AI/AI 기본
Self-Attention을 사용하는 Transformer(트랜스포머)
- -
Sequential Model
Sequential Model이 어려운 이유
언어 문장을 예로 들면 완벽한 문장 구조에 대응되도록 문장을 만드는 경우는 흔치 않은데, 이러한 문제는 sequential model에 있어서 난관이다.
또한 기존 Seq2Seq 모델은 고정된 크기의 context vector에 source 문장 정보를 압축하는데, 이는 병목(bottleneck)을 발생시켜 성능 하락의 원인이 된다.
하나의 문맥 vector가 source 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하된다는 문제가 있다.
그래서 매번 source 문장에서의 출력 전부를 입력으로 받는 것이 transformer의 아이디어이다.
최근 트렌드는 입력 시퀀스 전체에서 정보를 추출하는 모델로 발전하는 방향이다.
Transformer
Transformer is the first sequence transduction model based entirely on attention.
Transformer는 sequential data를 처리하고 이를 encoding하는 방법이어서 NMT(신경망 기계 번역)문제에만 국한되어 적용되지 않으며, 다양한 영역(CV, Text to Image 등)에서 사용되고 있다.
입력 sequence와 출력 sequence의 도메인과 길이가 다를 수 있다.
Self-attention 구조 또는 encoder에서는 RNN처럼 입력 data의 길이만큼 재귀적으로 돌지 않으며, encoder 부분에서 parallel하게 처리 가능하다.
![]()
Transformer에 대한 궁금증을 크게 세 가지로 정리하면 다음과 같은데, 이를 기반으로 Transformer를 분석해 볼 것이다.
- N개의 단어가 어떻게 한 번에 encoder에서 처리가 되는지?
- Encoder와 decoder 사이에서 어떠한 정보를 주고 받는지?
- Decoder가 어떻게 단어를 generation 할 수 있는지?
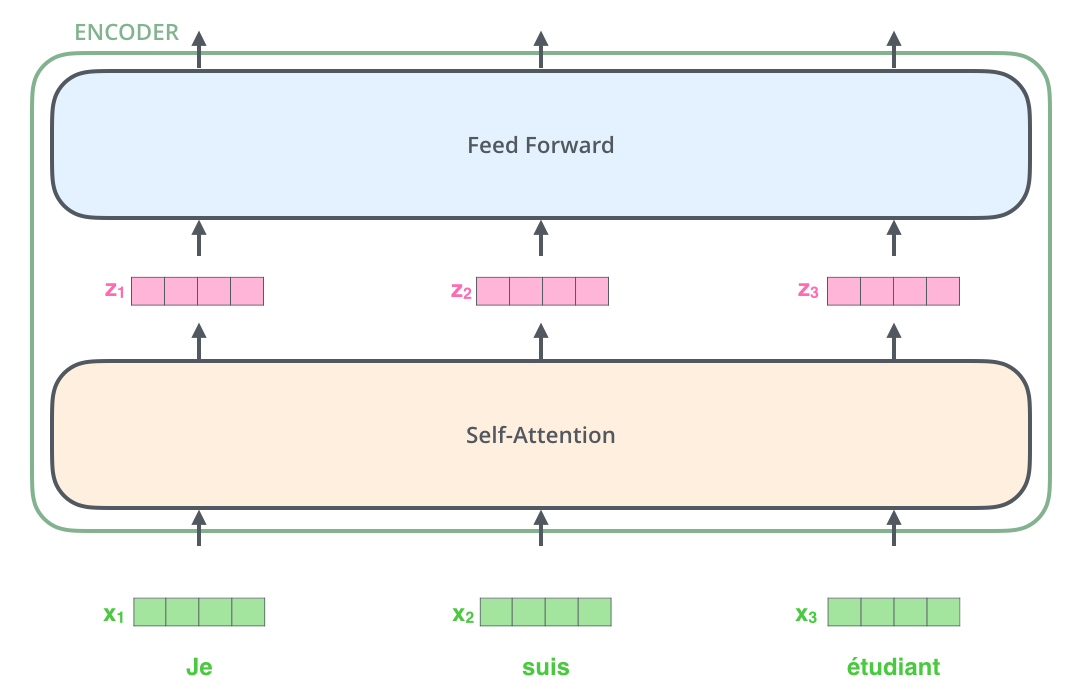
Encoder
![]()
Encoder = Self-Attention + Feed Forward Neural Network
Transformer 이전에 입력 값을 embedding하는 작업을 거친다.
즉, 각각의 단어는 embed_dim 차원의 각 원소마다 continuous한 값을 지니는 vector로 표현될 수 있다.
Self-Attention
The Self-Attention is both encoder and decoder is the cornerstone of Transformer.
Self-attention의 경로들은 다른 입력값들에 대해 의존적이다.
기본적으로 input으로 주어지는 단어는 기계가 번역할 수 있도록 특정 수의 벡터로 표현된다.
첫 번째 self-attention은 각 단어를 그에 맞는 벡터를 각각 찾아준다.
그런데 self-attention에서 하나의 단어를 벡터로 만들 때, 한 단어만 활용하는 게 아니라 자신을 포함한 나머지 $N$개의 벡터도 같이 활용한다.
나머지 self-attention에서도 단어에 해당되는 벡터를 다른 벡터로 만들 때, 한 단어 벡터만 활용하는 게 아니라 $N$개의 벡터도 같이 활용한다.
입력 길이가 길어질 때마다 계산을 많이 필요로 하여 메모리를 더 필요로 한다는 한계가 있다.
![]()
The animal didn't cross the street because it was too tired.
문장을 이해하려면 각 단어가 어떤 다른 단어에 dependent 한지를 알아야 한다.
예를 들어, 위 문장에서 it이 참조하는 것을 알려면 it의 어떤 단어에 대한 의존성이 가장 높은지 찾아야 한다.
![]()
Self-Attention 구조가 각각의 단어 vector마다 만드는 vector
- Query
- Key
- Value

각 단어마다 세 개의 vector를 만들고, 이 세 개의 vector를 통해서 단어에 대한 embedding vector를 새로운 vector로 만들어 준다.
![]()
각 단어마다 Score 스칼라값을 구하는데, 이는 encoding 하고자 하는 단어의 query vector와 모든 $N$개의 단어에 대한 key vector를 구해서 이 두 개를 inner product 한다.
Query vector와 key vector를 내적하는 부분으로 인해 이를 dot-product attention이라고 한다.
한 단어 벡터가 다른 단어 벡터와 얼마나 유사도가 있는지 또는 interactive 한지를 구하기 위해 score를 내적으로 계산하는 것이다.
여기서 이 score는 유사도의 개념으로 이해해도 좋다.
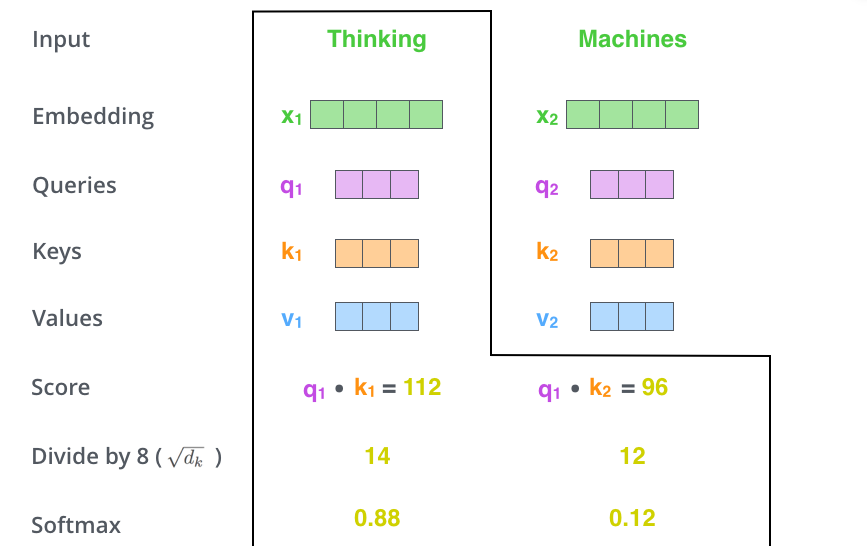
이를 통해 key value의 차원인 $d_k$로 각 score를 나눠줘서 normalization하고, softmax를 적용해서 attention weight을 구한다.
이처럼 key value의 차원으로 나눠서 스케일링하는 부분 때문에 "scaled dot-product attention"이라고 불린다.

각 단어마다 나온 value vector의 weighted sum을 구한 것이 새롭게 encoding된 vector이다.
즉, value vector의 weight를 구하는 과정이 각 단어에서 나오는 query vector와 key vector를 통해 score vector를 구하는 것이다.
그래서 value vector와 softmax의 결과 vector를 곱한다.

$$ \text{Attention Score}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_K}})V $$
query vector와 key vector의 차원은 같아야 하지만, value vector는 차원이 달라도 된다.
성능 향상을 위해 attention을 수행하기 전에 skip connection을 주어서 residual learning을 진행한다.
Transformer가 작동을 잘 하는 이유
이미지 하나가 주어졌을 때, 이를 CNN이나 multi-layer perceptron에 적용하면 input과 network가 fix되어 있는 경우 출력이 고정된다.
Transformer는 하나의 input이 고정되어 있다고 하더라도 자신이 인코딩하려는 단어와 그 옆에 있는 단어들에 따라서 인코딩된 값이 달라질 수 있다.
그래서 상대적으로 flexible하고 좀 더 많은 표현력을 지니는 특징을 갖는다.
Transformer의 한계
$N$개의 단어를 한 번에 처리해야 하고, computational cost가 $N^2$에 비례하므로 이를 처리하는 데 있어서 한계가 있다.
Muti-Headed Attention
![]()
입력에서 embedding된 한 vector에 관해서 query(Q), key(K), value(V) vector를 하나만 사용하는 게 아니라 여러 개를 사용하는 것이다.
입력으로 들어 온 것을 embedding vector로 만든 후, 이 embedding vector의 차원을 $n$개의 동일한 크기의 차원으로 나누어서 각각의 크기의 embedding vector에 관해 각 head에 대응되는 query, key, value vector를 생성한다.
이를 통해 만들어진 query, key, value vector를 가지고 각 head마다 scale dot product attention을 진행하는 것이다.
예를 들어, 512라는 크기의 차원을 지닌 입력의 embedding vector가 있고, 8개의 multi-head를 가지고 attention 작업을 수행할 때, 이 512를 8로 나눈 64만큼의 크기로 입력의 embedding vector를 나눠서 각각에 대응되는 query, key, value vector를 생성하여 8개의 head마다 scale dot product attention을 수행한다.
![]()
Attention head에 따라 encoding되어서 나오는 출력 vector의 차원이 같아야 하는데, 이는 linear map을 통해서 차원을 맞춰준다.
![]()
Positional Encoding
![]()
Encoding된 vector에 bias를 더하는 것 또는 offset을 주는 것과 유사하다.
Transformer는 sequence와 관련한 정보를 지니지 않는데, 이는 self-attention의 연산 과정에서 input order에 indepedent 하기 때문이다.
이를 보완하기 위해 순서 또는 위치에 관한 정보를 부여하고자 주어진 입력에 어떠한 값을 더하는 것이다.
(예: 문장 번역에 있어서 input 문장의 어떤 단어가 앞에 오고 어떤 단어가 뒤에 오는지 network에 알려줘야 한다.)
Encoder에서 Decoder로 정해지는 정보
![]()
가장 상위 encoder에 있는 key vector와 value vector를 decoder의 MHA의 입력으로 보낸다.
즉, 마지막 encoder layer의 출력을 decoder의 모든 layer의 MHA가 참고할 수 있도록 보낸다.
![]()
Encoder-Decoder Attention layer에서는 Multi-Headed Attention처럼 작동하지만, Decoder에 들어가는 입력은 이전까지 generation된 단어들만 들어가고 이에 대한 query vector를 만든다. Encoder에서 key vector와 value vector를 가져온다.
Decoder
Decoder에 들어가는 입력으로 주어지는 query vector와 상위 encoder에서 쓰인 key vector와 value vector를 가지고 최종 출력이 나온다.
최종 출력은 하나의 단어씩 auto-regressive하게 나온다.
Self-Attention with Masking
Decoder 단계에서는 i번째 단어를 만드는 과정에서 모든 문장에 대한 단어를 알 필요가 없으므로 이전 단어들에 관해서만 dependent하고 그 이후 단어들은 masking을 하여 미래에 있는 정보를 활용하지 않는다.
Encoder-Decoder Attention
상위 Encoder에서 나온 key, value를 이용해 attention을 구하는 부분이다.
Final Layer
![]()
단어들의 분포를 만들어서 그중 가장 확률이 높은 단어를 sampling 한다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech RecSys Track
2. Jay Alammar, https://jalammar.github.io/illustrated-transformer
'AI > AI 기본' 카테고리의 다른 글
| Attention 기법을 사용한 Seq2Seq with Attention (0) | 2022.07.14 |
|---|---|
| 생성 모델(Generative Model)과 VAE 그리고 GAN (1) | 2022.02.17 |
| 순차 데이터와 RNN(Recurrent Neural Network) 계열의 모델 (0) | 2022.02.17 |
| 딥 러닝에서의 일반화(Generalization)와 최적화(Optimization) (0) | 2022.02.16 |
| 신경망(Neural Network)과 다층 퍼셉트론(Multi Layer Perceptron) (0) | 2022.02.16 |
Contents
소중한 공감 감사합니다.