AI/AI 수학
통계와 최대가능도 추정법(MLE)
- -
통계적 모델링
통계적 모델링은 적절한 가정 위에서 확률분포를 추정하는 것이 목표이며, 이는 기계학습이 추구하는 목표와 동일하다.
관찰만으로는 모집단의 분포를 정확하게 알아내는 것은 불가능하므로 근사적으로 확률분포를 추정해야 한다.
그래서 유한한 갯수의 데이터를 통해서 확률분포를 추정하고 근사하여 앞으로에 대한 예측과 의사결정 등에 활용할 수 있다.
모델링은 데이터의 확률분포를 정확히 맞추는 것보다는 추정방법의 불확실성을 고려한 상태에서 위험을 최소화 하는 방향으로 진행된다.
즉, 틀릴 확률을 낮추고자 하는 것이다.
데이터가 특정 확률분포를 따른다고 선험적으로 가정하고 그 분포를 결정하는 모수를 추정하는 방법을 모수적 방법론이라 하라고 한다.
특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수 방법론이라고 한다.
비모수 방법론은 모수가 없는 게 아니라 모수가 무한히 많거나 모수가 데이터에 따라 바뀌는 것이다.
기계학습의 많은 방법론은 비모수 방법론에 속한다.
모수
모집단의 특성을 나타내는 데이터를 의미하며, 특정 확률분포를 정의하는 고정된 상수이다.
각 확률분포는 이 모수에 의해 특징지어지며, 이 모수가 바로 데이터의 특징이 된다.
정규분포에서 중요한 모수: 평균, 분산
확률분포 가정하기
- 데이터가 2개의 값만 가지는 경우: 베르누이 분포
- 데이터가 n개의 이산적인 값을 가지는 경우: 카테고리 분포
- 데이터가 [0, 1] 사이에서 값을 가지는 경우: 베타분포
- 데이터가 0 이상의 값을 가지는 경우: 감마분포, 로그정규분포 등
- 데이터가 $\mathbb{R}$ 전체에서 값을 가지는 경우: 정규분포, 라플라스 분포 등
기계학습이나 통계적 모델링은 데이터가 어떤 확률분포를 따르는지 가정하고, 그 이후에 모수를 찾아나가는 과정으로 이어진다. 단, 데이터를 생성하는 원리를 먼저 고려하고 이를 바탕으로 확률분포를 가정해야 한다.
표본평균과 표본분산
주어진 데이터 $X$가 정규분포를 따른다고 가정해보자. 이제 우리는 정규분포의 모수를 찾는 것을 목적으로 하게 된다. 정규분포의 모수인 평균($\mu$)과 분산($\sigma^2$)이다.
주어진 데이터로부터 N개의 데이터를 뽑아 표본평균인 $\bar{X}$를 구할 수 있는데, 표본평균과 같은 통계량의 확률분포를 표집분포(sampling distribution)라 한다. 표본분산의 확률분포도 표집분포에 해당될 것이다.
표본평균의 표집분포는 데이터의 수 N이 커질수록 중심극한의 정리에 따라 정규분포를 따르게 되어있다.
중심극한정리(Central Limit Theorem)
다음은 주사위를 $n$번 던졌을 때 나온 숫자의 총합을 샘플링한 것을 확률분포로 나타낸 것이며, 던진 횟수가 많아질수록 표본 평균이 정규 분포에 근사하는 것을 볼 수 있다.
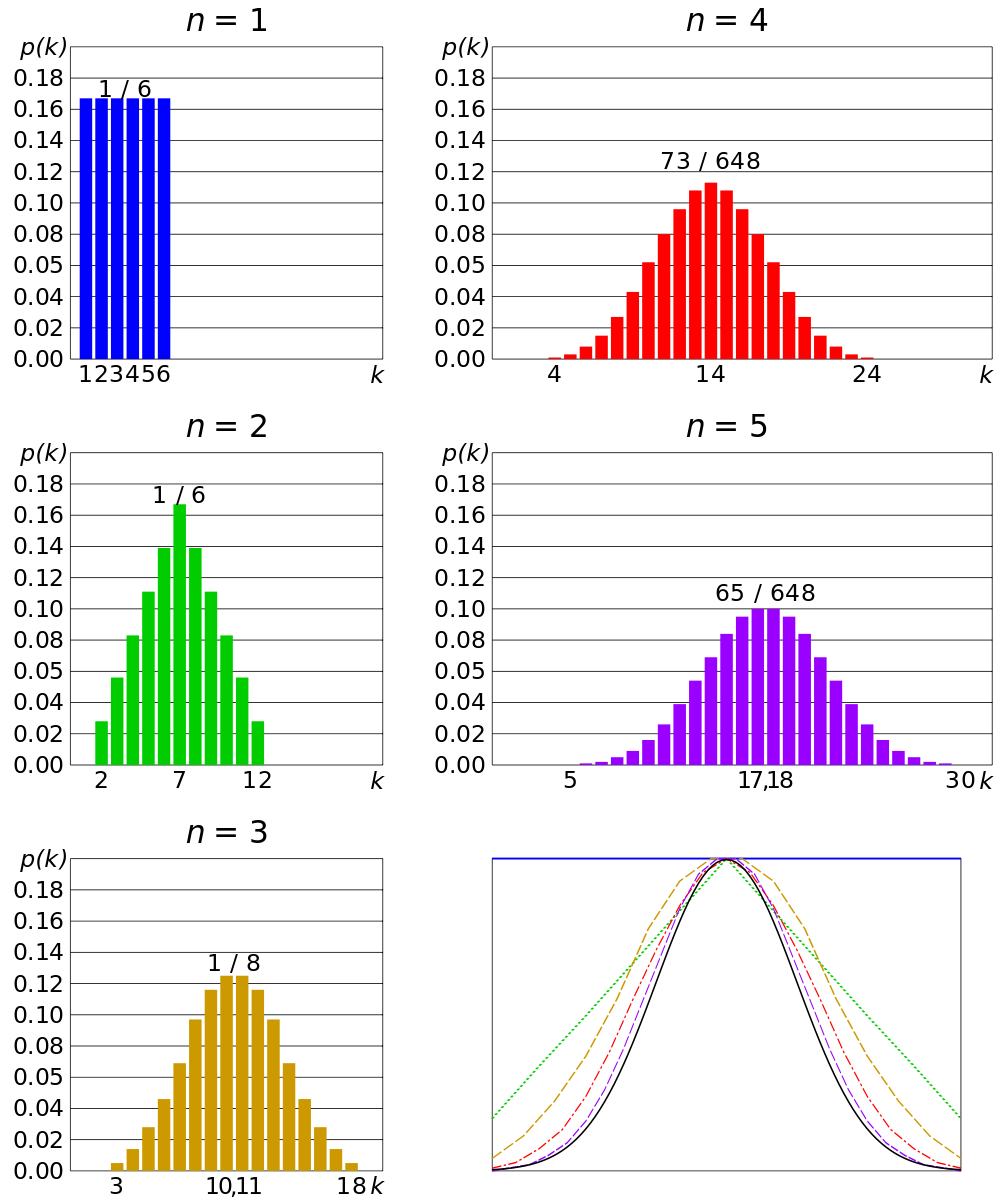
[출처] https://commons.wikimedia.org/wiki/File:Dice_sum_central_limit_theorem.svg, Cmglee
$X_1$ $X_2$, $...$, $X_n$이 평균 $\mu$와 분산 $\sigma^2$을 갖는 임의의 $i.i.d.$ 확률변수들이라고 할 때, $n$이 충분히 크다면 $X_1$ $X_2$, $...$, $X_n$의 표본평균 $\overline{X}$는 평균 $\mu$와 분산 $\dfrac{\sigma^2}{n}$을 갖는 정규분포에 가까워진다.
표본분산을 구할 때 $N$이 아니라 $N-1$로 나누는 이유는 불편(unbiased) 추정량을 구하기 위해서다. 직관적으로 이해하면, 평균은 샘플의 수가 증가해도 편차가 서로 상쇄되어 샘플이 적을 때와 비교해도 크게 차이가 나지 않는 반면에 분산은 0보다 크거나 작은 값인 편차의 제곱이 모든 샘플에 관해 더한 것을 샘플의 수로 평균을 내므로 샘플의 수가 많아질수록 표본분산이 더 커지게 된다. 그래서 표본의 수가 적을 떄 최대한 모분산에 가까워지도록 $N-1$로 나누는 것이다. 수학적으로도 유도가 가능한 부분이다.
표집분포의 기댓값 $E[\overline{X}] = \mu$
표본분산의 기댓값 $E[S^2] = \sigma^2$
최대가능도 추정법(Maximum Likelihood Estimation, MLE)
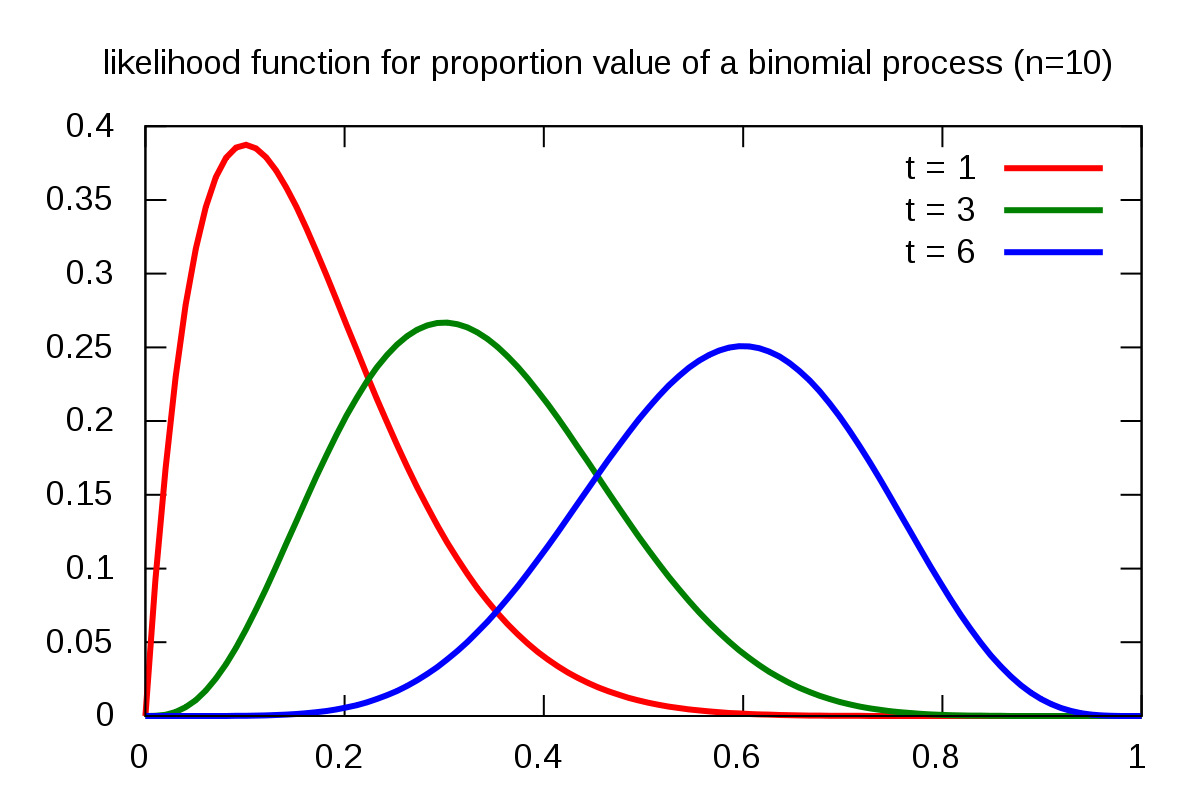
[출처] https://commons.wikimedia.org/wiki/File:MLfunctionbinomial-en.svg, Casp11
확률분포마다 사용하는 모수가 다르므로 적절한 통계량이 달라진다.
데이터가 실제로 어떤 확률분포인지 알기 위해서는 어떤 모수를 사용하는 게 효과적인지를 알아야 한다.
그래서 가장 가능성이 높은 모수를 추정해야 하며, 이러한 방법에는 최대가능도 추정법 (MLE)이 있다.
데이터를 잘 설명할 가능성이 가장 높은 모수 또는 확률분포를 추정하는 방법 = 최대가능도 추정법
$\hat{\theta}_{MLE}=argmax_{\theta}L(\theta;\mathbf{x})=argmax_{\theta}P(\mathbf{x}|\theta)$
위의 식에서 표현된 $\theta$는 모수를 의미하고, 정규분포에 대입하면 $\theta = (\mu, \sigma)$이다.
확률밀도함수는 모수 $\theta$에 대해 x에 대한 함수로 해석을 하지만, 가능도 함수는 주어진 데이터 x에 대해 모수 $\theta$를 변수로 둔 함수를 의미한다.
즉, 데이터가 주어져 있는 상황에서 모수$\theta$를 변형시킴에 따라 값이 바뀌는 함수로 이해하면 된다.
다시 말해, 모수 $\theta$를 따르는 어떤 분포가 우리에게 주어진 데이터 $\mathbf{x}$를 관측할 가능성을 의미하고, 이 가능성이 높다는 의미는 반대로 우리에게 주어진 데이터가 해당 분포를 따를 가능성이 높다는 의미이다.
그래서 확률로 해석하면 안 되고 가능성으로 이해해야 한다.
로그가능도 추정법
데이터 집합 X가 독립적으로 추출되었을 경우 로그가능도 추정법으로 사용이 가능하다.
로그가능도를 사용했을 때 얻는 장점은 다음과 같다.
- 데이터의 수가 매우 클 경우 컴퓨터의 정확도로 가능도를 계산하는 건 불가능한데, 이 가능도의 곱셈을 로그를 통해 로그가능도의 덧셈으로 바꿀 수 있어서 컴퓨터로 연산이 가능하다.
- 경사하강법으로 가능도를 최적화하면 미분을 수행하는데 있어서 연산량을 획기적으로 줄일 수 있다. 가능도 함수는 $O(n^2)$이나, 로그가능도 함수는 $O(n)$이기 때문이다.
정규분포의 최대가능도 추정법
정규분포를 따른다고 가정한 데이터의 가능도 함수는 다음과 같다.
$$ \hat{\theta}_{MLE}=argmax_{\theta}L(\theta;\mathbf{x})=argmax_{\mu,\sigma^2}P(\mathbf{X}|\mu,\sigma^2) $$
위의 식에 Log를 씌은 로그 가능도 함수는 다음과 같이 전개된다.
$$ \log{L(\theta;\mathbf{X})}= \sum_{i=1}^{n}\log{P(x_i|\theta)} =-\frac{n}{2}log_2\pi\sigma^2-\sum_{i=1}^{n}{\frac{|x_i-\mu|^2}{2\sigma^2}} $$
해당 식에서 최대값을 만족하는 $\mu$와 $\sigma^2$를 찾는 방법은 편미분값이 0이 되는 지점을 찾는 것이다. 각 모수로 편미분한 값은 다음과 같다.
$$ \begin{align} \frac{\partial{logL}}{\partial{\mu}}&=-\sum_{i=1}^{n}{\frac{x_i-\mu}{\sigma^2}}=0\\ \frac{\partial{logL}}{\partial\sigma}&=-\frac{n}{\sigma}+\frac{1}{\sigma^3}\sum_{i=1}^{n}{|x_i-\mu|^2}=0 \end{align} $$
이를 통해 모수를 추정하면 다음과 같아진다.
$$ \begin{align} \hat{\mu}_{MLE}&=\frac{1}{n}\sum_{i=1}^{n}{x_i}\\ \hat{\sigma}^2_{MLE}&=\frac{1}{n}\sum_{i=1}^{n}({x_i-\mu})^2 \end{align} $$
MLE는 불편추정량을 보장하지는 않으므로 추정된 모수는 $n-1$이 아닌 $n$으로 나눈 값이다.
딥러닝에서 최대가능도 추정법
최대가능도 추정법을 통해 기계학습 모델을 학습시킬 수 있다.
분류 문제의 경우, 각 데이터의 최종 결과는 해당하는 Class에 대해서만 1 값을 갖는 One-Hot 인코딩된 Vector이다.
One-Hot Vector인 $\mathbf{y}$는 카테고리 분포로부터 생성되었다고 가정할 수 있다. 카테고리 분포의 모수를 모델링하는 것을 통해서 Input $x$에 대한 추정이 가능해진다.
카테고리 분포의 MLE는 모든 경우의 수를 세어서 해당 카테고리에 속할 비율을 구하는 것이다.
$$ p_k = \frac{n_k}{\sum_{k=1}^dn_k} $$
정답 레이블을 관찰 데이터로 이용해 확률분포인 소프트맥스 벡터의 로그가능도를 최적화 할 수 있고, 이를 통해 딥러닝 모델의 가중치($\theta$)를 최적화 할 수 있다.
$$ \hat{\theta}_{MLE}=argmax_{\theta}\frac{1}{n}\sum_{i=1}^{n}\sum_{k=1}^{K}{y_i,k}\log{(MLP_{\theta}(x_i)k)} $$
확률분포의 거리
기계학습에서 사용되는 손실함수는 모델이 학습하는 확률분포와 데이터에서 관찰되는 확률분포의 거리를 통해 유도한다.
데이터 공간에 두개의 확률분포 $P(x)$, $Q(x)$가 있을 경우, 두 확률분포 사이의 거리를 계산할 때 KL Divergence 함수 등을 이용할 수 있다.
분류 문제에서 정답 레이블을 $P$, 모델 예측을 $Q$라고 가정하게 된다면, 최대가능도 추정법은 쿨백-라이블러 발산을 최소화 하는 것과 동일한 의미를 갖는다.
출처
1. 네이버 부스트캠프 AI Tech Stage 1 수학 기초 강의
'AI > AI 수학' 카테고리의 다른 글
| [인공지능 기초] Uncertainty(2) - 결합 확률과 조건부 확률 그리고 베이즈 정리 (0) | 2023.01.21 |
|---|---|
| [인공지능 기초] Uncertainty (1) - 확률적인 추정을 위한 확률과 사건, 그리고 명제 (0) | 2022.12.30 |
| 확률(Probability)과 딥 러닝(Deep Learning) (0) | 2022.02.14 |
| 미분과 경사하강법(Gradient Descent) (1) | 2022.02.14 |
| 나이브 베이즈 정리(Naive Bayes Theorem)와 나이브 베이즈 분류(Naive Bayes Classification) (0) | 2022.01.20 |
Contents
소중한 공감 감사합니다.