 주는 것일까요?
한 번에 모든 데이터를 학습하는 것보다는 batch 단위로 학습을 진행하는 것이 리소스를 절약할 수 있어서 학습 시간을 줄일 수 있어서입니다.
음식도 한 번에 모두 먹으면 체할 수 있듯이 말이죠. 🤮
batch_size = 8
collate_fn이란?
우리가 글을 읽고 쓸 때도 알 수 있듯이 텍스트의 문장 길이가 항상 일정하지는 않다는 걸 아실 거에요.
그런데 모델에게 학습 데이터를 입력하려면 일정한 길이로 먹여줘야 되는데요.
그래서 collate_fn 파라미터에 원하는 함수를 지정해서 batch로 묶일 데이터를 잘 묶어줄 수 있도록 해야 합니다.
주로 데이터가 가변적일 때 collate_fn 파라미터를 사용한다고 하네요.
데이터의 길이가 가변적일 때 이를 해결하기 위한 방법에는 두 가지가 있습니다.
하나는 패딩(padding)을 주어서 부족한 길이를 일정한 값(예: 0)으로 채워서 batch를 일정한 길이로 맞춰주는 방법이구요.
다른 하나는 batch의 길이를 맞추지는 않지만 offset을 이용해서 문장이 어떻게 끊기는지 그 위치를 지정해 주는 방법입니다.
이럴 경우 나중에 모델에서 EmbeddingBag를 사용하여 해결하는데, 좀만 기다렸다가 만나보도록 합시다.
이번 포스트에서는 후자를 사용해서 문장이 시작되는 위치를 offsets이라는 변수로 만들어서 반환하도록 할게요.
def collate_batch(batch):
labels, texts, offsets = [], [], [0]
for (label, text) in batch:
# 레이블의 값을 1만큼 줄여서 모델의 입력 데이터로 넘깁니다.
# 앞에서 zero-based numbering으로 시작하는 것을 반영한 것이죠.
labels.append(label_preprocess(label))
# 텍스트를 단어장으로 번역된 수의 리스트로 바꾸고, 이를 다시 tensor 자료형으로 바꿉니다.
# PyTorch에서는 기본적으로 tensor 자료형으로 모델을 학습시키거든요.
processed_text = torch.tensor(text_preprocess(text), dtype=torch.int64)
texts.append(processed_text)
# Batch 크기를 일정하게 맞췄지만, 이렇게 될 경우 각 문장의 시작 위치가 어떤지는 알 수 없습니다.
# 그래서 offsets에 각 문장의 시작 위치를 저장할 수 있도록 합니다.
offsets.append(processed_text.size(0))
# 레이블과 offsets 모두 모델이 소화할 수 있도록 tensor로 바꿔줍니다.
labels = torch.tensor(labels, dtype=torch.int64)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
# tensor로 변환된 텍스트를 하나로 합칩니다.
texts = torch.cat(texts)
# 레이블, 변환된 텍스트, 오프셋 시작 위치 3가지를 반환하도록 합니다.
return labels.to(device), texts.to(device), offsets.to(device)
# 학습 데이터의 Data Loader와 검증 데이터의 Data Loader를 각각 설정합니다.
# collate_fn 파라미터에 위에서 정의한 batch 적용 함수를 넘겨줍니다.
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_batch)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_batch)
torch.utils.data에서 가져온 DataLoader로 데이터 셋을 가지고 먹이를 줄 방법을 지정해 줬는데요.
이 DataLoader은 개발자를 위한 다양한 옵션들을 제공해주고 있습니다.
여기서 shuffle은 데이터를 배치 단위로 만들어서 무작위로 섞을지 아닐지를 결정하는 옵션이에요.
False로 지정하면 데이터를 무작위로 섞지 않고 순차적으로 배치 단위로 만들어서 모델에 먹이게 됩니다.
DataLoader의 옵션에 대한 자세한 내용은 링크를 참고해주세요.
앞에서 했던 것처럼 DataLoader의 요소를 확인하기 위해 next()와 iter()를 사용해볼게요.
next(iter(train_dataloader))출력 결과
(tensor([2, 2, 3, 2, 0, 2, 1, 3]),
tensor([ 314, 332, 915, 521, 3, 62, 3205, 2586, 2803, 3,
1631, 1, 314, 332, 26, 4360, 5237, 47631, 72, 2356,
90, 25, 1100, 4, 77, 591, 1162, 3205, 12, 9,
3127, 17, 77, 33, 2672, 2, 4199, 99, 4467, 7,
32, 54, 12, 9, 1898, 1694, 1, 30, 11666, 848,
2103, 26112, 3, 5, 4747, 883, 3, 7671, 1042, 8,
1503, 3611, 4633, 1, 3632, 1, 172, 6548, 893, 34,
7705, 157, 7443, 450, 732, 3, 140, 13, 3838, 14,
15, 161, 301, 34, 22, 181, 3201, 224, 500, 35,
3577, 8, 287, 28792, 1002, 4, 332, 553, 4, 5,
15893, 1408, 3, 3632, 1, 12982, 797, 5167, 21468, 5,
228, 438, 797, 5167, 11, 2145, 1207, 33, 354, 6934,
82, 4, 1104, 478, 17, 25, 6022, 1877, 7447, 3519,
4, 3903, 7985, 5159, 633, 3, 7, 6769, 6, 2,
1207, 12, 812, 8, 7, 687, 11, 2057, 2297, 3,
1011, 26, 1380, 273, 1372, 1864, 4, 975, 12310, 2,
2146, 273, 10, 65, 1588, 5, 1864, 4, 12310, 435,
2, 9238, 975, 4, 30117, 2, 100, 12, 9, 3821,
4, 5, 5078, 298, 18, 533, 3, 5, 673, 58,
241, 614, 26, 1, 77, 1957, 700, 642, 171, 11,
48, 97, 77, 55, 325, 3596, 22, 314, 632, 8023,
3, 52, 101, 7358, 11, 397, 48, 97, 2, 362,
6, 1460, 11, 6338, 200, 700, 15, 7, 359, 4,
6607, 5, 23, 232, 4, 1404, 2, 171, 7, 40368,
18, 2536, 171, 29, 498, 2185, 11194, 2054, 3, 89,
13323, 19, 359, 6, 41, 164, 1, 1, 1, 41,
163, 2, 23, 73, 498, 4280, 57, 40, 2054, 17,
5, 3418, 89, 18, 2, 2193, 864, 3790, 3290, 37,
45583, 3, 8, 197, 176, 554, 134, 2, 89, 95,
37, 212, 43, 19, 359, 6, 5, 5462, 56, 1,
4565, 6, 447, 1955, 36670, 34, 77, 134, 5, 2339,
13, 18229, 2, 4565, 6, 447, 14, 7, 314, 12,
4844, 6, 4565, 2048, 3, 5, 3464, 3326, 17, 7868,
52, 2339, 3, 28, 81, 326, 6287, 435, 12950, 1008,
1]),
tensor([ 0, 47, 64, 105, 152, 194, 244, 300]))
next(iter(val_dataloader))출력 결과
(tensor([0, 0, 0, 3, 3, 1, 2, 0]),
tensor([ 196, 84, 51, 1, 9, 1, 2845, 279, 3, 180,
3771, 7441, 13, 27, 14, 27, 15, 196, 26, 10,
114, 2, 88, 159, 86, 2499, 3771, 5775, 10, 1124,
11, 196, 16, 9, 1310, 180, 3086, 8, 279, 388,
4725, 3, 781, 2, 249, 11, 2436, 2660, 7, 2,
48, 7913, 1, 18, 921, 10, 339, 3, 1068, 535,
78, 13963, 4888, 1364, 12569, 18, 1068, 1431, 4, 741,
671, 5, 1448, 1938, 1305, 24, 19, 258, 19, 71,
12, 9, 152, 3, 2, 138, 1952, 547, 422, 21,
11971, 777, 4, 678, 30, 483, 17, 95, 6813, 22,
6665, 34239, 700, 4, 2, 286, 335, 1813, 464, 8143,
2, 286, 16, 9, 2427, 169, 84, 542, 393, 4341,
46, 8143, 4, 464, 4, 962, 4, 152, 2310, 618,
1, 265, 495, 29020, 3223, 1627, 160, 7, 13651, 5,
1248, 1225, 4, 4694, 3541, 3, 8880, 8, 637, 543,
6, 265, 495, 4765, 52, 85, 33, 741, 868, 267,
2, 4139, 6, 5, 23, 1942, 1064, 15, 2, 1304,
11, 2, 19597, 6, 23088, 656, 1942, 1, 41, 1194,
8362, 1190, 41, 1194, 41, 6606, 8446, 4680, 1, 4047,
1, 8421, 1, 36, 1, 8407, 1, 26039, 8450, 8426,
80, 8458, 8403, 8373, 41, 5, 259, 4680, 1, 4047,
1, 6743, 25262, 25261, 51, 80, 4807, 4680, 1, 4047,
1, 6743, 25258, 25260, 901, 80, 4807, 255, 1, 205,
1, 25648, 1, 9212, 80, 25538, 26454, 26434, 26642, 5346,
205, 6879, 12013, 409, 1, 41, 257, 41, 8375, 4814,
24, 13587, 143, 1202, 4359, 6537, 13, 6907, 13, 6502,
14, 14, 3, 12013, 409, 122, 392, 4128, 8, 434,
5727, 1, 3559, 46, 68, 6879, 12013, 409, 1, 41,
1190, 4426, 26898, 29101, 15, 24474, 764, 450, 1349, 3,
140, 15, 223, 539, 28, 62, 6676, 3770, 357, 25,
154, 4, 382, 17, 2347, 8239, 181, 7453, 6, 2,
4426, 13, 3257, 3, 221, 287, 412, 778, 4055, 22428,
14, 3, 2, 54, 21, 4654, 350, 66, 2, 181,
180, 18, 22, 221, 1, 300, 523, 1227, 8, 675,
1923, 2, 849, 13757, 514, 19, 582, 39, 81, 5,
13453, 5580, 7, 2, 343, 195, 300, 12, 6211, 1,
3177, 2111, 49076, 435, 18, 5, 10031, 17, 26, 44,
1164, 62, 36, 80, 450, 832, 124, 2861, 4, 517,
1997, 5, 3937, 3960, 148, 59, 65, 21, 3245, 68,
2516, 832, 124, 7, 450, 3147, 4, 5, 1572, 449,
1, 2, 148, 456, 4100, 59, 19, 5, 385, 19169,
18161, 12, 9, 577, 627, 3, 103, 2296, 4292, 78,
46, 34459, 3334, 4673, 3, 64077, 76, 4292, 5764, 569,
199, 125, 6284, 4910, 17, 32, 6546, 3334, 4, 34459,
2354, 42, 2, 356, 9367, 4, 2566, 32497, 2530, 1]),
tensor([ 0, 53, 105, 131, 281, 335, 374, 418]))
다시 정리하면, DataLoader로 데이터를 batch 단위로 불러와서 모델을 학습시키기 위해 batch 입력의 길이가 고정되어야 하는데, 텍스트는 문장에 따라서 길이가 가변적이라는 문제점이 존재합니다.
이를 해결하기 위해 collate_fn 옵션을 통해 데이터의 batch 길이는 일정하지 않지만 새로운 텍스트의 시작 위치 index인 offset을 두어서 모델을 학습시키고자 하는 것입니다.
그래서 위의 출력을 확인해보면 train_dataloader의 첫 번째 배치 길이와 test_dataloader의 첫 번째 배치 길이가 서로 다르다는 걸 눈치채실 수 있습니다.
Model 제작하기
PyTorch에서는 상대적으로 자신이 직접 모델을 수정할 수 있는 자유도가 높아요. 이 실습에서는 직접 모델을 만들면서 DIY를 실천해보도록 해요!
nn.Module이란?
이제 본격적으로 모델을 만들어볼게요. 😆
여기서도 Dataset과 비슷한 면이 존재하는데요.
PyTorch에서는 torch.nn의 Module을 통해 커스텀 모델을 제작할 수 있는 기능을 제공해줘요.
그래서 자신이 원하는 모델 클래스를 제작하려면 반드시 torch.nn.Module을 상속 받아야 해요.
import할 때 torch.nn as nn으로 가져왔기 때문에 코드에서는 nn.Module로 작성했어요.
이름이 nn인 이유는 아마 neural network의 축약어가 아닌가 하는 생각이 드네요.
class TextClassifier(nn.Module):
# TextClassifier 클래스의 인스턴스를 생성할 때 자동으로 호출되는 함수입니다.
def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers, num_classes):
super().__init__()
# 단어장의 크기를 저장합니다.
self.vocab_size = vocab_size
# Embedding을 거치고 난 후의 차원을 저장합니다.
self.embed_dim = embed_dim
# Hidden State의 차원을 저장합니다.
self.hidden_dim = hidden_dim
# RNN을 몇 단으로 stack처럼 쌓을지를 저장합니다.
self.num_layers = num_layers
# 최종적으로 분류해야 할 레이블의 수를 저장합니다.
self.num_classes = num_classes
# 커스텀 모델 클래스 내의 멤버변수에 원하는 Neural Network를 레이어로 정해서 커스텀 모델의 레이어를 깊게 쌓을 수 있습니다.
# torch.nn에서 불러와서 원하는 neural network layer를 쌓을 수 있는 것이지요.
# 이 실습에서는 EmbeddingBag, RNN, Linear 세 가지 레이어를 순차적으로 쌓아서 만들게요.
# EmbeddingBag는 각 텍스트 문장의 tensor를 가방(bag)으로 묶어서 평균을 계산할 수 있습니다.
# RNN에 일정한 차원 크기의 입력으로 데이터가 들어갈 수 있도록 미리 데이터를 embedding 시키는 것입니다.
# 즉, RNN 레이어 모델이 잘 소화할 수 있도록 차원을 변환해주는 역할을 합니다.
self.embedding = nn.EmbeddingBag(self.vocab_size, self.embed_dim, sparse=True)
# 드디어 대망의 RNN을 사용하게 되네요!
# RNN에서는 hidden state가 존재한다는 거 기억하시나요?
# RNN 레이어는 기본적으로 텍스트의 임베딩 차원, hidden state 차원, 쌓을 RNN의 수 등을 파라미터로 넘깁니다.
# 그런데 여기서 중요하게 봐야할 부분은 RNN의 입력을 어떠한 차원으로 줘야 하는가입니다. (RNN의 입력 차원과 텍스트의 임베딩 차원은 서로 다른 얘기입니다.)
# 이 입력 차원을 설정할 때 batch_first 옵션에 True를 주면 RNN의 입력 차원에서 batch 크기가 맨 앞으로 이동하게 됩니다.
self.rnn = nn.RNN(self.embed_dim, self.hidden_dim, self.num_layers, batch_first=True)
# 4개의 라벨 중 하나로 예측해야 하므로 선형 변환하는 레이어를 설정합니다.
self.linear = nn.Linear(self.hidden_dim, self.num_classes)
# 모델에 데이터를 파라미터로 넘겨서 실행하면 자동적으로 모델의 `forward` 함수가 호출됩니다.
def forward(self, text, offsets):
# 위에서 설정한 EmbeddingBag Layer에 데이터를 넣습니다.
# view를 사용하는 이유는, RNN의 입력 차원을 [batch_size, RNN에서 시퀀스로 판단되는 길이, 텍스트의 임베딩 차원]으로 바꾸기 위해서입니다.
embedded = self.embedding(text, offsets).view(batch_size, -1, self.embed_dim)
# 처음 RNN에 들어갈 hidden state를 0으로 초기화하는 작업입니다.
# 참고로 RNN의 hidden state의 차원은 [num_layers, batch_size, hidden_dim]입니다.
hidden = torch.zeros(
self.num_layers, embedded.size(0), self.hidden_dim
).to(device)
# RNN 레이어에 학습시키면, 마지막 cell에서의 hidden state와 RNN 레이어를 통과한 최종 결과인 각 batch별 cell별 output(hidden state)이 나옵니다.
# RNN의 각 batch별 cell별 output 차원은 [batch_size, RNN에서 시퀀스로 판단되는 길이, hidden_dim]입니다.
rnn_out, hidden= self.rnn(embedded, hidden)
# RNN의 최종 결과에서 각 batch_size별로 마지막 cell에서 나온 hidden state의 결과를 가지고 선형 변환을 하여 레이블 수만큼의 차원으로 변환합니다.
out = self.linear(rnn_out[:, -1:]).view([-1,self.num_classes])
# 최종적으로 모델이 예측한 레이블 값이 반환될 것입니다.
return out
이 부분이 가장 난해한 부분이라고 개인적으로 생각해요. 😭
우선 PyTorch의 RNN 레이어의 차원에 관한 자세한 설명은 여기 링크를 보시면 됩니다.
https://coding-yoon.tistory.com/55
[딥러닝] RNN with PyTorch ( RNN 기본 구조, 사용 방법 )
오늘은 Pytorch를 통해 RNN을 알아보겠습니다. https://www.youtube.com/watch?v=bPRfnlG6dtU&t=2674s RNN의 기본구조를 모르시면 위 링크를 보시는걸 추천드립니다. Pytorch document에 RNN을 확인하겠습니다. ht..
coding-yoon.tistory.com
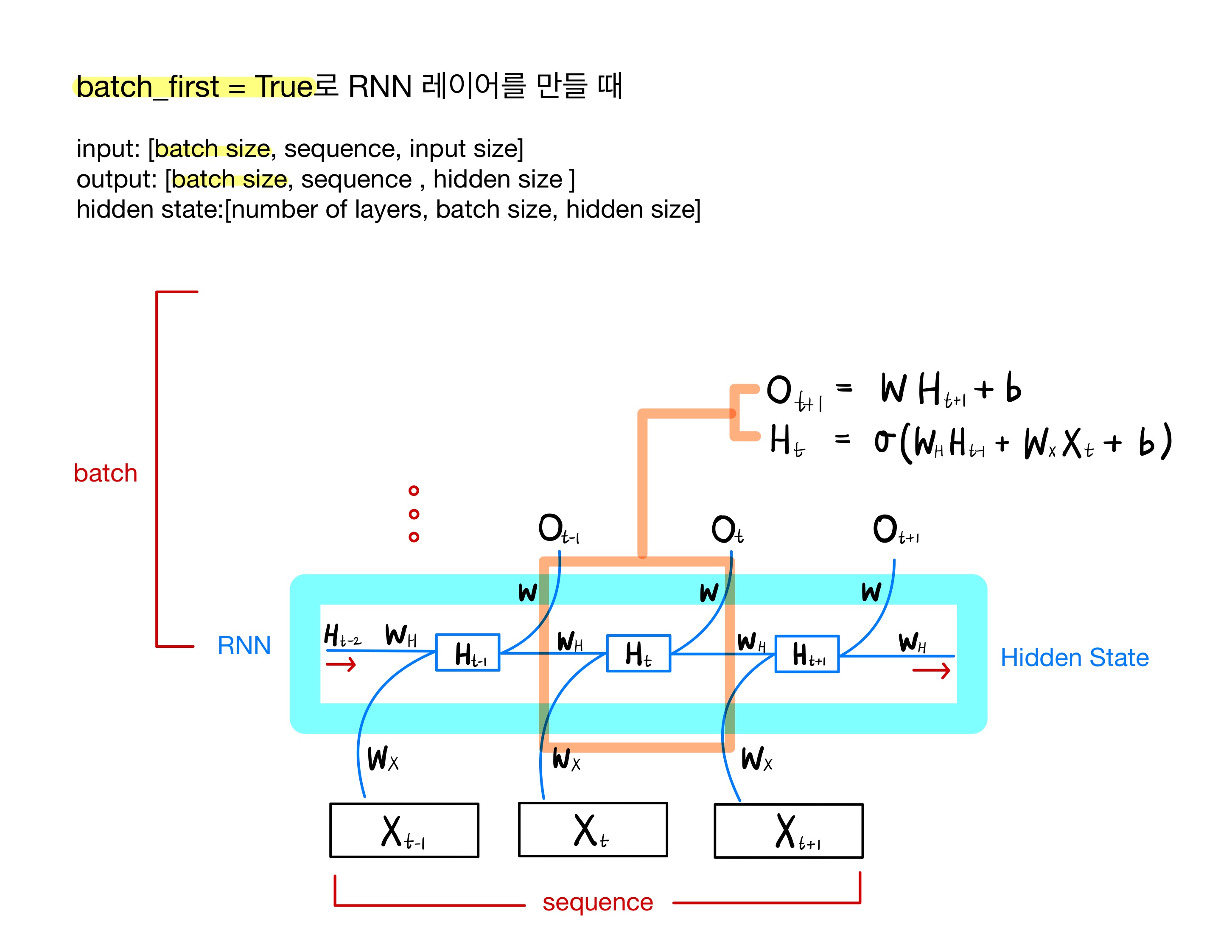
RNN의 batch_first 파라미터를 True로 주면 input, output의 차원은 다음과 같이 설정됩니다.
- input: [batch_size, sequence, input_size]
- output: [batch_size, sequence, hidden_size]
RNN의 hidden state의 차원은 다음과 같습니다.
- hidden state: [num_of_layers, batch_size, hidden_size]
RNN의 구조와 함께 코드 내용을 정리하면 다음과 같습니다.
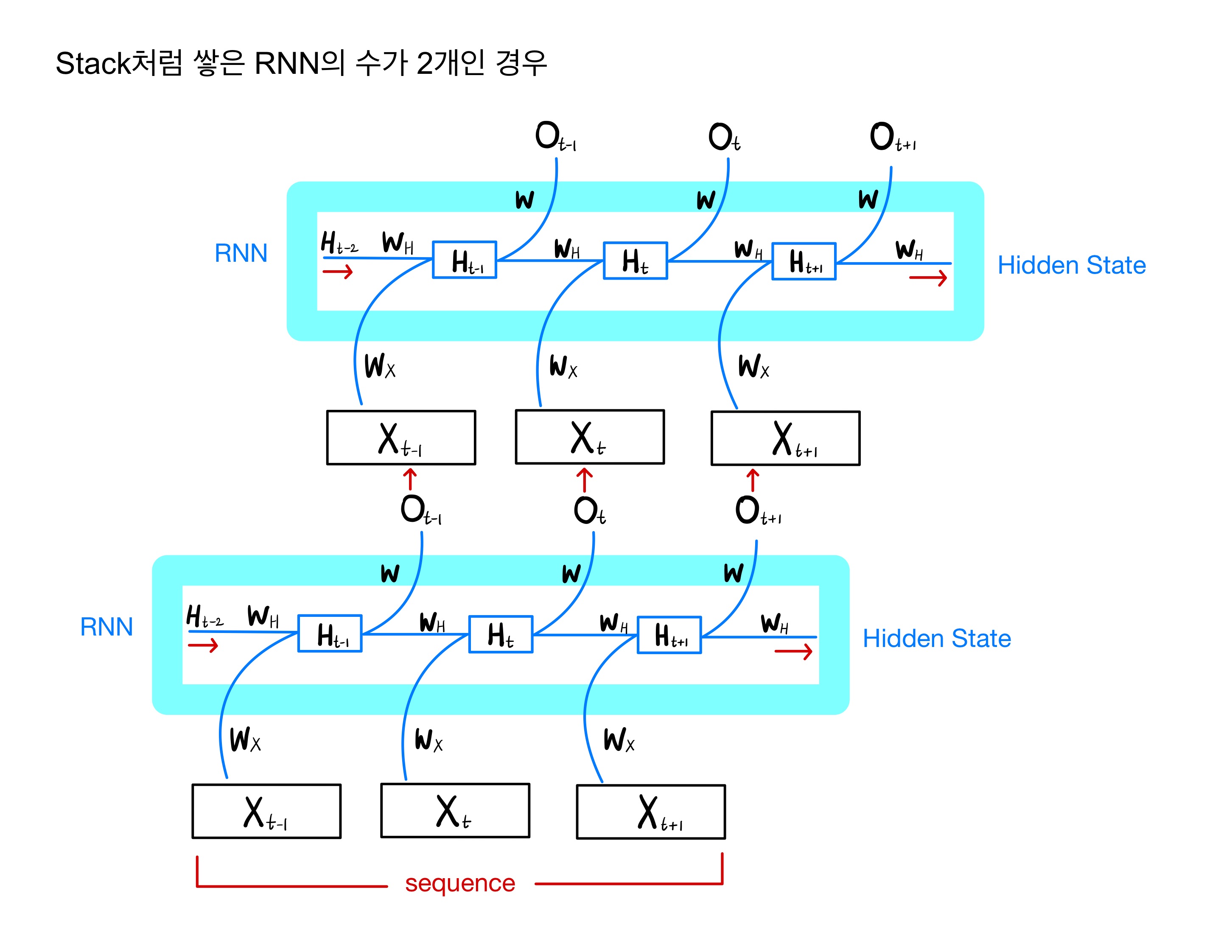
위의 모델에서 num_of_layers 파라미터의 의미는 RNN을 stack처럼 몇 단을 쌓을지를 정하는 것인데요.
RNN을 쌓는다는 의미를 예로 들어 그림으로 그리면 다음과 같습니다. 예시는 2단으로 쌓아 올린 RNN 모델입니다.
그리고 아래는 Embedding Bag로 텍스트의 입력을 임베딩하여 모델의 입력으로 넣는 흐름을 나타내는데요. 한 번 참고해보시면 될 것 같아요!

[출처: https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html]

Model 학습하기
모델을 학습하고 검증하는 과정은 대개 일련의 순서로 진행됩니다. 대강의 순서만 알고 있어도 모델을 학습하는데 크게 도움이 됩니다.
우선 조건에 맞게 RNN 커스텀 모델을 생성해 볼게요.
# 단어장의 크기를 저장합니다.
vocab_size = len(vocab)
# 임베딩 차원의 크기를 64로 저장합니다.
embed_dim = 64
# RNN의 hidden state의 차원 크기를 32로 저장합니다.
hidden_dim = 32
# RNN을 1단만 쌓기로 합니다.
num_layers = 1
# 분류해야 할 레이블의 개수를 저장합니다.
num_classes = 4
model = TextClassifier(vocab_size, embed_dim, hidden_dim, num_layers, num_classes)위처럼 파라미터를 넘겨서 커스텀 모델인 TextClassifier의 객체를 생성하면, 생성자인 __init__()이 자동으로 실행됩니다.
이 __init__()에서 여러 멤버 변수와 모델의 레이어를 정해주는 것이지요.
Loss와 Optimizer 설정
Loss 함수는 실제 레이블과 모델이 예측한 값의 차이를 어떤 식으로 정의할지를 결정하는 것입니다.
그리고 Optimizer는 back propagation 적용 후 모델의 파라미터를 어떻게 업데이트할지 그 방식을 결정하는 것이죠.
마찬가지로 torch.nn에서 기본적으로 제공하는 loss 함수와 torch.optim에서 제공하는 optimizer에서 원하는 것들을 가져올 수 있습니다.
이번 실습에서는 4개의 레이블로 분류하는 것이므로 cross entropy loss 함수와 SGD(Stochastic Gradient Descent)를 적용해보겠습니다.
learning_rate = 0.01
epochs = 20
# Cross Entropy를 적용합니다.
criterion = torch.nn.CrossEntropyLoss()
# Optimizer를 설정하는 것인데, 여기서 주목해야할 점은 `model.parameters()`로 모델의 모든 파라미터를 optimizer 생성 인자로 넘긴다는 것입니다.
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# Scheduler는 학습 epoch을 늘려가는 과정에서 learning rate를 어떻게 조정할지를 정합니다.
# 일반적으로 앞의 epoch에서는 큰 learning rate로 진행하다가 뒤로 갈수록 작은 learning rate로 바꿔줘야 loss 함수의 극소로 도달하는 데 유리합니다.
# StepLR은 step size마다 gamma의 비율로 learning rate를 감소시키는 방법입니다.
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 20, gamma=0.5)
학습 과정
이제 준비는 다 끝났어요!
앞에서 우리가 정한 DataLoader로 전체 데이터를 batch 별로 하나씩 가져와 학습시키도록 하면 됩니다.
Batch 별로 학습을 진행하는 구체적인 과정을 요약하면 다음과 같습니다.
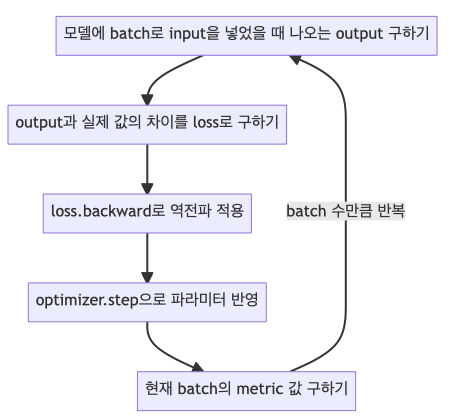
- Optimizer의 zero_grad() 함수로 optimizer에 있는 파라미터를 모두 0으로 초기화해줍니다.
- 앞에서 제작한 커스텀 모델에 데이터의 입력을 넣어줘서 나오는 출력을 받습니다.
- 위에서 정한 loss 함수로 실제 레이블과 모들이 예측한 값의 차이를 구합니다.
- Loss 함수의 backward() 함수로 back propagation을 진행하여 각 파라미터의 gradient를 구합니다.
- Optimizer의 step() 함수로 4번에서 구한 gradient를 가지고 모델의 각 파라미터를 업데이트해 줍니다.
자세한 내용은 코드의 주석을 참고하면서 확인해봐요!
def train(dataloader, epoch):
# 모델을 학습시키기 위해 모델을 학습 모드로 바꿔줍니다.
# 모델이 학습 모드일 때와 검증 모드일 때 메모리 사용과 연산의 효율성이 다르다고 합니다.
# 또한 검증 모드일 때는 Batch Normalization과 Dropout 등이 적용이 안되어서 학습 또는 검증 전에 원하는 모드로 모델을 바꿔주는 게 필요합니다.
model.train()
train_acc = 0
train_count = 0
# 얼마 만큼의 batch 간격마다 현재 모델의 학습 데이터에 관한 정확도를 출력할지 정합니다.
# 2000 batch 간격마다 출력하도록 할게요.
log_interval = 2000
# 앞에서 정의한 DataLodaer로 데이터를 batch 별로 하나씩 불러옵니다.
for idx, (labels, texts, offsets) in enumerate(dataloader):
# Optimizer의 `zero_grad()` 함수로 optimizer에 있는 파라미터를 모두 0으로 초기화해줍니다.
optimizer.zero_grad()
# 앞에서 제작한 커스텀 모델에 데이터의 입력을 넣어줘서 나오는 출력을 받습니다.
# offset을 같이 넣는 이유는, 앞서 model에서 정의한 것처럼 Embeddingbag 레이어에서 offset이 필요하기 때문이죠.
outs = model(texts, offsets)
# 모델이 예측한 레이블을 알아내기 위해 가장 값이 큰 요소의 인덱스를 받아옵니다.
predicts = torch.argmax(outs, dim=-1)
# Loss 함수로 실제 레이블과 예측 값의 차이를 구합니다.
loss = criterion(outs, labels)
# Loss 함수의 `backward()` 함수로 back propagation을 진행하여 각 파라미터의 gradient를 구합니다.
loss.backward()
# Optimizer의 `step()` 함수로 4번에서 구한 gradient를 가지고 모델의 각 파라미터를 업데이트해 줍니다.
optimizer.step()
# 이번 batch에서 예측 레이블과 실제 레이블이 같은 것의 개수를 더해줍니다.
train_acc += (predicts == labels).sum().item()
# 데이터의 개수만큼 더합니다.
train_count += labels.size(0)
# 2000만큼의 간격마다 accuracy를 계산합니다.
if idx % log_interval == 0 and idx > 0:
# 모델이 정확히 레이블을 예측한 것의 개수를 전체 데이터 수로 나눠서 모델의 학습 데이터에 대한 accuracy를 구합니다.
print('| epoch {:3d} | {:5d}/{:5d} batches | accuracy {:8.3f}'.format(epoch, idx, len(dataloader), train_acc / train_count))
scheduler.step()
검증 과정
이제 거의 다 왔어요! 🙂
검증 과정은 정말 간단합니다.
마찬가지로 검증 DataLoader의 batch마다 모델에 입력을 넣어서 나오는 예측 레이블을 실제 레이블과 비교하면 되거든요.
여기서 주목할 건 torch.no_grad() 함수를 써서 모델의 파라미터가 자동미분되지 않도록 해주는 것입니다.
그런데 어차피 loss 함수의 backward()를 실행하지 않으면 back propagation이 실행되지 않을 텐데 상관이 없지 않을까요? 🧐
맞습니다! 사실 주된 목적은 자동 미분을 비활성화해서 메모리 사용량을 줄이고 연산의 효율성을 높이기 위한 것입니다.
컴퓨팅 리소스는 아끼면 아낄수록 좋은 것이니까요. 😆
def evaluate(dataloader):
model.eval()
val_acc = 0
val_count = 0
val_acc_items = []
# 자동 미분 기능을 끔으로써 연산과 메모리 사용의 효율성을 높여줍니다.
with torch.no_grad():
# 검증 DataLoaer에서 batch 별로 하나씩 모델에 학습시킵니다.
for idx, (labels, texts, offsets) in enumerate(dataloader):
# 앞에서 제작한 커스텀 모델에 데이터의 입력을 넣어줘서 나오는 출력을 받습니다.
outs = model(texts, offsets)
# 모델이 예측한 레이블을 알아내기 위해 가장 값이 큰 요소의 인덱스를 받아옵니다.
predicts = torch.argmax(outs, dim=-1)
# 이번 batch에서 예측 레이블과 실제 레이블이 같은 것의 개수를 더해줍니다.
acc_item = (labels == predicts).sum().item()
val_acc_items.append(acc_item)
val_count += labels.size(0)
# 모델이 정확히 레이블을 예측한 것의 개수를 전체 데이터 수로 나눠서 모델의 검증 데이터에 대한 accuracy를 구합니다.
val_acc = np.sum(val_acc_items) / val_count
return val_acc이제 마지막으로 epoch 수만큼 학습과 검증을 반복해주면 됩니다.
가장 성능이 좋은 시점의 Model 또는 Model 파라미터 저장하기
좀 더 나아가면, 모든 epoch 중 가장 측정 기준(accuracy 등)이 좋았던 시점의 모델의 파라미터 또는 모델 그 자체를 저장할 수 있습니다.
이는 torch.save(model, PATH)로 모델 그 자체, 또는 torch.save(model.state_dict(), PATH)로 모델의 파라미터를 저장할 수 있습니다.
여기서 저장되는 모델 또는 모델의 파라미터의 확장자는 .pt입니다.
테스트할 때 가장 좋은 시점의 모델을 불러오는 것도 간단합니다.
이때는 torch.load(PATH)로 모델 또는 모델의 파라미터를 불러올 수 있어요.
모델의 파라미터를 불러와서 현재 모델의 파라미터로 업데이트하려면 model.load_state_dict(torch.load(PATH))를 실행해주면 됩니다.
total_acc = 0
for epoch in range(1, epochs + 1):
# 학습 DataLoader로 학습을 진행합니다.
train(train_dataloader, epoch)
# 검증 DataLoader로 검증을 합니다.
acc_val = evaluate(val_dataloader)
# 이번 epoch에서의 검증 결과(정확도)가 처음부터 이제까지의 검증 결과(정확도)보다 좋으면 가장 좋은 검증 결과고 업데이트합니다.
if total_acc < acc_val:
total_acc = acc_val
# 만약에 가장 좋은 accuracy일 때의 모델 또는 모델의 파라미터를 저장하면 이 logic을 여기서 처리해주면 됩니다.
# 실습에서는 하지 않고 과제에서 등장할 예정입니다.
print('-' * 60)
print('| end of epoch {:3d} | valid accuracy {:8.3f} '.format(epoch, total_acc))
print('-' * 60)
만든 모델 테스트하기
이제 거의 모든 게 끝났습니다! 테스트 하는 과정은 정말 간단해요. 마찬가지로 Dataset을 생성하고, DalaLoader를 설정한 다음, 검증만 실행해주면 됩니다.
test_dataset = CustomDataset(TEST_AG_NEWS_PATH, train=False)
test_dataloader = DataLoader(val_dataset, batch_size=8, shuffle=False, collate_fn=collate_batch)acc_val = evaluate(test_dataloader)
print('-' * 59)
print('test accuracy {:8.3f} '.format(acc_val))
print('-' * 59)
축하드려요! 🥳 드디어 끝이 났네요.
PyTorch에 능숙하신 분도 계실 거고 좀 낯선 분들도 계셨을 텐데 그래도 쉽지 않은 내용 따라와주셔서 감사합니다!
내용도 길고 대화체로 설명하는 오글거리는 말투 때문에 많이 고통스러우셨을 텐데... 😅 정말 고생 많으셨습니다! 🤗
ps. 앞으로의 발표와 과제 제작에 있어서 제게 큰 영감을 주신 네이버 부스트캠프 AI Tech의 부덕이 🦆 과제 제작자분께 진심으로 감사드립니다 :)
'AI > AI 실습' 카테고리의 다른 글
| COP(Center of Projection)에서 Image plane의 각 pixel을 향하는 vector 구하기 (0) | 2023.03.30 |
|---|---|
| ML 실험을 위한 관리 플랫폼인 MLflow (0) | 2023.01.04 |
| PyTorch RNN 모델 사용 예제 - CIFAR10 이미지 분류하기 (0) | 2022.04.16 |
Contents
소중한 공감 감사합니다.