AI/AI 기본
모델의 파라미터(Parameter)를 학습하기 위한 Loss와 Optimizer
- -
2022년 1월 24일(월)부터 28일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
PyTorch에서의 Model
[출처] https://commons.wikimedia.org/wiki/File:Example_of_a_deep_neural_network.png, BrunelloN
DNN 모델은 여러 레이어(블록)의 연속으로 이루어질 수 있으며, 이를 구성하는 레이어에는 Softmax Layer, Linear Layer, Normalization Layer 등이 있다.
각각의 레이어를 합쳐서 큰 블록을 만드는 레이어에는 Encoder Layer, Decoder Layer, ResNet 등이 있다.
즉, 하나의 DL의 큰 architecture는 블록의 반복의 연속으로 볼 수 있다.
이를 만들기 위한 가장 기본적인 PyTorch의 클래스는 torch.nn.Module이다.
Model과 torch.nn.Module

[출처] BITAmin 연합동아리 PyTorch 실습 세션에서 발표용으로 직접 제작한 자료
PyTorch에서는 torch.nn의 Module을 통해 커스텀 모델을 제작할 수 있는 기능을 제공해준다.
그래서 자신이 원하는 모델의 클래스를 커스텀하여 제작하려면 반드시 torch.nn.Module을 상속 받아야 한다.
import할 때 torch.nn as nn으로 가져오면 코드에서는 nn.Module로 작성할 수 있다.
이름이 nn인 이유는 아마 neural network의 축약어인 것으로 보인다.
이를 정리하면 다음과 같다.
- 딥러닝을 구성하는 Layer의 Base Class이다.
- Input, Output, Forward, Backward에 해야할 일을 정의한다.
- 학습의 대상이 되는 Parameter(tensor)를 정의한다.
nn.Parameter
학습의 대상이 되는 것들을 nn.Parameter에 정의하며, Tensor 객체의 상속 객체이다.
nn.Module의 attribute가 될 때는 "required_grad = True"로 지정되어서 AutoGrad의 대상이 된다.
대부분의 layer에는 weight 등 이러한 값들이 지정되어 있어서 우리가 직접 Parameter를 지정할 일은 자주 없다.
이미 정의된 layer를 외부 모듈에서 가져오는 일이 잦기 때문이다.
class MyLiner(nn.Module):
'''
xw + b 꼴을 PyTorch에서 이미 구현한 torch.nn.Linear(inputSize, outputSize)와 유사하다.
'''
# in_features 크기를 지니는 input을 out_features 크기를 지니는 output으로 선형변환하는 클래스다.
def __init__(self, in_features, out_features, bias=True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weights = nn.Parameter(torch.randn(in_features, out_features))
self.bias = nn.Parameter(torch.randn(out_features))
def forward(self, x:Tensor):
# y_hat = x·w + b
return x @ self.weights + self.bias # 일종의 예측값(y_hat)으로 볼 수 있다.
Loss와 Optimizer

[출처] BITAmin 연합동아리 PyTorch 실습 세션에서 발표용으로 직접 제작한 자료
Loss
실제 값과 모델이 예측한 값의 차이를 어떠한 식으로 정의할지를 결정하는 것이다.
일반적으로 알고 있는 Loss 함수와 같으며, 여기에는 Cross Entropy Loss, F1 Loss, MSE Loss 등이 해당된다.
일반적인 Loss 함수는 torch.nn이라는 외부 모듈에 정의되어 있다.
Optimizer
역전파 알고리즘(Backpropagation)을 한 후 나온 gradient를 가지고 모델의 parameter를 어떻게 업데이트할지에 관한 방식을 결정하는 것이다.
보통 Loss 함수를 최소화하는 방향으로 모델의 모든 parameter를 업데이트한다.
SGD, Momentum, Adam, AdaGard, RMSProp 등이 포함되며, 일반적으로 자주 사용하는 Optimizer는 torch.optim에 정의되어 있다.
Backpropagation 구현
Layer에 있는 Parameter들의 미분을 수행한다.
Forward의 결과 값(model의 output으로 나온 예측치)와 실제 값간의 차이(loss)에 대한 미분을 수행하고, 해당 값으로 Parameter를 업데이트한다.
학습 시 Backward 과정의 기본 구조는 다음과 같다.
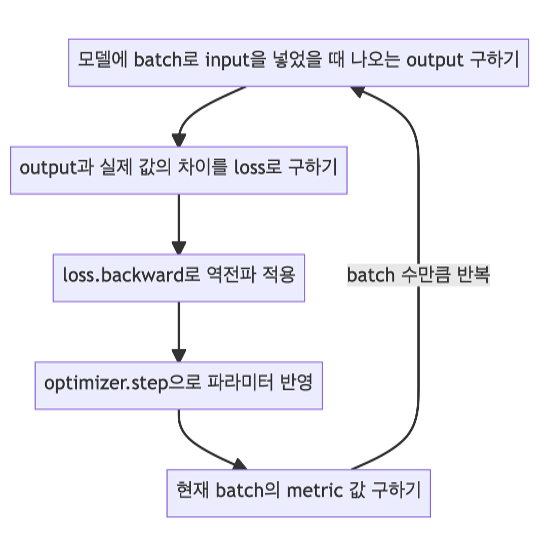
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters())
# (중략)
# 모델 학습 중…
for epoch in range(epochs + 1):
# (중략)
loss = criterion(outs, labels)
loss.backward()
optimizer.step()
# (후략)
좀 더 코드를 자세히 풀어서 쓰면 다음과 같다.
for epoch in range(epochs):
# gradient 초기화
optimizer.zero_grad()
# optimizer는 학습을 진행할 때 gradient 값이 업데이트 되면서 변하는데, 이전의 gradient 값이 지금의 gradient 값의 학습에서 영향을 끼치지 않도록 초기화를 해주는 것이다.
# 모델로 예측치 구하기
outputs = model(inputs)
# outputs = model.forward(inputs)로 해도 됨
# loss(예측값과 실제값의 차이) 계산
loss = criterion(outputs, labels)
print(loss)
# parameters에 대한 gradients 구하기
# 직접 미분 수식을 입력해주는 것과 같은 효과 (Autograd)
loss.backward() # loss를 w(가중치)로 편미분한다.
# update parameters
# 원래의 weight/bias에서 lr * gradients를 뺀 값으로 업데이트
optimizer.step() # w = w - lr * grad
실제 backward()는 Module을 선언하는 단계에서 직접 지정이 가능하지만, AutoGrad이 자동으로 해주므로 직접 지정해줄 필요가 없다.
보통 직접 지정한다면 Module에서 backward()와 optimizer()를 오버라이딩(overridding)을 해준다.
다만, 이렇게 직접 지정하여 구현한다면 사용자가 직접 미분 수식을 써야하는 부담이 있다.
그래서 실제로는 Autograd로 자동 미분을 할 수 있도록 선언한다.
Loss와 Optimizer로 모델 파라미터를 학습하는 과정을 정리하면 다음과 같다.
- Optimizer의
zero_grad()함수로 optimizer에 있는 파라미터를 모두 0으로 초기화해준다. - 앞에서 제작한 커스텀 모델에 데이터의 입력을 넣어줘서 나오는 출력을 받는다.
- 위에서 정한 loss 함수로 실제 레이블과 모들이 예측한 값의 차이를 구한다.
- Loss 함수의
backward()함수로 back propagation을 진행하여 각 파라미터의 gradient를 구한다. - Optimizer의
step()함수로 4번에서 구한 gradient를 가지고 모델의 각 파라미터를 업데이트해 준다.
'AI > AI 기본' 카테고리의 다른 글
| PyTorch에서 모델 학습 과정과 검증 과정에서의 Checkpoints (0) | 2022.02.15 |
|---|---|
| PyTorch의 Dataset과 Dataloader (0) | 2022.02.15 |
| PyTorch 프로젝트 구조와 클래스 속성 활용하기 (0) | 2022.02.15 |
| PyTorch에서의 텐서(Tensor)와 수식 자동 미분을 위한 Autograd (0) | 2022.02.15 |
| 딥 러닝에서 주로 사용하는 프레임워크(Framework) (0) | 2022.02.14 |
Contents
소중한 공감 감사합니다.