AI/AI 기본
PyTorch의 Dataset과 Dataloader
- -
2022년 1월 24일(월)부터 28일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
Dataset & DataLoader
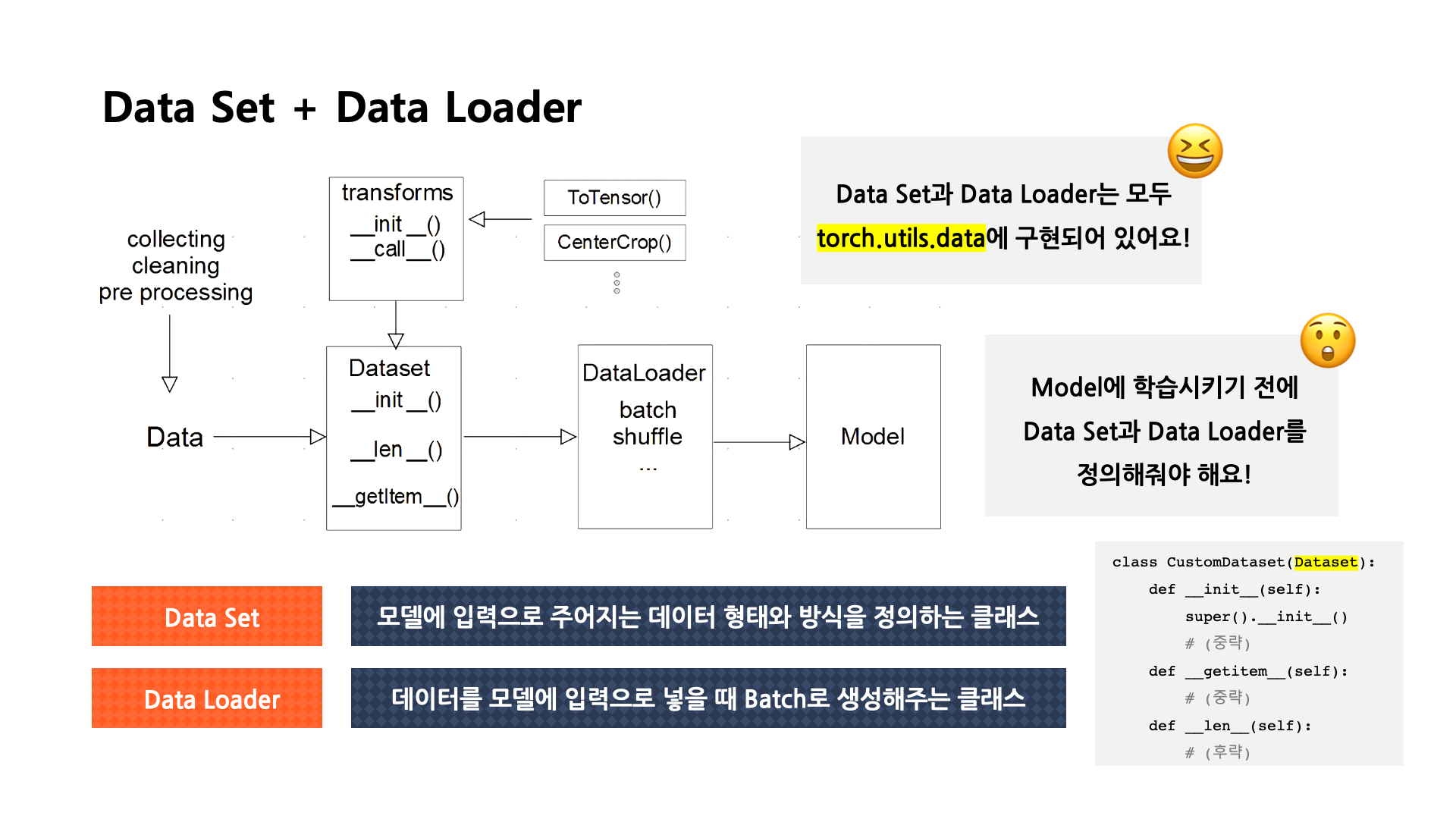
[출처] BITAmin 연합동아리 PyTorch 실습 세션에서 발표용으로 직접 제작한 자료
Model에 데이터를 학습시키기 전에 우선 훈련용, 검증용 데이터에 관한 Dataset과 DataLoader를 지정해줘야 한다.
Dataset
데이터를 모델에 feeding할 때 사용하는 API이다.
또한 모델에 입력으로 주어지는 데이터의 형태와 방식을 정의하는 클래스이다.
이 API의 역할을 세 가지로 정리하면 collecting & cleaning & preprocessing라고 할 수 있다.
- 데이터 입력의 형태를 정의
- 데이터 입력 방식의 표준화
- 데이터의 종류(Image, Audio, Text, ...etc)에 따라 다른 입력을 정의
- __init__()
- 초기 데이터를 어떻게 불러오고 생성하는지를 지정한다.
- __len__()
- 데이터의 전체 길이를 반환한다.
- __getitem__()
- 하나의 데이터를 불러올 때 어떻게 반환을 할 것인지를 정의한다.
- index 값을 주었을 때 반환되는 데이터의 형태를 설정한다.
Dataset 클래스 생성 시 유의할 점
- 데이터 형태에 따라 각 함수를 다르게 정의한다.
- 모든 것을 데이터 생성 시점에 처리할 필요는 없다.
- 예: image의 Tensor로의 변화는 학습에 필요한 시점(주로 Transform 함수를 통해 정의)에 변환한다.
- 데이터 셋에 대한 표준화된 처리방법을 제공할 필요가 있다.
DataLoader
데이터를 모델의 입력으로 모델에 넣을 때 Batch로 생성해주는 등 어떻게 만들어서 넣어줄지를 결정하는 클래스이다.
DataLoader의 역할을 정리하면 구체적으로 다음과 같다.
- Data의 Batch를 생성해주는 클래스이다.
- 학습 직전(GPU에 feed하기 전) 데이터의 변환을 책임진다.
- Tensor로 변환하고 Bacth 처리하는 것이 중요 업무이다.
- transform에 정의한 전처리, tensor로의 변환 등이 적용된다.
쉽게 말하면 데이터를 모델에 입력으로 넣을 때 batch 단위로 가공하여 입력으로 넣어주는 클래스라고 볼 수 있다.
즉, 데이터를 batch 단위로 잘게 썰어서 모델에게 학습시키는 것이다.
한 번에 모든 데이터를 학습하는 것보다는 batch 단위로 학습을 진행하는 것이 리소스를 절약할 수 있어서 학습 시간을 줄일 수 있어서이다.
그래서 전체 데이터를 입력으로 한 번에 넣지 않고 batch 단위로 잘게 썰어 주는 것이다.
음식도 한 번에 모두 먹으면 체할 수 있듯이 말이다. 🤮
마치 Model에세 데이터를 먹이로 주는 숟가락 🥄역할을 한다고 이해하면 쉽다.
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
# sampler - 샘플을 어떻게 뽑을지 index를 지정하는 방식을 정할 수 있는데, 이때 shuffle은 False로 설정해야 한다.
# collate_fn - 데이터와 레이블을 따로 묶어서 저장해주며, 동일하게 padding을 적용하여 zero-padding이나 variable size 데이터 등 다양한 데이터의 사이즈를 하나로 맞추기 위해 많이 사용한다. 인쇄할 때 "묶어서 인쇄하기"로 비유할 수 있다.
이 DataLoader은 개발자를 위한 다양한 옵션들을 제공해주고 있다.
여기서 shuffle은 데이터를 배치 단위로 만들어서 무작위로 섞을지 아닐지를 결정하는 옵션이다.
False로 지정하면 데이터를 무작위로 섞지 않고, 순차적으로 배치 단위로 만들어서 모델에 먹이게 된다.
DataLoader의 옵션에 대한 자세한 내용은 링크를 참고하면 된다.
collate_fn이란?
우리가 글을 읽고 쓸 때도 알 수 있듯이 어떤 데이터의 길이가 항상 일정하지는 않다는 걸 알 수 있다.
그런데 모델에게 학습 데이터를 입력하려면 일정한 길이로 먹여줘야 된다.
그래서 collate_fn 파라미터에 원하는 함수를 지정해서 batch로 묶일 데이터를 일정한 길이로 묶어줄 수 있도록 해야 한다.
주로 데이터의 길이가 가변적일 때 collate_fn 파라미터를 사용한다고 한다.
데이터의 길이가 가변적일 때 이를 해결하기 위한 방법에는 두 가지가 있다.
첫 번째 방법은 패딩(padding)을 주어서 부족한 길이를 일정한 값(예: 0)으로 채워서 batch를 일정한 길이로 맞춰주는 방법이다.
두 번째 방법은 batch의 길이를 맞추지는 않지만 offset을 이용해서 데이터가 어떻게 끊기는지 그 위치를 지정해 주는 방법이다.
Offset을 사용하는 경우 나중에 모델에서 EmbeddingBag를 사용하여 해결할 수 있다.
다음은 offset을 사용하여 collate_fn의 파라미터로 넘길 함수를 정의한 예시이다.
def collate_batch(batch):
labels, texts, offsets = [], [], [0]
for (label, text) in batch:
# 레이블의 값을 1만큼 줄이는 label_preprocess를 적용한 후 모델의 입력 데이터로 넘깁니다.
# zero-based numbering으로 시작하는 것을 반영한 것이죠.
labels.append(label_preprocess(label))
# 텍스트를 단어장으로 번역된 수의 리스트로 바꾸고, 이를 다시 tensor 자료형으로 바꿉니다.
# PyTorch에서는 기본적으로 tensor 자료형으로 모델을 학습시키거든요.
processed_text = torch.tensor(text_preprocess(text), dtype=torch.int64)
texts.append(processed_text)
# Batch 크기를 일정하게 맞췄지만, 이렇게 될 경우 각 문장의 시작 위치가 어떤지는 알 수 없습니다.
# 그래서 offsets에 각 문장의 시작 위치를 저장할 수 있도록 합니다.
offsets.append(processed_text.size(0))
# 레이블과 offsets 모두 모델이 소화할 수 있도록 tensor로 바꿔줍니다.
labels = torch.tensor(labels, dtype=torch.int64)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
# tensor로 변환된 텍스트를 하나로 합칩니다.
texts = torch.cat(texts)
# 레이블, 변환된 텍스트, 오프셋 시작 위치 3가지를 반환하도록 합니다.
return labels.to(device), texts.to(device), offsets.to(device)
# 학습 데이터의 Data Loader와 검증 데이터의 Data Loader를 각각 설정합니다.
# collate_fn 파라미터에 위에서 정의한 batch 적용 함수를 넘겨줍니다.
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_batch)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_batch)
'AI > AI 기본' 카테고리의 다른 글
| PyTorch에서 자주 사용하는 학습 과정 및 결과 모니터링 Tool (0) | 2022.02.15 |
|---|---|
| PyTorch에서 모델 학습 과정과 검증 과정에서의 Checkpoints (0) | 2022.02.15 |
| 모델의 파라미터(Parameter)를 학습하기 위한 Loss와 Optimizer (0) | 2022.02.15 |
| PyTorch 프로젝트 구조와 클래스 속성 활용하기 (0) | 2022.02.15 |
| PyTorch에서의 텐서(Tensor)와 수식 자동 미분을 위한 Autograd (0) | 2022.02.15 |
Contents
소중한 공감 감사합니다.