AI/AI 기본
순차 데이터와 RNN(Recurrent Neural Network) 계열의 모델
- -
Sequential Model
Sequential Data
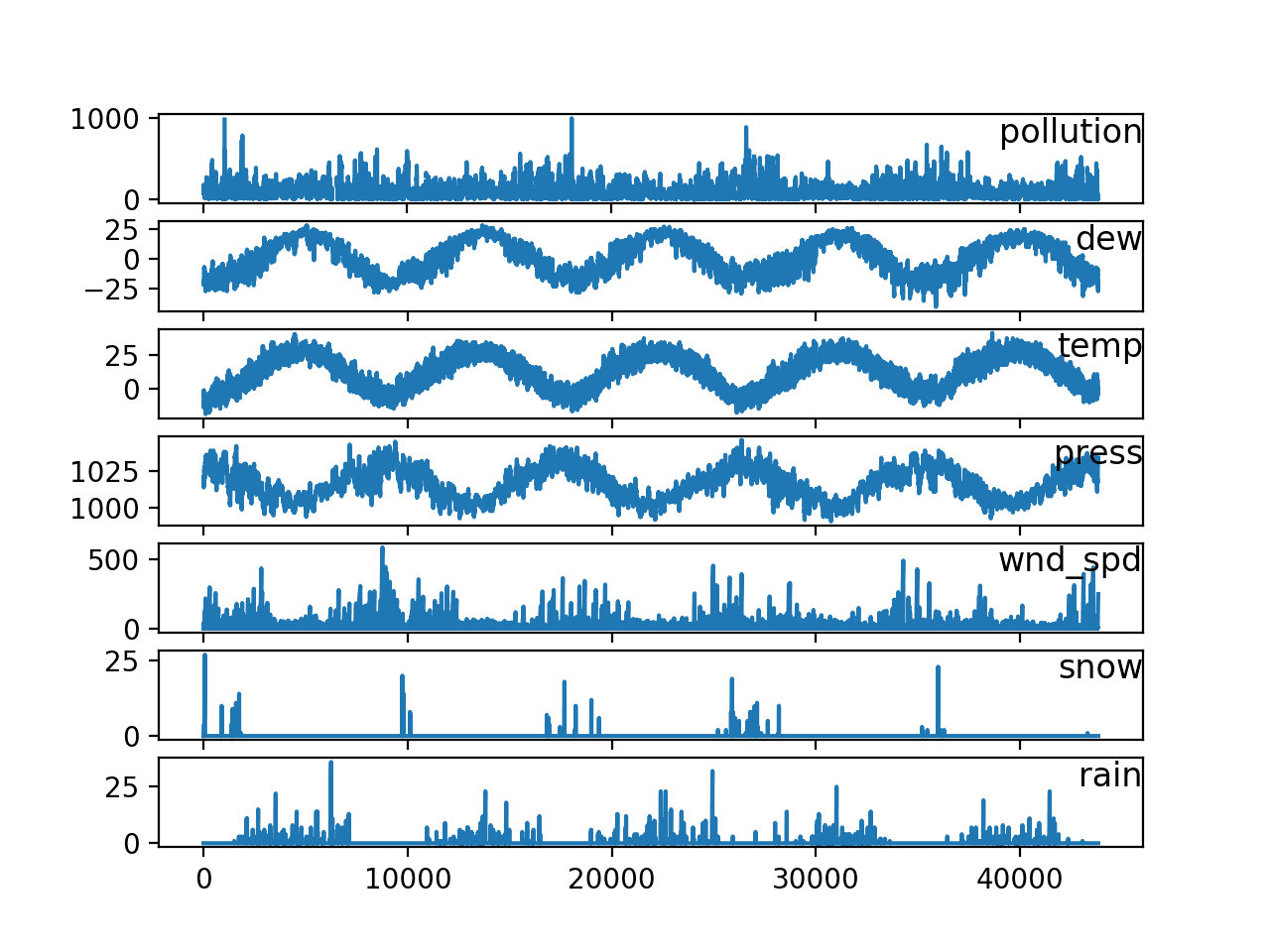
[출처] https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras
일상적으로 접하는 데이터는 대부분 sequential data이다. (예: 음성, 비디오 등)
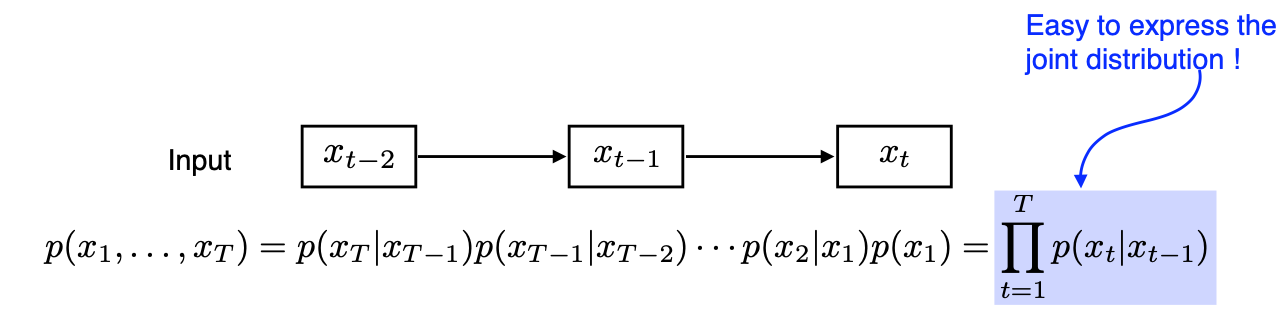
Naive Sequence Model
$$ p(x_t | x_{t-1}, x_{t-2}, \cdots) $$
시간이 지남에 따라 고려해야 하는 데이터의 개수가 계속 증가한다.
길이가 주어지지 않아서 받아들여야 하는 데이터의 입력의 차원을 알 수 없다는 단점이 있다.
Autoregressive Model
$$ p(x_t | x_{t-1}, x_{t-2}, \cdots, x_{t-\tau}) $$
Naive sequence model에서는 고려해야 하는 과거의 데이터 양이 늘어난다는 점이 문제이므로 past timespan을 고정시켜서 특정 개수의 과거 데이터만을 고려하는 방법을 사용할 수 있다.
Markov Model (First-Order Autoregressive Model, AR(1) Model)
$$ \displaystyle \prod_{t=1}^T p(x_t | x_{t-1}) $$
현재는 바로 이전의 과거에만 dependent하다는 가정을 바탕으로 하는 모델이다.
바로 전 과거 데이터만 사용하여 많은 정보들을 버릴 수 있게 된다.
Joint distribution을 표현하기에 쉬워진다는 장점이 있다.
Latent Autoregressive Model
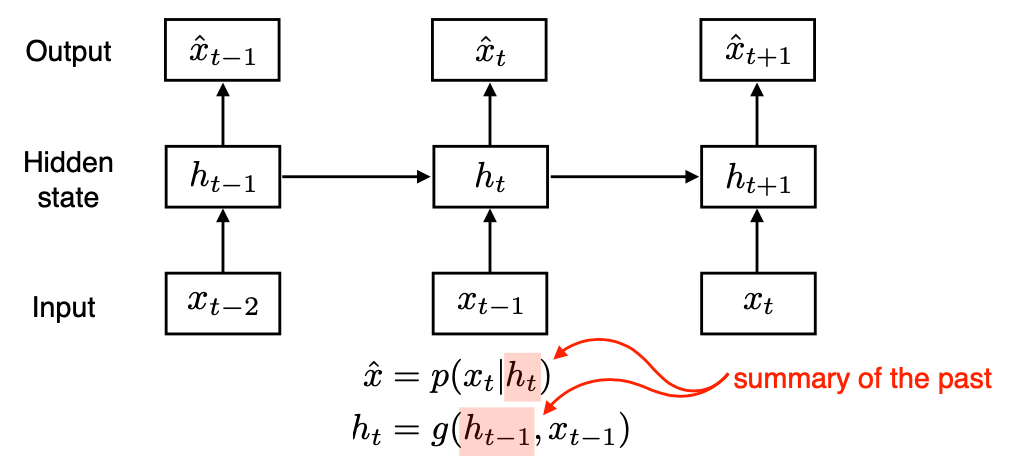
$$ \begin{align} \hat{x} &= p(x_t|h_t)\\ h_t &= g(h_{t-1}, x_{t-1}) \end{align} $$
중간에 hidden state가 들어가는데, 이 hidden state가 과거의 정보를 요약해서 갖고 있다.
다음 번 time step은 이전 hidden state 하나에만 dependent하다.
Recurrent Neural Network (RNN)
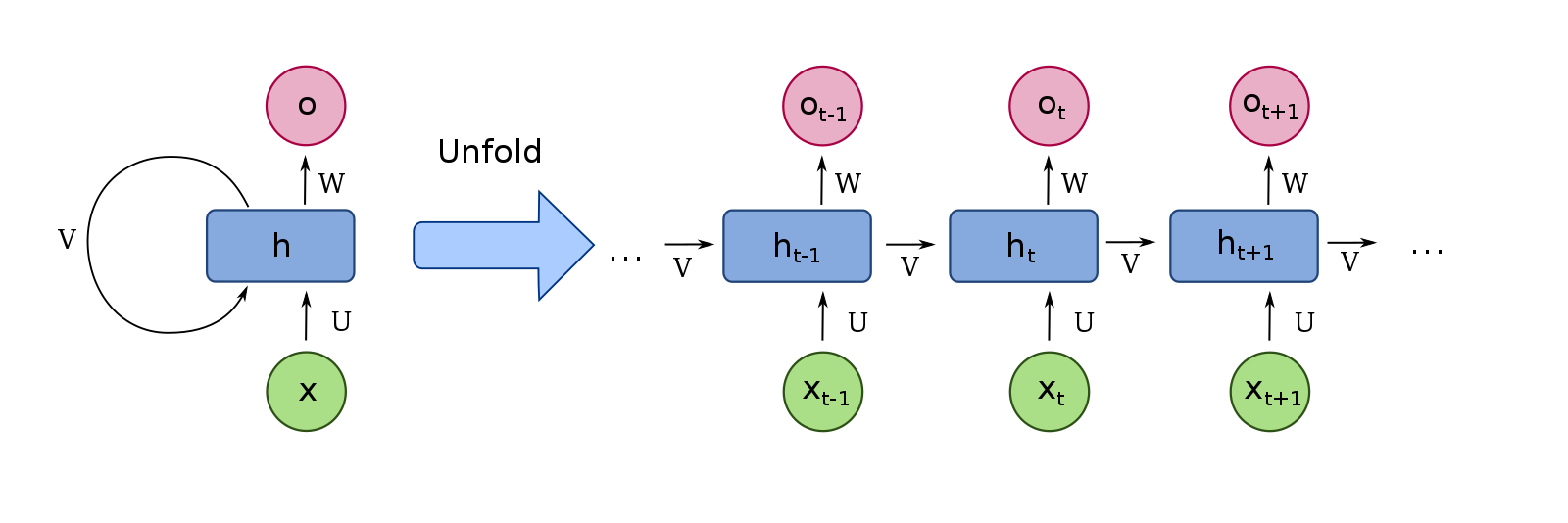
[출처] https://commons.wikimedia.org/wiki/File:Recurrent_neural_network_unfold.svg, fdeloche
MLP인 Autoregressive 모델과는 달리 자기 자신으로 돌아오는 구조가 있는 것이 특징이다.
$h_t$인 hidden state는 $x_t$에만 dependent하지 않고 이전의 $t_1$에서 얻어진 self state에 관해서도 dependent하다.
Time step을 고정하고 시간 순으로 풀게 되면 결국 각각의 parameter를 share하는 입력이 굉장히 많은 fully connected layer가 된다고 볼 수 있다.
Short-Term Dependencies
과거에 얻어진 정보가 다 취합되어 요약되어서 미래에 고려되어야 하는데, RNN에서는 먼 과거의 정보가 반영되지 않는 현상이 발생한다.
$$ \begin{align} h_1 &= \phi(W^Th_0 + U^Tx_1)\\ h_2 &= \phi(W^T\phi(W^Th_0 + U^Tx_1) + U^Tx_2)\\ h_3 &= \phi(W^T\phi(W^T\phi(W^Th_0 + U^Tx_1) + U^Tx_2) + U^Tx_3) \end{align} $$
점점 hidden state에서 vanishing(sigmoid, tanh 등) 또는 exploding(ReLU) gradient 문제가 발생한다.
Long Short Term Memory (LSTM)
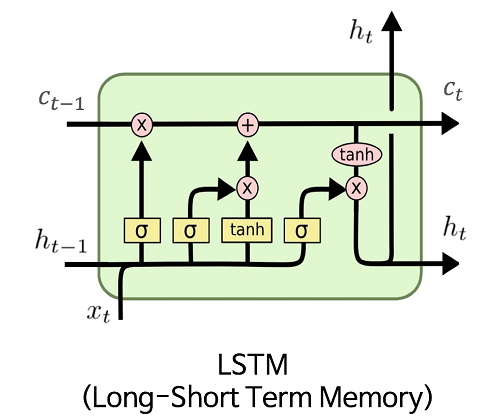
[출처] https://commons.wikimedia.org/wiki/File:LSTM.png, MingxianLin
- Input ($x_t$)
- Previous cell state ($C_{t-1}$)
- Time stamp $t$까지 들어온 정보의 요약을 가지고 있다.
- 마치 컨베이어 벨트처럼 이제까지의 정보 중 어떤 것을 빼고 어떤 것을 넘길지가 정해진다.
- Previous hidden state (Previous output, $h_{t-1}$)
- Output (Next hidden state, $h_t$)
핵심 아이디어는 중간에 cell state를 통해 이전 정보와 현재 정보를 함께 요약하는 것이다.
LSTM Gate 구성
Forget Gate
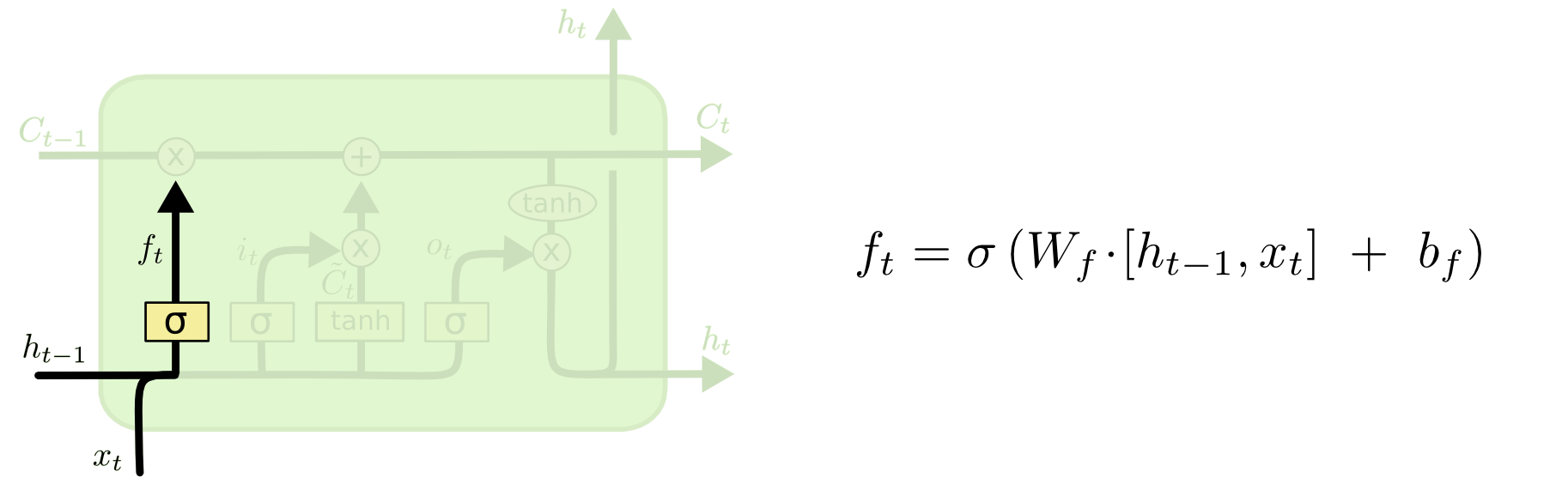
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
- 이전 hidden state와 현재 time step의 input을 가지고 이들 중에서 어떠한 정보를 버릴지를 정한다.
- $f_t = \sigma(W_f\cdot[h_{t-1}, x_t] + b_f)$
Input Gate
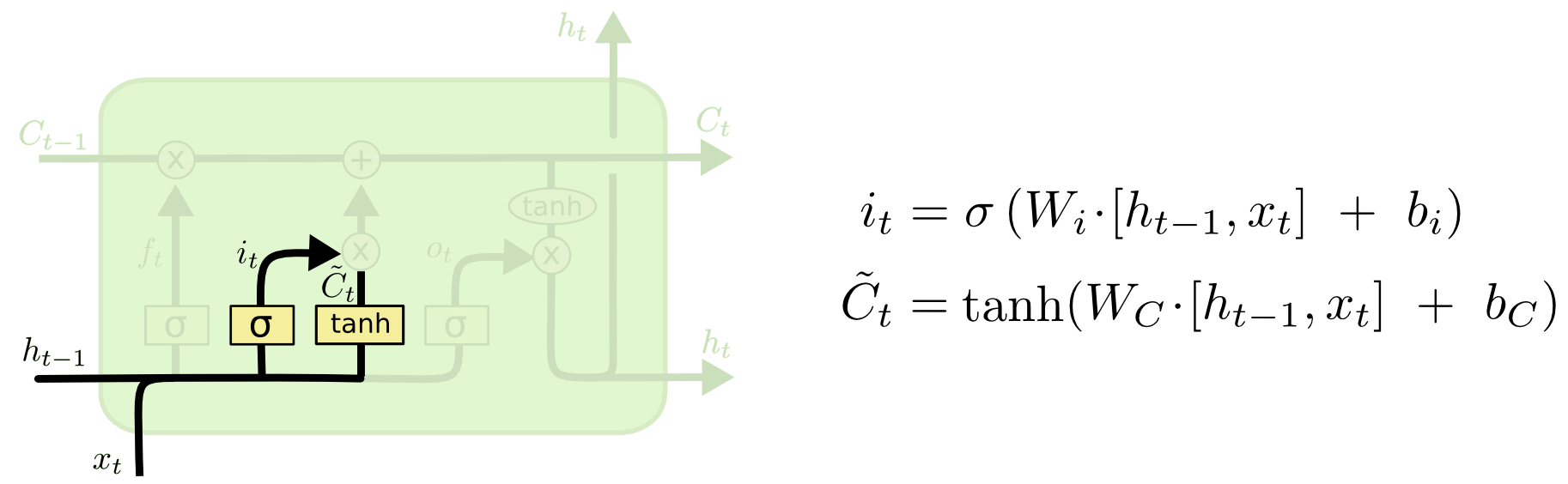
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
- 이전 hidden state와 현재 time step에서의 input을 가지고 이들 중 어떠한 정보를 저장할지를 정한다.
- $i_t = \sigma(W_i\cdot[h_{t-1}, x_t] + b_i)$
- $\tilde{C}_t = \tanh(W_C\cdot[h_{t-1}, x_t] + b_C)$
- 새로운 cell state에 포함될 예비 후보라고 생각해볼 수 있다.
Update Gate
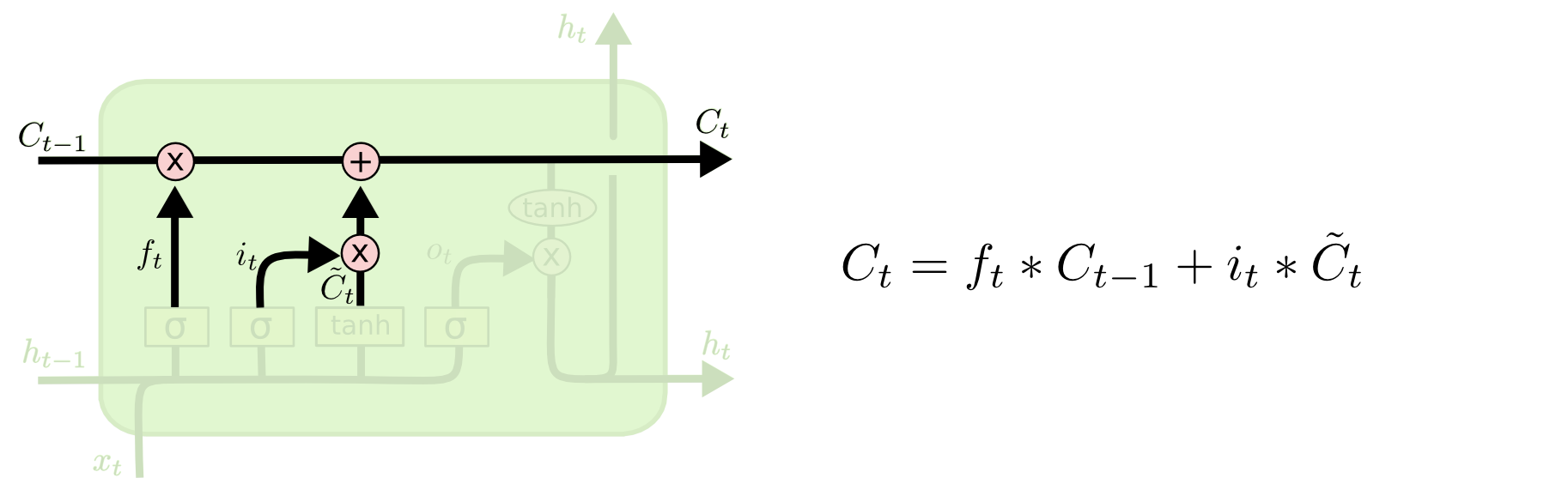
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
- cell state를 업데이트한다.
- $i_t = \sigma(W_i\cdot[h_{t-1}, x_t] + b_i)$
- $C_t = f_t * C_{t-1} + i_t * \tilde{C}_t$
Output Gate
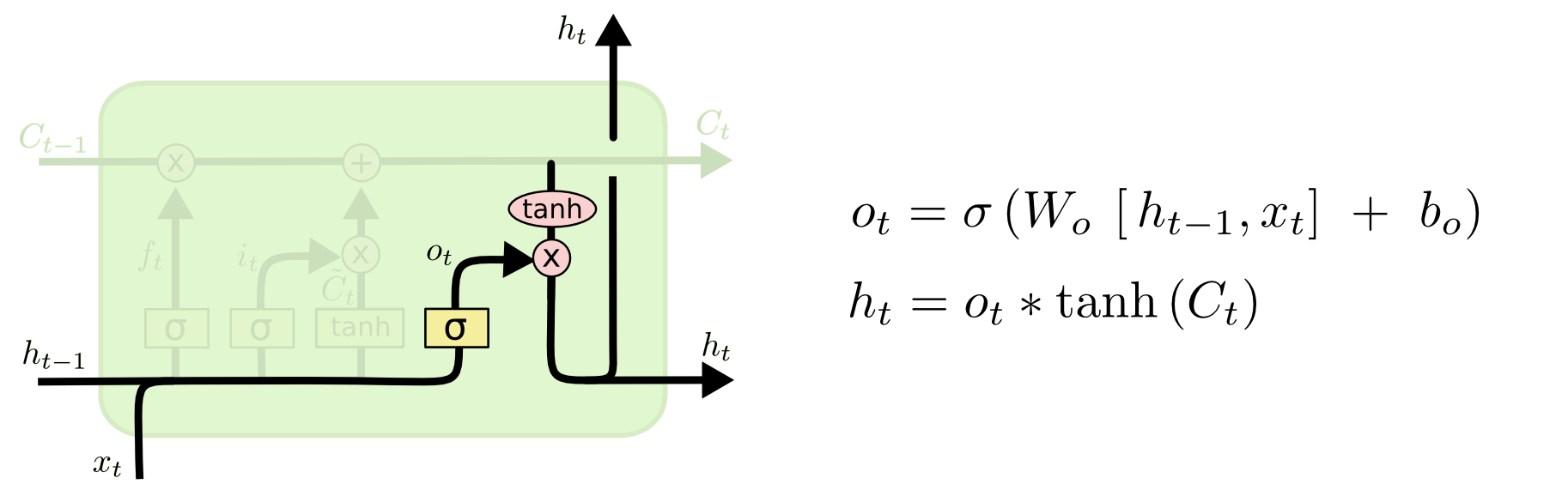
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
- $o_t = \sigma(W_o\cdot[h_{t-1}, x_t] + b_i)$
- $h_t = o_t * \tanh{(C_t)}$
Gated Recurrent Unit (GRU)
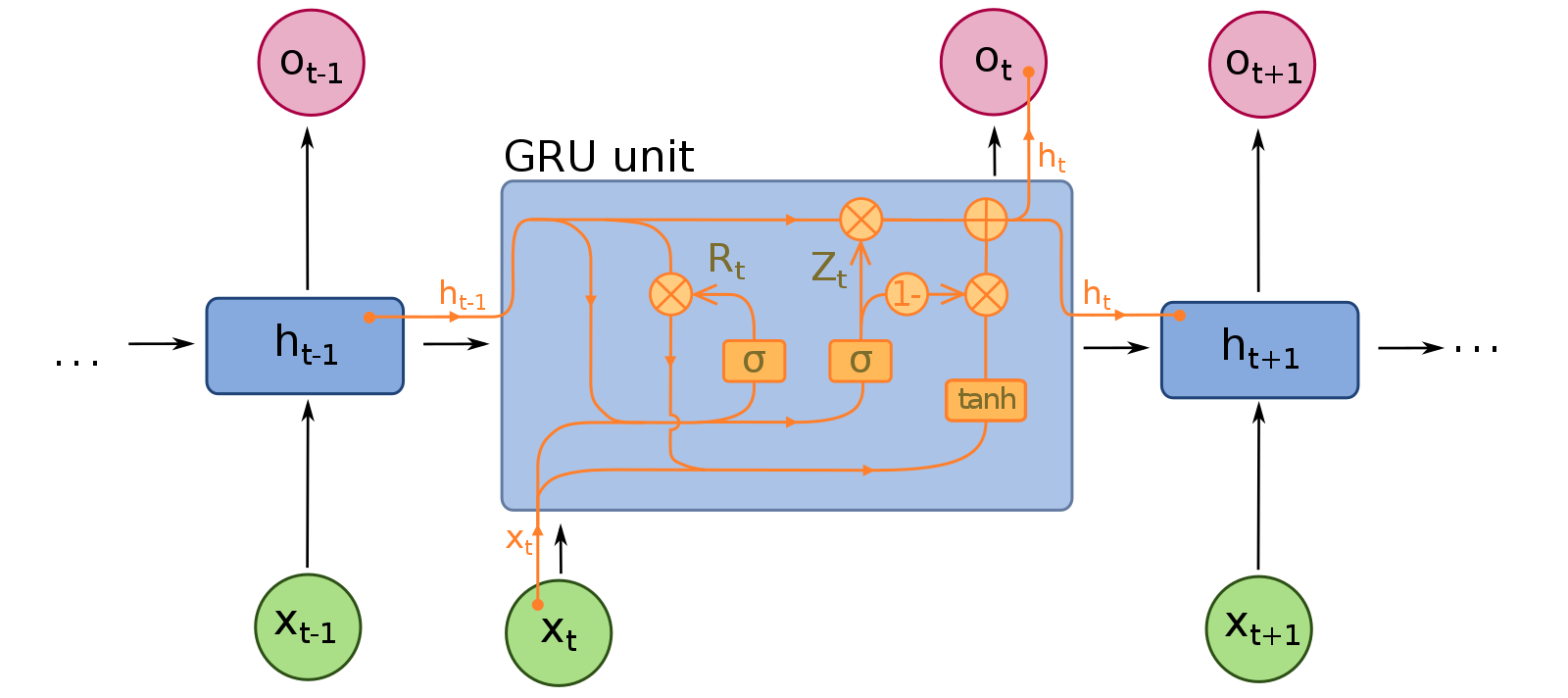
[출처] https://commons.wikimedia.org/wiki/File:Gated_Recurrent_Unit.svg, fdeloche
Gate로 reset gate와 update gate 두 가지 있다.
LSTM에서는 cell state가 있고, 이를 output gate를 거쳐서 hidden state이자 output을 내보냈지만, GRU에서는 cell state가 없으며 output gate를 사용하지 않는다.
Network의 파라미터가 적어서 generalization performance가 올라가는 경우가 종종 있다.
RNN 코드
class RecurrentNeuralNetworkClass(nn.Module):
def __init__(self,name='rnn',xdim=28,hdim=256,ydim=10,n_layer=3):
super(RecurrentNeuralNetworkClass,self).__init__()
self.name = name
self.xdim = xdim # Q: input의 차원
self.hdim = hdim # D: hidden state(= output state)의 차원
self.ydim = ydim # LSTM의 출력 차원 (10개의 분류 레이블에 대한 각각에 속할 확률)
self.n_layer = n_layer # K: layer의 개수
self.rnn = nn.LSTM(
input_size=self.xdim,
hidden_size=self.hdim,
num_layers=self.n_layer,
batch_first=True
# batch_first = True이면
# 출력 차원은 [batch_size, seq_len, output_dim]
# 즉, [N × L × Q] → [N × L × D]가 된다.
)
self.lin = nn.Linear(self.hdim,self.ydim)
def forward(self,x):
# x: [N × L × Q]
# input의 차원인 Q만큼(이미지에서 한 줄씩) RNN의 input인 x로 들어간다.
# 이를 L번만큼 recurrent를 도는 것이다.
# hidden state와 cell state를 0으로 초기화한다.
# hn: [K x N x D]
# cn: [K x N x D]
h0 = torch.zeros(
self.n_layer, x.size(0), self.hdim
).to(device)
c0 = torch.zeros(
self.n_layer, x.size(0), self.hdim
).to(device)
# RNN
# x: [N x L x Q] → rnn_out: [N x L x D]
rnn_out,(hn,cn) = self.rnn(x, (h0,c0))
# 차원 변환을 위한 Linear Layer
out = self.lin(
rnn_out[:,-1]
# 마지막 hidden state를 linear layer의 입력으로 넣는다.
).view([-1,self.ydim])
return out
R = RecurrentNeuralNetworkClass(
name='rnn',xdim=28,hdim=256,ydim=10,n_layer=2).to(device)
loss = nn.CrossEntropyLoss()
optm = optim.Adam(R.parameters(),lr=1e-3)
print ("Done.")
아래 링크는 RNN을 사용하여 AG NEWS 뉴스 데이터셋의 기사를 분류하는 모델을 구현하는 실습이다.
https://glanceyes.tistory.com/entry/PyTorch로-RNN-모델-구현해보기-AG-NEWS-뉴스-기사-주제-분류
PyTorch로 RNN 모델 사용해 보는 예제 - AG NEWS 뉴스 기사 주제 분류
현재 활동 중인 빅데이터 연합동아리인 BITAmin에서 RNN에 관한 세션에서 발표를 진행했는데, 그때 Vanilla RNN 사용과 함께 PyTorch로 RNN을 사용한 모델을 구현하는 내용도 같이 강의하려고 실습 자료
glanceyes.tistory.com
출처
1. 네이버 부스트캠프 AI Tech 추천시스템 Stage 1 기초 강의
'AI > AI 기본' 카테고리의 다른 글
| 생성 모델(Generative Model)과 VAE 그리고 GAN (1) | 2022.02.17 |
|---|---|
| Self-Attention을 사용하는 Transformer(트랜스포머) (0) | 2022.02.17 |
| 딥 러닝에서의 일반화(Generalization)와 최적화(Optimization) (0) | 2022.02.16 |
| 신경망(Neural Network)과 다층 퍼셉트론(Multi Layer Perceptron) (0) | 2022.02.16 |
| 딥 러닝에서 알아두어야 할 요소와 역사적으로 중요한 모델 (0) | 2022.02.16 |
Contents
소중한 공감 감사합니다.