AI/NLP
Self-supervised Model인 GPT-1과 BERT 분석 및 비교
- -
Self-supervised Pre-Training Model
이번 포스팅에서는 이전에 설명한 transformer의 self-attention block을 기반으로 하는 대표적인 self-supervised pre-training model인 GPT-1과 BERT에 관해 알아보고자 한다.
Self-supervised Learning
Self-supervised Learning이란?
여기서 self-supervised learning이라는 용어가 나오는데, 이는 레이블이 주어지지 않은 데이터를 가지고 사용자가 정한 pretext task를 통해 pre-training을 진행하고, 기학습이 완료된 모델을 여러 다른 downstream task에 fine-tuning하여 사용하고자 transfer learning을 수행한다.
Self-supervised learning에서 pre-training을 위해 사용하는 데이터 자체는 레이블이 주어지지 않은 데이터이지만, pretext task을 목표로 pre-training 하는 과정 자체에서는 pretext task의 목적에 맞게 데이터에 레이블을 새롭게 부여하는 방법 등 supervision을 직접 만든다.
아래에서 GPT-1과 BERT 소개 부분에서도 설명하고 있지만, 다양한 문장으로 이루어진 긴 지문을 가지고 pretext task을 목적으로 pre-training하는 사례를 들면 해당 지문의 일부를 일정 확률에 의해 임의로 마스킹하고, 마스킹된 단어에 원래 어떠한 단어가 들어가야 하는지를 지도학습을 하는 것이다.
또한 지문으로 주어지는 여러 문장 사이의 논리적 관계를 추론하기 위해 모델의 입력 sequence에 문장간의 관계를 예측하기 위한 새로운 token을 하나 추가하여 문장들이 서로 모순인지 아닌지를 지도학습하는 것도 속한다.
Self-supervised learning에서 사용하는 데이터 자체에는 레이블이 처음이 주어지지 않으므로 비지도학습(unsupervised learning)의 일종이라고 대개 말하지만, 사실 모델이 pre-training 과정에서 자신의 pretext task 목적에 맞게 레이블이 부여되지 않은 데이터를 일부 변형 또는 가공하여 스스로 지도학습을 수행한다고 볼 수 있다.
최근 Self-Supervised Learning의 동향
Transforer와 self-attention block은 범용적인 sequence의 encoder와 decoder이며, 최근까지도 다양한 분야에서 좋은 성능을 보이는 것으로 알려져 있다.
Transformer는 self-attention block을 6개만 사용한다면, 최근 모델은 모델의 구조 자체에 관한 큰 변경점 없이 self-attention block을 많이 쌓아서 이를 대규모 학습 데이터를 통해 self-supervised learning을 진행한 후 다양한 downstream task에서 전사 학습과 같은 방법으로 fine-tuning 하여 좋은 성능을 내는 방향으로 발전하고 있다.
그러나 self-attention을 기반으로 하는 transformer 모델도 단어를 순차적으로 처음부터 끝까지 생성해 나가는 greedy decoding이라는 틀에서 벗어나지 못하는 한계점을 지니고 있다.
Self-Supervised Pre-Training Model과 다른 SOTA Model 간의 비교
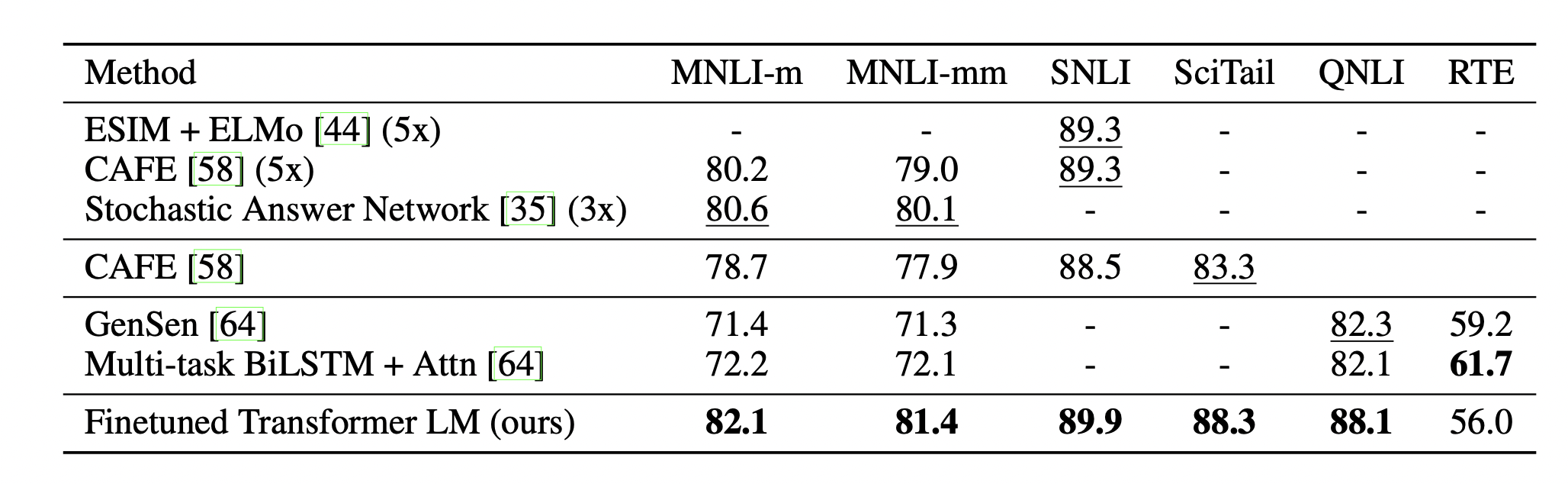
[출처] https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf, Improving Language Understanding by Generative Pre-Training
기존에 방대한 데이터로 학습된 transformer 기반 모델을 특정 task에 맞게 fine-tuning한 모델과 특정 task만을 위해 커스터마이징된 모델을 비교했을 때도 일반적으로 더 나은 성능을 보이는 것으로 알려져 있다.
GPT-1
GPT란?

GPT(Generative Pre-trained Transformer)는 테슬라의 창업자인 일론 머스크가 세운 비영리 연구 기관인 openAI에서 나온 모델이며, 최근 GPT-2부터 GPT-3까지 이어지는 모델을 통해 탁월한 자연어 생성 성능을 보이고 있다.
GPT-1의 특징
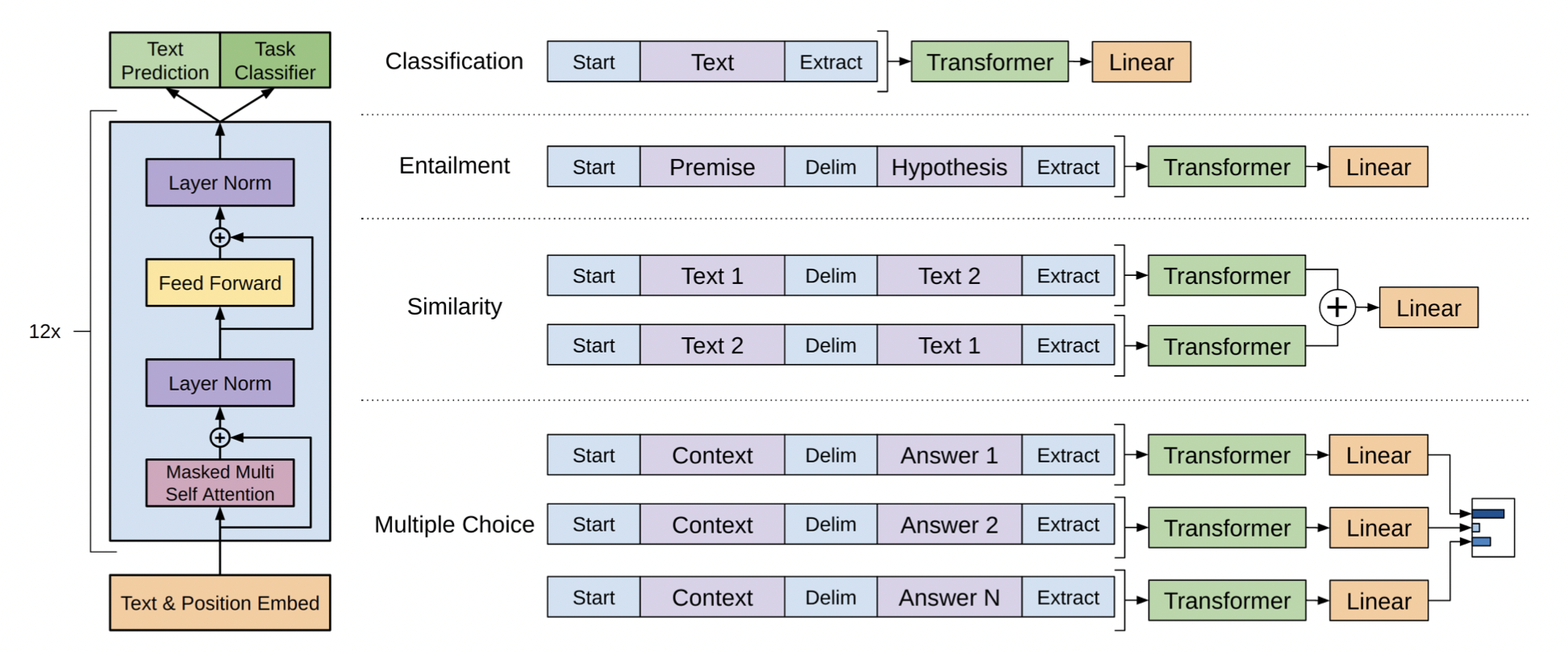
[출처] https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf, Improving Language Understanding by Generative Pre-Training
GPT-1은 12개의 transformer block을 사용했으며, encoder 없이 decoder만을 가진다.
또한 transformer block의 masked multi self-attention block에서는 12개의 head를 사용하고, 인코딩 벡터의 차원을 768로 만들어 사용한다.
그리고 활성 함수(Activation Function)으로 GELU를 사용한 점이 특징이다.
그러나 GPT-1에서 가장 주목할 만한 점은 바로 <Start>, <Extract> 등 다양한 special token을 사용하여 여러 NLP 태스크를 동시에 포괄할 수 있는 통합된 모델을 제안했다는 것이다.
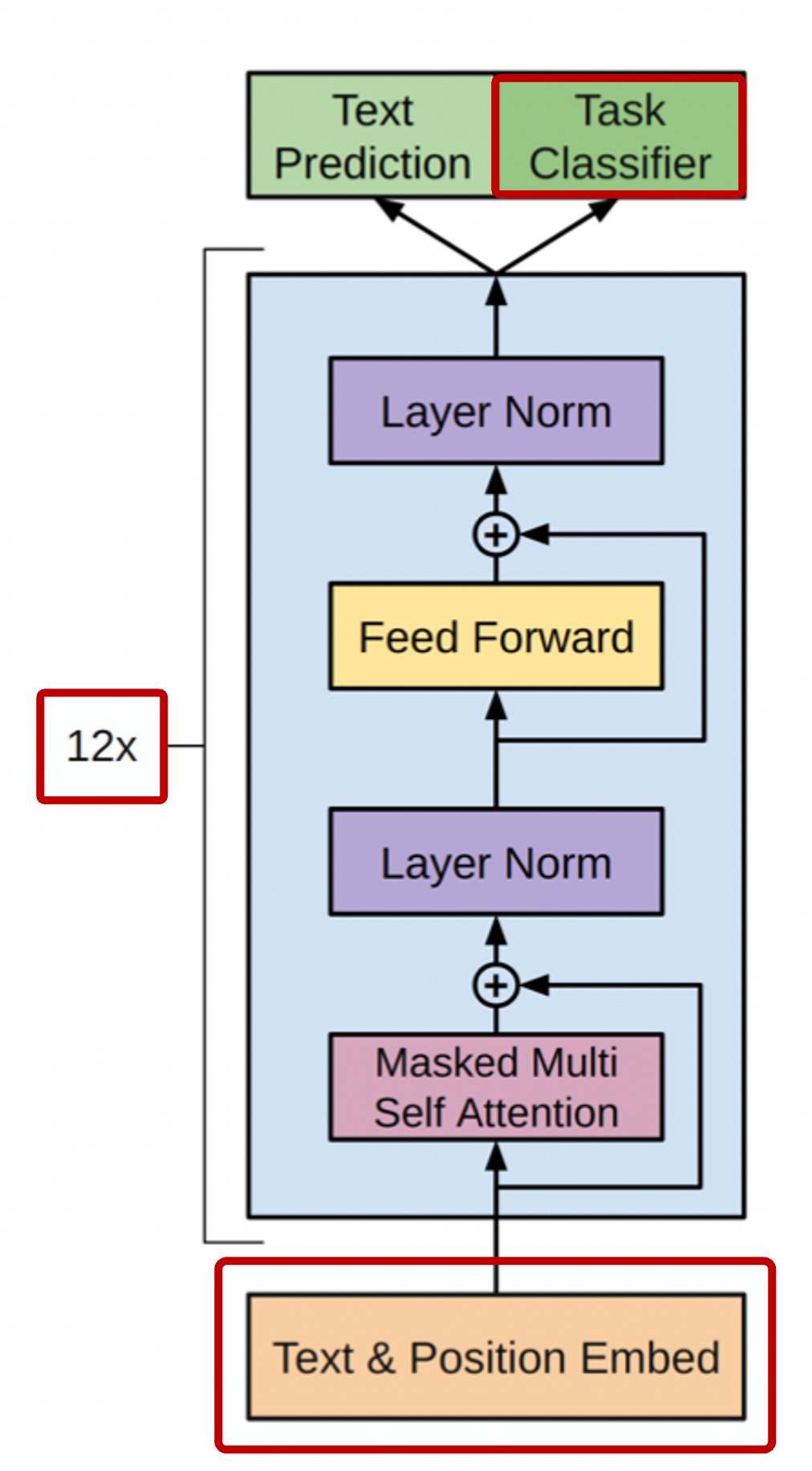
주어진 텍스트 sequence에 position embedding을 더한 후, self-attention을 기반으로 하는 block을 12개 쌓은 형태의 구조를 지닌다.
이를 통해 outupt layer에서 첫 단어부터 다음 단어를 순차적으로 예측하는 언어 예측을 수행하는 것뿐만이 아니라 다수의 문장이 주어져도 모델의 구조에 큰 변형이 필요하지 않도록 하여 새롭게 레이블이 부여된 데이터를 분류하는 pretext task도 수행할 수 있다.
GPT-1의 Pre-Training과 Transfer Learning
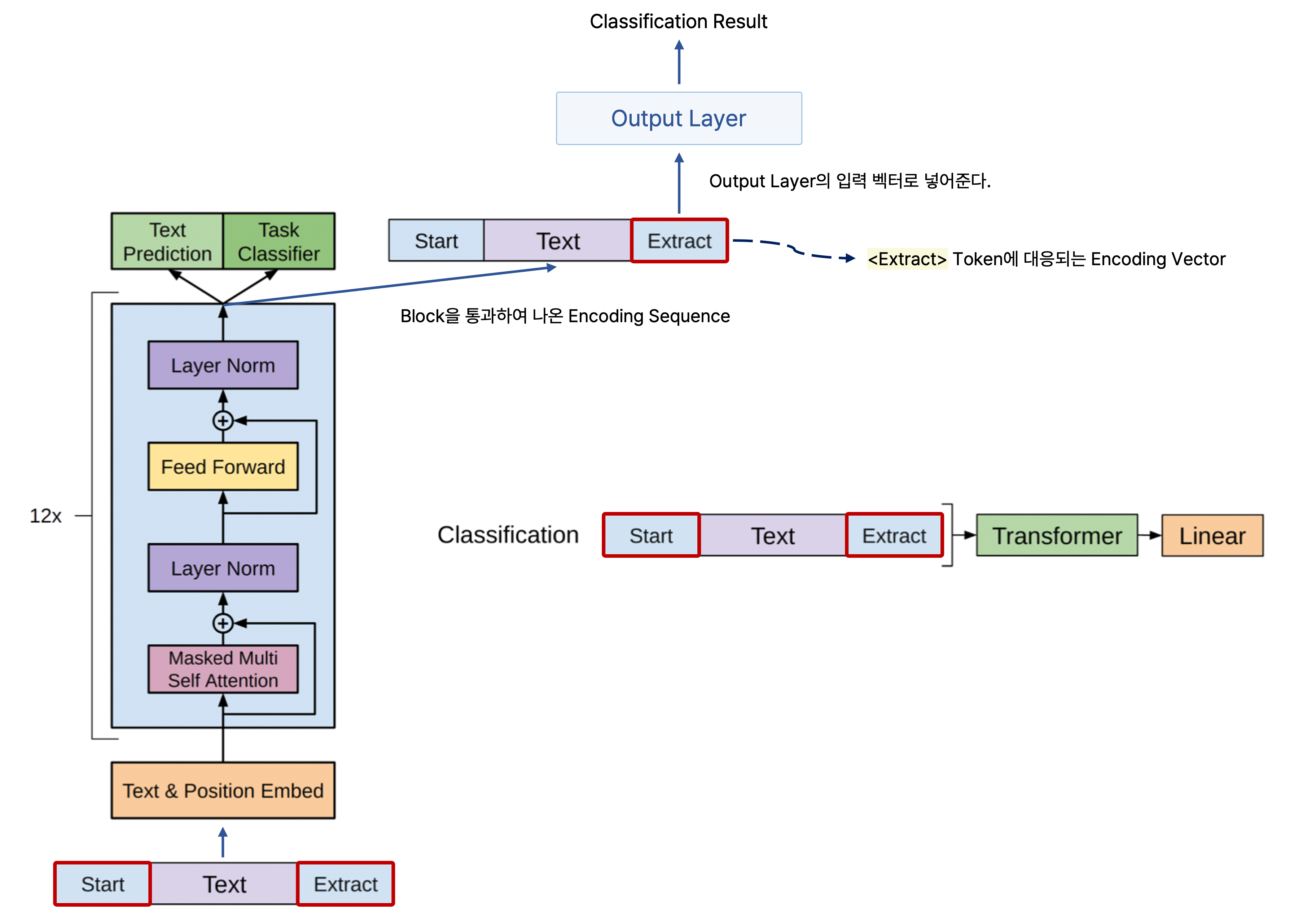
감정 분석(Sentimental analysis)과 같은 classification task를 수행할 경우 어떤 문장이 주어졌을 때 <Start> token을 문장의 맨 앞에 넣고, 마찬가지로 문장이 끝나는 <end> token으로서 좀 더 특별한 역할을 하는 <Extract> token을 문장의 맨 뒤에 붙인다.
그리고 문장을 GPT-1 모델을 통해 인코딩한 후 나온 최종 인코딩 결과에서 <Extract> token에 해당되는 인코딩 벡터를 output layer의 입력 벡터로 넣어줌으로써 문장을 통한 감정 분석 등 분류 작업을 진행할 수 있다.
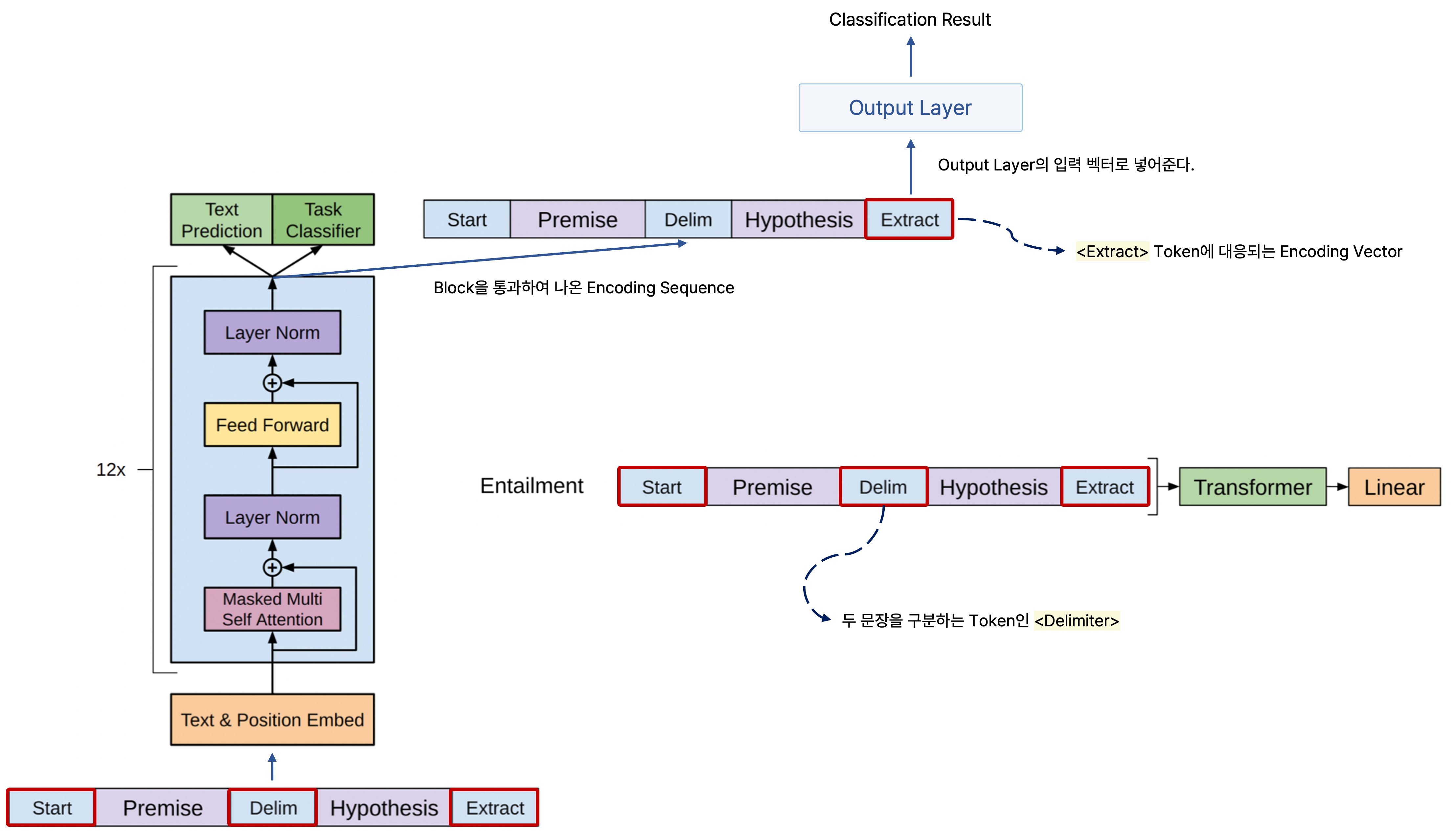
또한 전제가 주어지고 이를 통해 주어지는 가설의 참 또는 거짓을 판별하는 entailment task에서도 적용할 수 있다.
예를 들어, "섬 A에는 사슴이 현재 50마리가 산다."라는 문장이 주어졌을 때, "섬 A의 들판에는 현재 50마리를 넘는 사슴이 있을 수가 없다."라는 문장은 참이어야 하는 논리적인 내포관계를 바르게 찾아야 한다.
이러한 task에서는 다수의 문장으로 이루어진 문장을 입력으로 받아 예측을 수행해야 하는데, 이를 위해 GPT-1 모델에서는 여러 문장을 전제와 가설을 이어서 하나의 문장으로 만들되 문장 사이에 <Delimiter>라는 특수 문자인 구분자를 추가한다.
또한 분류 문제와 마찬가지로 문장의 처음과 마지막에는 각각 <Start>와 <Extract> token을 추가한다.
이처럼 합친 문장을 모델에 넣어서 인코딩하여 출력되는 문장에서 <Extract> token에 해당되는 벡터를 output layer에 통과시켜서 주어진 입력 문장이 논리적으로 귀결되는지 아니면 모순되는지를 분류하는 task를 수행할 수 있다.
결국 <Extractor>는 입력으로 주어질 때 마지막으로 추가하는 단순한 token인 것처럼 보이지만, 모델에 통과시켜서 문장을 잘 이해하고 감정 표현을 제대로 내릴 수 있는지 또는 문장 사이의 논리적 관계에 모순이 있는지를 판단할 수 있는 query로 사용되므로 downstream task에 필요로 하는 여러 정보를 주어진 입력 문장으로부터 추출할 수 있다.
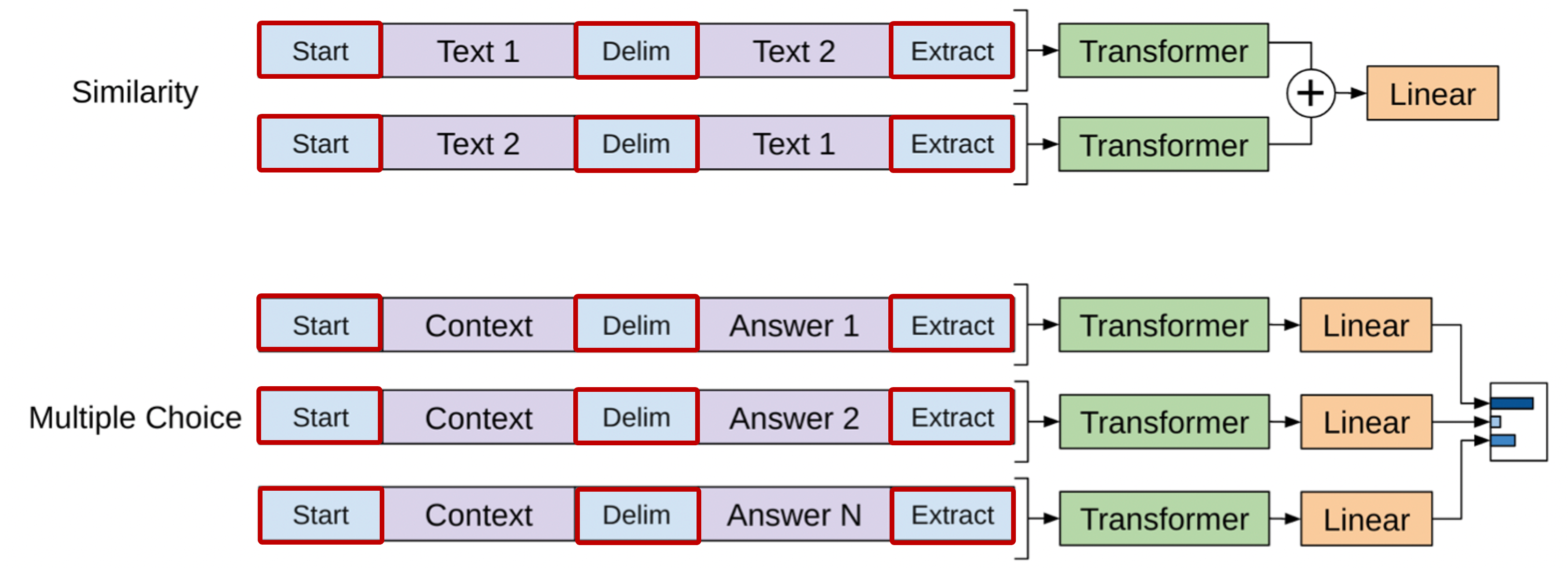
이외 여러 문장이 존재할 때 두 문장 간의 유사도를 측정하는 similarity task나 다수의 입력 문장에서 주어진 목적에 맞는 가장 적절한 문장을 선택하는 multiple chocie에도 GPT-1 모델을 적용할 수 있다.
이처럼 다음에 올 단어를 예측하는 task와 데이터에 관해 연구자가 정의한 pretext task를 pre-training 단계에서 통합적으로 학습한 GPT-1 모델을 소량의 데이터셋을 사용하는 다른 task를 수행하고자 할 때 전이 학습(transtfer learning)을 할 수 있다.
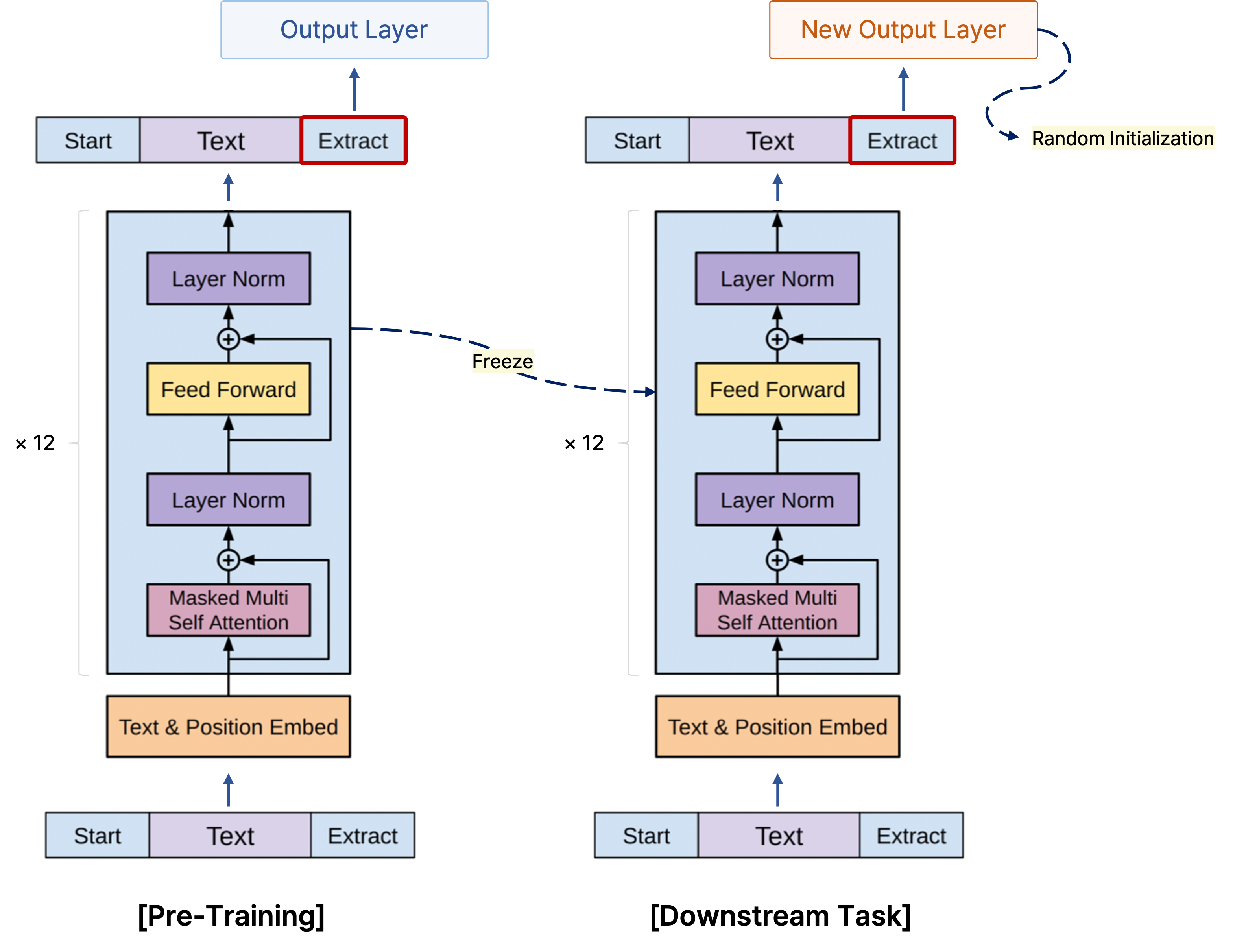
만약에 긍정 또는 부정을 예측하는 감정 분석을 학습한 GPT-1를 통해 뉴스 기사 분류를 위한 모델로 전이 학습하여 사용하고자 하는 경우, 마지막에 감정 분석을 위한 output layer는 떼어 버리고 전 단계에서 transformer의 출력으로 나오는 단어별 인코딩 벡터를 사용할 수 있다.
앞서 언급한 기학습된 transformer block에 뉴스 기사 분류를 위한 output layer를 추가하고, output layer에 관해 파라미터를 무작위로 초기화하는 random initialization을 수행한 후 뉴스 기사 분류 데이터를 가지고 전체 모델의 학습을 진행한다.
여기서 마지막 layer는 random initialization을 했으므로 충분한 학습이 진행되어야 하지만, 기학습된 transformer block에서는 학습 파라미터를 freeze하거나 learning rate를 상대적으로 작게 줘서 기존의 학습된 파라미터에 큰 변화가 일어나지 않도록 한다.
이를 통해 기존의 학습 내용을 잘 갖고 있으면서 동시에 적용하고자 하는 task를 위해 활용할 수 있게끔 한다.
다음에 올 단어를 예측하는 기학습 과정에서 사용한 데이터는 별도의 레이블링이 되지 않은 방대한 데이터셋인데 반해, 뉴스 기사 분류 task를 위한 학습 과정에서는 이미 레이블링이 된 상대적으로 소량의 데이터를 사용하게 된다.
그래서 기학습되는 단계인 pre-training에서 레이블이 부여되지 않은 데이터를 사용하는 self-supervised learning을 통해 대규모 데이터로부터 얻을 수 있는 지식을 학습하고, 이를 적용하고자 하는 task에 맞게 구조를 재설계하여 활용하는 흐름으로 이해할 수 있다.
BERT
BERT란?
[출처] https://arxiv.org/pdf/1810.04805.pdf, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
현재 글 작성 시점까지도 가장 널리 쓰이는 pre-trained 모델이며, GPT-1과 유사하게 문장에 등장하는 일부 단어를 맞힐 수 있도록 language modeling task를 위해 학습된 모델이다.
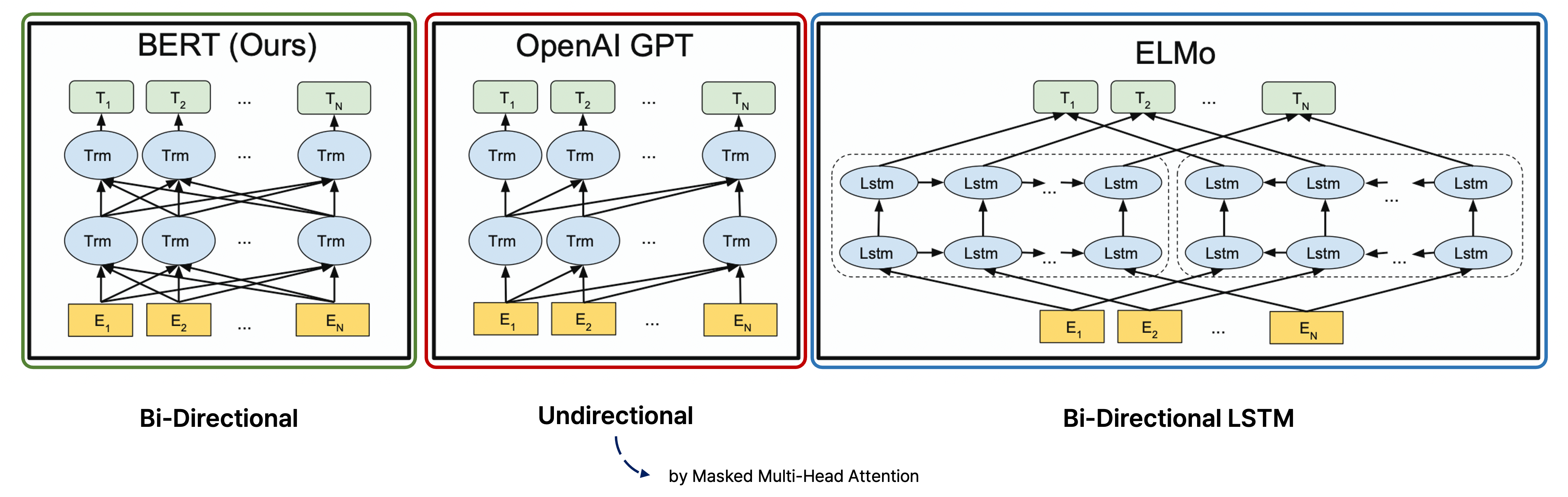
다음에 올 단어를 예측하는 task를 위해 학습하는 모델 중에서는 앞서 언급한 GPT-1도 있지만, transformer이 등장하기 이전에 양방향으로 LSTM 기반으로 학습하는 Bi-LSTM에 속하는 pre-trained 모델인 ELMo이 존재했다.
GPT와 BERT는 이 LSTM encoder를 transformer로 대체한 모델이며, 다음에 올 단어를 예측하는 task에서 더 많은 양의 지식을 학습할 수 있도록 고도화한 모델로 볼 수 있다.
GPT-1은 decoder-only transformer block에서 masked multi-head attention block을 통해 왼쪽 문장의 단어로부터 오른쪽 단어를 차례로 예측하는 방식을 통해 단방향으로 학습하지만, 이는 전후 맥락을 파악하지 못하고 앞의 문맥만을 보고 다음 단어를 예측하는 한계가 존재한다.
실제로 우리가 문장을 해석하거나 언어를 사용하는 상황을 고려해보면, 앞의 내용뿐만이 아니라 어떠한 부분의 앞뒤의 내용을 토대로 해당 문장의 내용을 유추하거나 더 잘 이해할 수 있는 경우가 있다.
그래서 BERT(Bidirectional Encoder Representations from Transformers)는 이처럼 한 방향으로 정보를 가지고 예측하는 게 아니라 양방향의 정보를 모두 참고하여 좀 더 유의미한 예측을 만들고자 하는 목적에서 제시된 모델이다.
BERT의 Pre-Training
Masked Language Model
BERT를 기학습시키는 방법으로 MLM(Masked Language Model)이 있는데, 이는 문장에서 각 단어를 일정 확률에 의해 [MASK] 등 다른 단어로 치환하고 원래의 단어를 예측하도록 학습을 진행하는 것이다.
얼만큼의 확률로 문장에서 단어를 다른 단어로 치환해야 하는지는 hyperparameter로 사용자가 직접 사전에 정의해야 한다.
예를 들어, 주어진 문장에서 15%에 해당하는 단어를 다른 단어로 치환한다면 다음과 같을 것이다.

치환하는 확률이 낮으면 overfitting될 가능성이 높고, 반대로 치환하는 확률이 높으면 주변 문맥을 파악해서 마스킹된 단어를 예측하기에 충분한 정보가 제공되지 않을 가능성이 높다.
그러나 치환하는 단어 확률을 모두 [MASK]로 치환하는 것은 부작용이 발생할 수 있다.
Pre-training 단계에서 치환하고자 하는 단어를 모두 [MASK]로 치환해서 모델이 학습하면 비록 마스킹된 단어를 예측하는 새로운 task에서는 문제가 되지 않더라도, 문단의 주제 분류 등 마스킹된 단어 예측과 거리가 먼 다양한 downstream task에 관해서는 제대로 예측이 이루어지지 않을 수 있다.
그래서 pre-training의 기반이 되는 task와 이를 전사 학습하여 사용하고자 하는 task의 학습 패턴이 상이해지는 것을 예방하고자 치환하려는 단어 전체를 [MASK]로만 치환하지는 않는다.
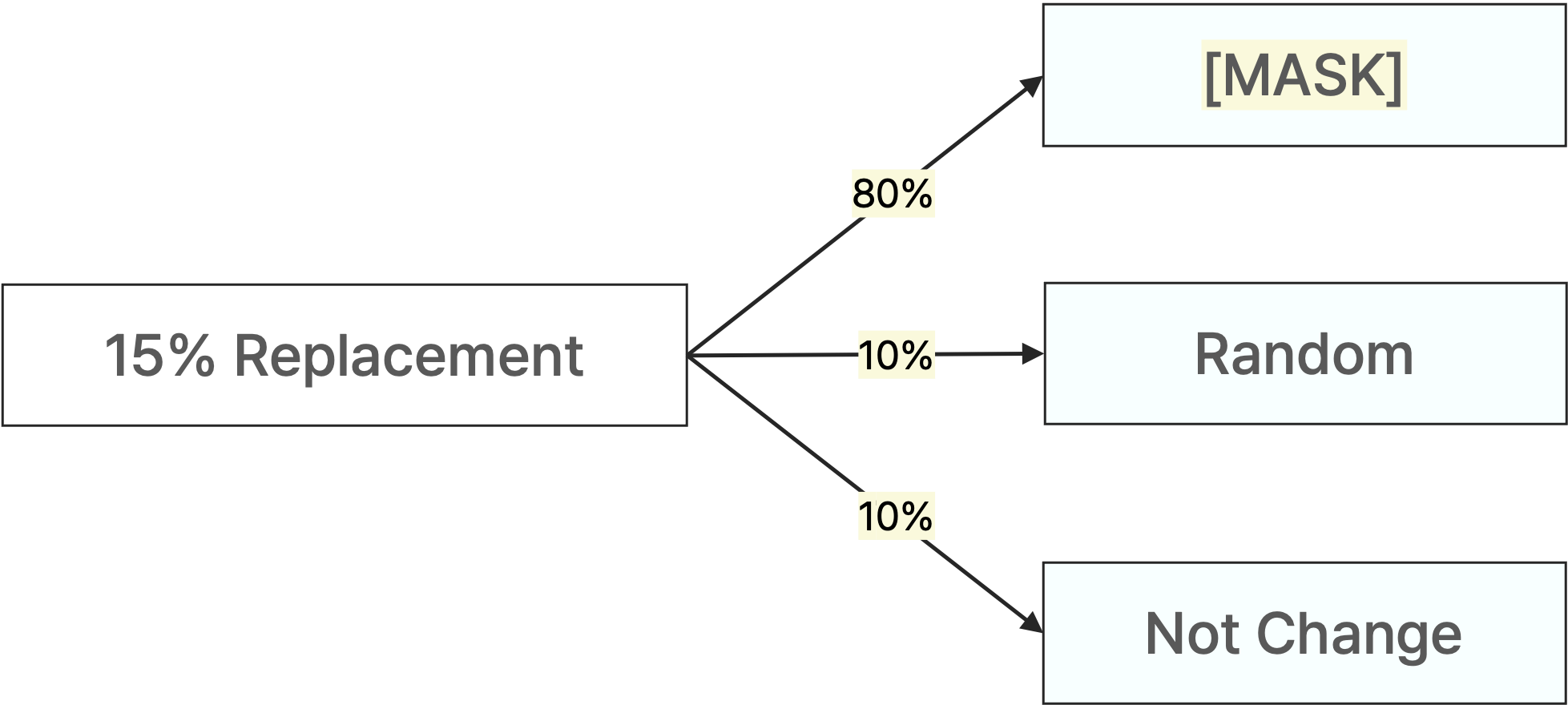
예를 들어, 치환하고자 하는 15% 단어 중에서 80%는 [MASK]로, 10%는 임의의 단어로, 나머지 10%는 치환하지 않고 그대로 두는 것처럼 확률에 의해 예측하고자 하는 단어를 어떻게 치환할지를 정할 수 있다.
그러면 모델이 pre-training 단계에서 학습할 때, 어떠한 단어는 원래 단어로 바뀌어야 하는 건지, 아니면 해당 단어가 그대로 맞는지에 관한 내용도 학습을 할 수 있다.
Next Sentence Prediction
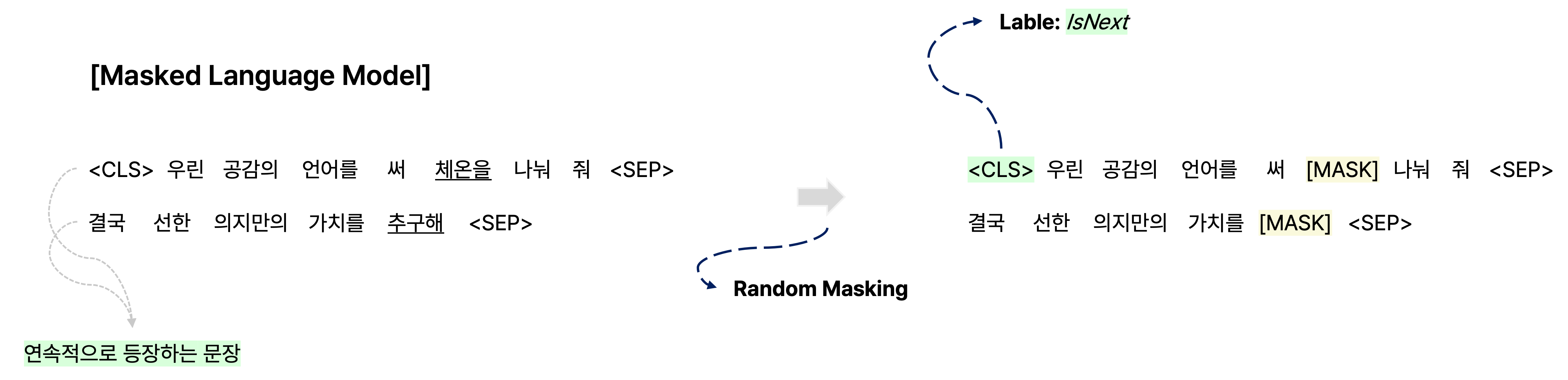
단어를 예측하는 것뿐만이 아니라 같은 document에서 연속으로 등장하는 문장 관계인지를 파악하여 다음에 올 문장이 맞는지에 관해 예측하는 것처럼 문장 level에서의 task에 대응하기 위한 Pre-training 방법인 NSP(Next Sentence Prediction)도 제안되었다.
예를 들어, 주어진 어떠한 텍스트에서 두 개의 문장을 뽑아 연속적으로 이어주고, 각 문장마다 끝나는 지점에 [SEP]를 추가하여 input을 만든다.
정리하면, 앞에서 설명한 단어 level의 task도 학습할 수 있도록 input 문장의 일부 단어를 마스킹하는 Masked Language Model을 통해 해당 단어가 어떠한 단어로 바뀌어야 하는지도 예측할 수 있도록 한다.
또한 문장 level에서 예측 task를 수행하는 역할을 담당하는 classification token인 [CLS]도 input 문장 앞에 추가한다.
예를 들어, 모델이 학습한 [CLS] 인코딩 벡터를 가지고 output layer를 하나 추가하여 두 문장이 연속적으로 등장하는 문장인지에 관한 binary classifcation을 수행하도록 할 수 있다.
BERT의 모델 구조
BERT Base와 Large 비교
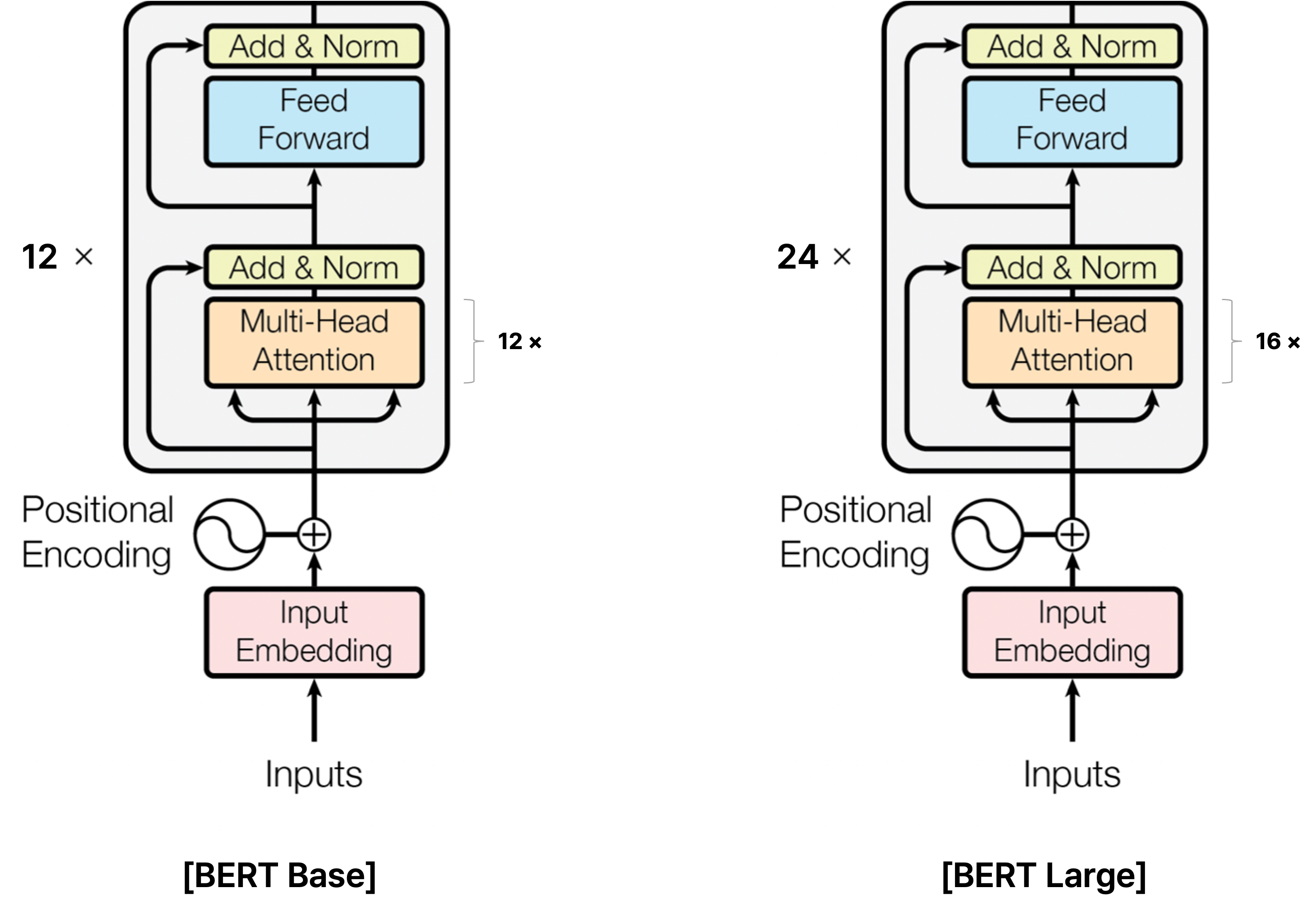
BERT는 transformer에서 사용하는 self-attention 기반의 encoder block을 사용하는데, 여기서 두 가지 버전의 학습된 모델을 제안했다.
BERT Base 모델에서는 self-attention block을 12개를, BERT Large 모델은 24개를 사용했다.
또한 multi-head attention block의 head를 각각 12개, 16개를 사용했고, self-attention block에서 유지하는 인코딩 벡터의 차원 크기를 각각 768, 1024로 설정했다.
BERT의 Embedding
WordPiece Embedding
[출처] https://arxiv.org/pdf/1810.04805.pdf, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
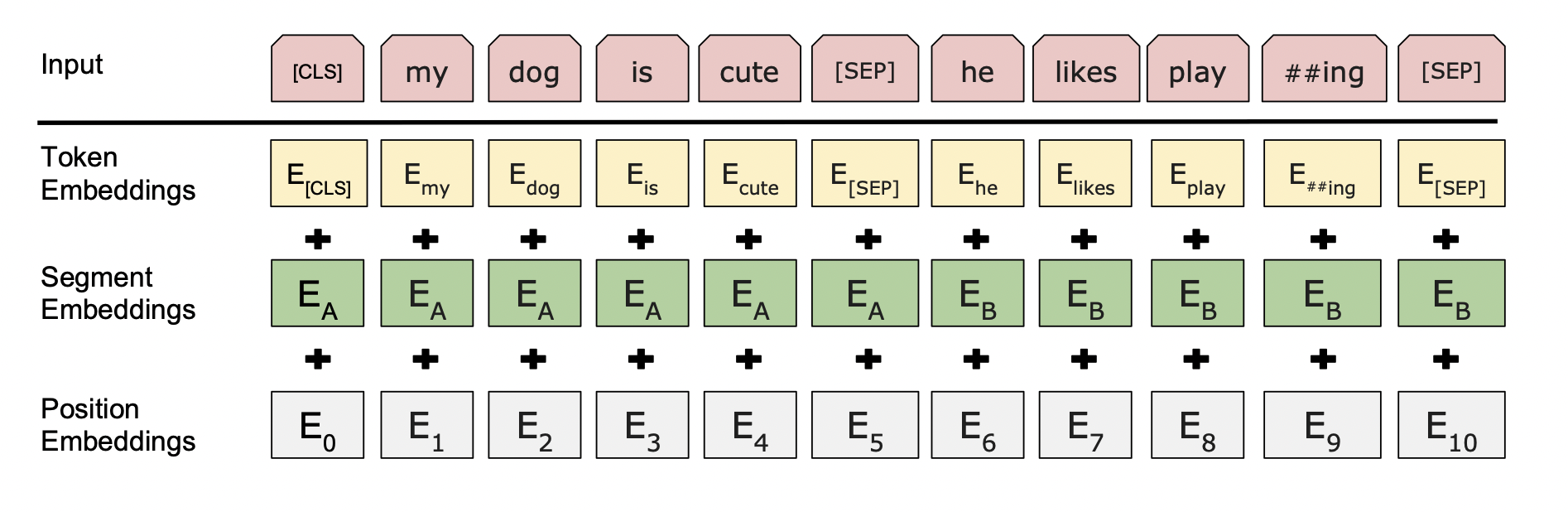
BERT에서는 입력 sequence를 넣을 때 일반적인 transformer처럼 단어별 임베딩 벡터를 넣어주는 것이 아니라 단어를 좀 더 잘게 쪼갠 sub-word로 만들고, 이를 임베딩한 결과의 sequence를 넣는 WordPiece embeddings를 취한다.
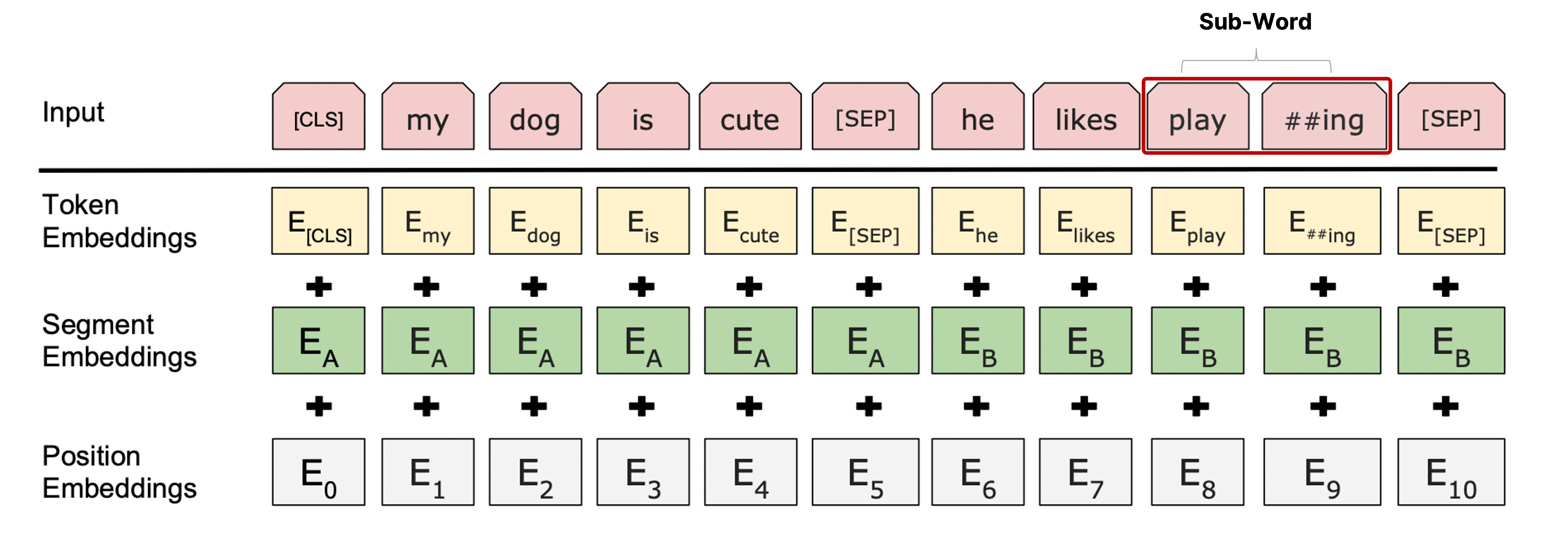
위의 예시에서 'playing'이라는 단어가 한 token으로 들어가지 않고 동사 원형인 'play'와 진행형을 나타내는 '##ing'로 token을 두 개로 나눠서 input으로 넣는 것을 볼 수 있다.
Position Embedding
또한 BERT에서는 일반적인 transformer처럼 sin, cos 등 특정한 방식으로 사전에 정의된 positional embedding을 통해 서로 다른 위치의 각 단어에 관한 임베딩을 사용하는 방법을 택하지 않았다.
Positional embedding matrix조차 마치 Word2Vec에서 embedding matrix를 학습하듯이 random initialization을 통해 전체 학습 과정에서 end-to-end로 학습을 수행하여 각 위치의 단어에 더해줘야 하는 임베딩 벡터를 구한다.
Segment Embedding
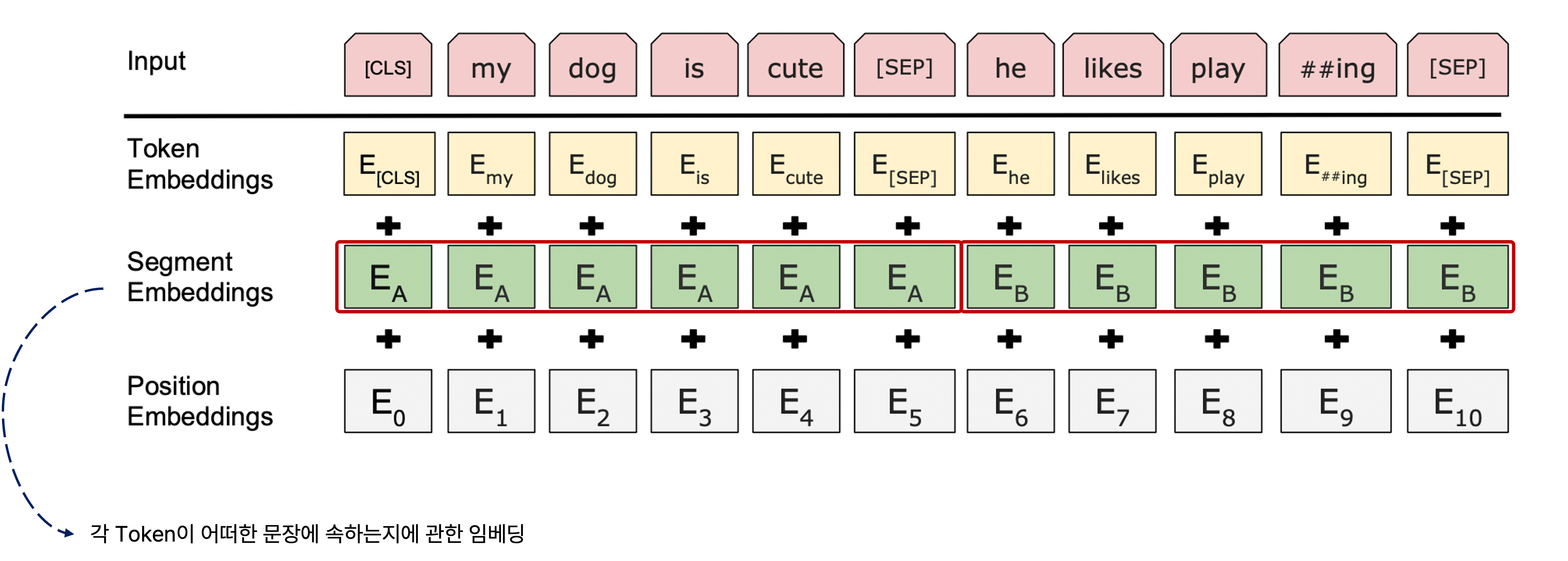
BERT에서는 segment embedding도 사용했는데, 이는 입력 sequence의 각 sub-word에 관한 임베딩 벡터를 구하고 여기에다가 positional embedding도 더하지만, 더 나아가 각 sub-word별로 어떠한 문장에 속하는지에 관한 segment embedding도 더하는 것이다.
이는 각 단어가 각 문장에서 어떠한 위치에 있는지도 중요하지만, 문장 level에서의 task도 같이 학습하는 것을 고려할 때 각 단어가 어떠한 문장에 속하는지에 관한 정보도 같이 학습할 수 있게끔 보완하는 것이다.
이처럼 각 단어가 어떠한 문장에 속하는지를 나타낼 수 있는 정보에 관한 임베딩 벡터도 end-to-end로 학습에 의해 최적화한다.
BERT와 GPT-1의 차이
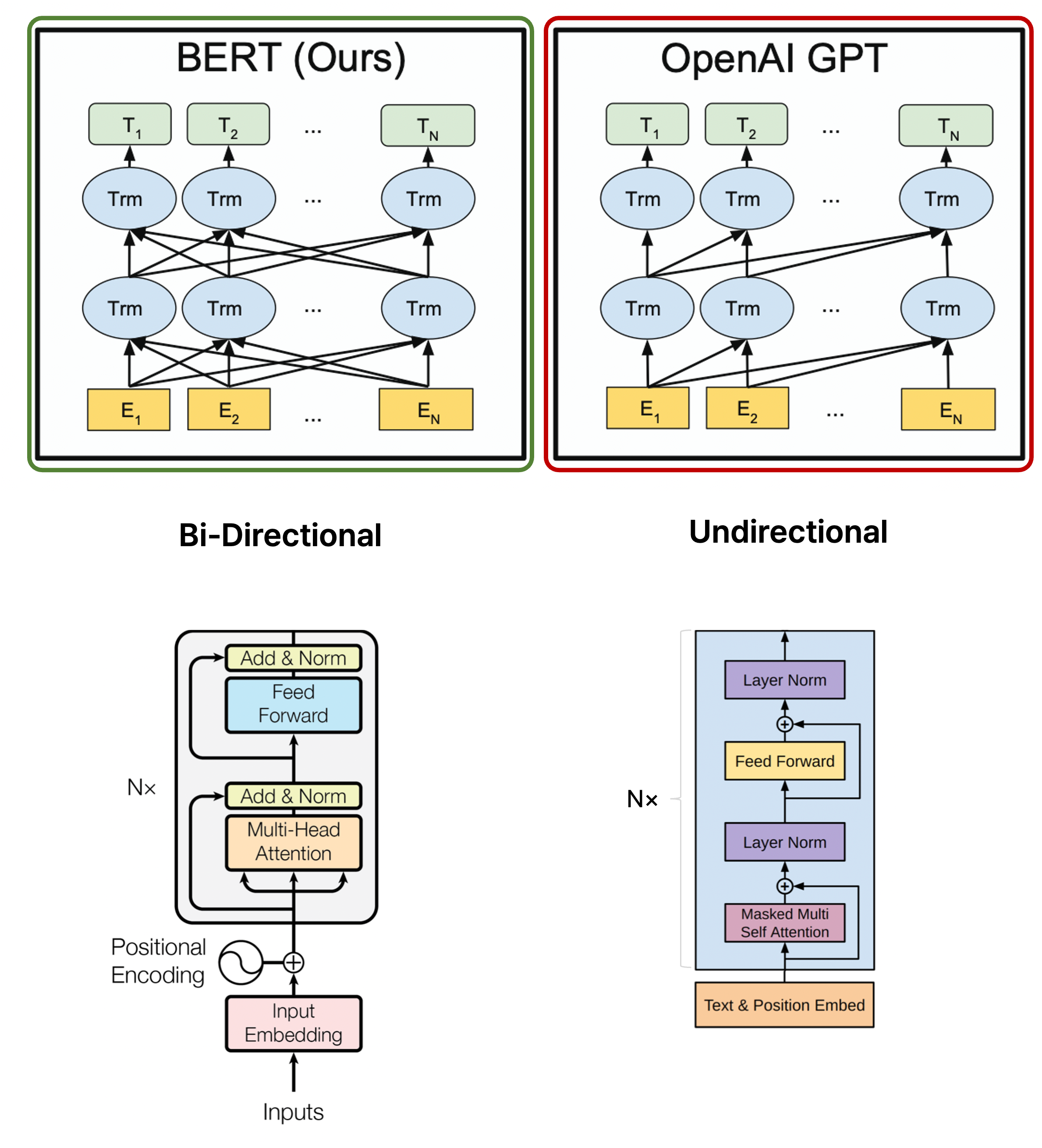
GPT-1은 주어진 sequence를 인코딩하는 pre-training 과정에서 다음 단어를 예측해야 하는 task를 수행하므로 다음에 올 단어를 예측하지 못하도록 해야 한다.
그래서 자기 자신의 왼쪽에 있는 정보만 참고할 수 있도록 하여 학습을 진행하며, 이는 GPT-1의 masked multi self-attention block에서 sequence에 관한 인코딩을 수행한다.
마치 일반적인 transformer의 decoder에서 뒤에 등장하는 query vector의 정보를 인코딩할 수 없도록 하는 masked multi head attention과 유사하다.
그러나 BERT는 양방향의 정보를 가지고 [MASK] 등으로 치환된 단어를 예측하므로 각 단어별로 예측을 수행할 때 입력 sequence로 주어진 모든 단어를 접근할 수 있도록 허용한다.
그래서 GPT-1이 transformer의 decoder block을 사용하는 것과 달리 BERT는 transformer의 encoder block을 사용한다.
학습 데이터의 크기 면에서 비교하면 GPT는 BookCorpus의 8백 만개의 단어를 학습한 반면에 BERT는 BookCorpus와 Wikipedia의 2천 5백만 개의 단어를 학습했다.
GPT-1에서는 <EXTRACT> token을 가지고 분류 문제 등 다양한 task에 맞게 적용할 수 있도록 하는 반면에 BERT는 입력 sequence의 맨 앞에 오는<CLS> token을 사용한다.
또한 여러 문장을 하나의 sequence로 이어서 학습하는 경우, 단순히 <SEP> Token만 사용하는 GPT-1과는 달리 BERT에서는 각 단어가 어떠한 문장에 속하는지를 나타내기 위해 문장의 인덱스를 학습하는 segment embedding을 수행한다.
BERT와 GPT를 pre-training할 때 하이퍼파라미터로서 얼만큼의 단어를 하나의 배치로 학습할지를 결정하는 batch size를 비교하면 BERT는 128,000개 단어, GPT-1은 32,000개의 단어이다.
매 batch마다 BERT가 더 많은 단어를 가져와서 그 단어들에 관한 MLM(Masked Language Model)과 NSP(Next Sentence Prediction)을 수행한다.
Batch size가 일반적으로 크면 클수록 최종 모델 성능이 좋아지고 학습이 안정화되는 경향이 있는데, 이는 gradient descent를 구할 때 batch의 데이터를 고려하므로 더 많은 데이터를 바탕으로 매 batch마다 업데이트하는 게 학습을 더 안정화할 수 있다.
그러나 batch size가 커지면 커질수록 매 batch마다 가져와야 하는 데이터의 양도 많을 뿐만 아니라 forward propagation과 back propagation을 수행할 때 필요한 메모리도 비례하여 증가하므로 고성능의 더 많은 GPU가 필요로 할 수 있다.
GPT는 모든 fine-tuning task에서 $5e-5$의 동일한 learning rate을 사용했지만, BERT는 수행하는 다양한 fine-tuning task에 따라 그에 맞는 learning rate을 사용했다.
BERT의 Pre-Training과 Transfer Learning
앞서 설명한 MLM(Masked Language Model)과 NSP(Next Sentence Prediction)를 pre-training 과정의 task로 수행한 BERT 모델을 가지고 다른 여러 downstream task에 전이 학습(transfer learning)한다.
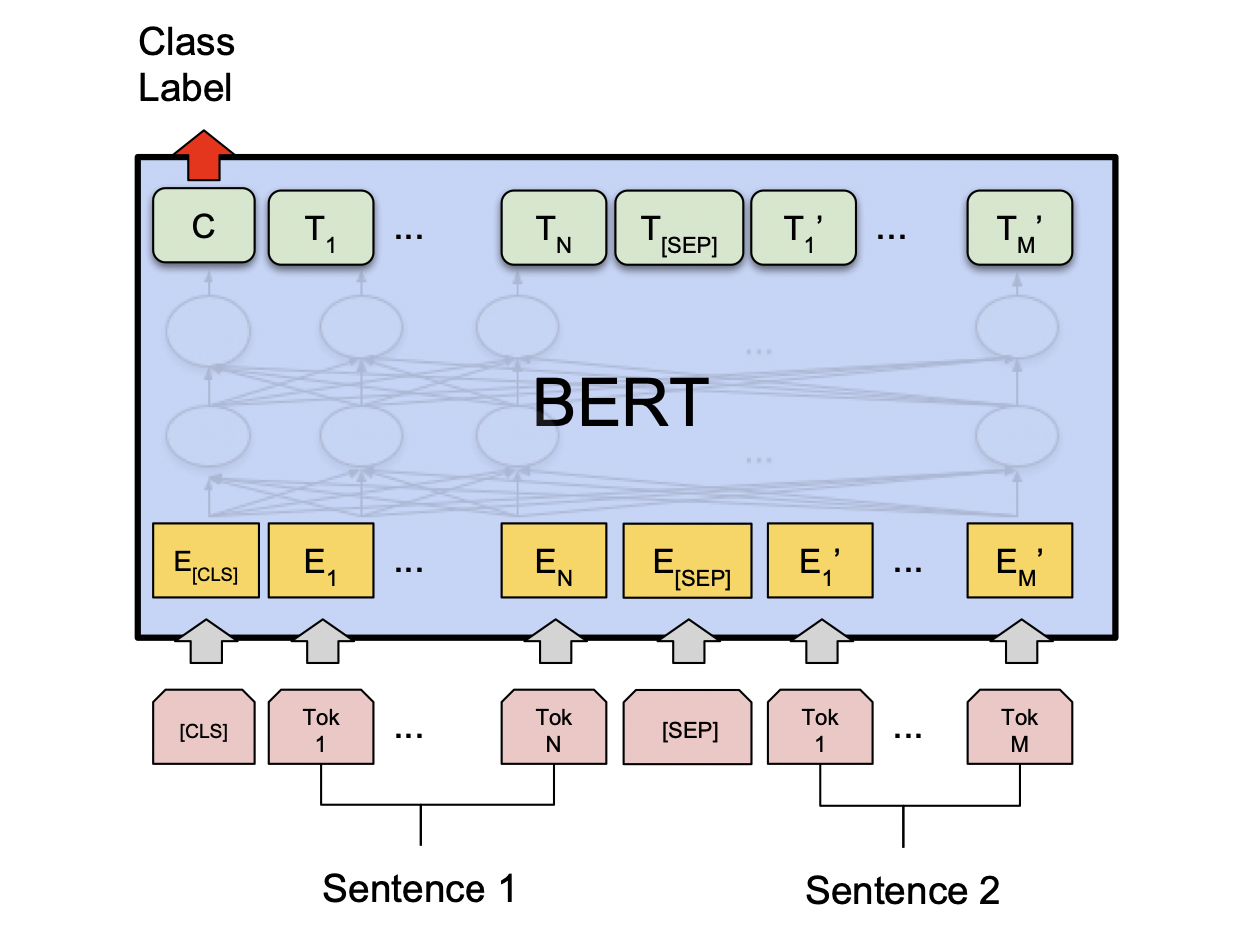
[출처] https://arxiv.org/pdf/1810.04805.pdf, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
논리적으로 모순 관계인지 그렇지 않은지를 구하는 sentence pair classificaion task에서는 두 문장을 <SEP> token으로 구분하여 하나의 sequence로 만들고 맨 앞에 <CLS> token을 추가한 후 각 단어를 임베딩한 벡터를 BERT에 넣어 학습하고, 각 단어별로 인코딩된 output vector에서 <CLS> token의 인코딩된 벡터를 가지고 output layer를 통과하여 해당 문장 간의 관계의 분류를 예측한다.
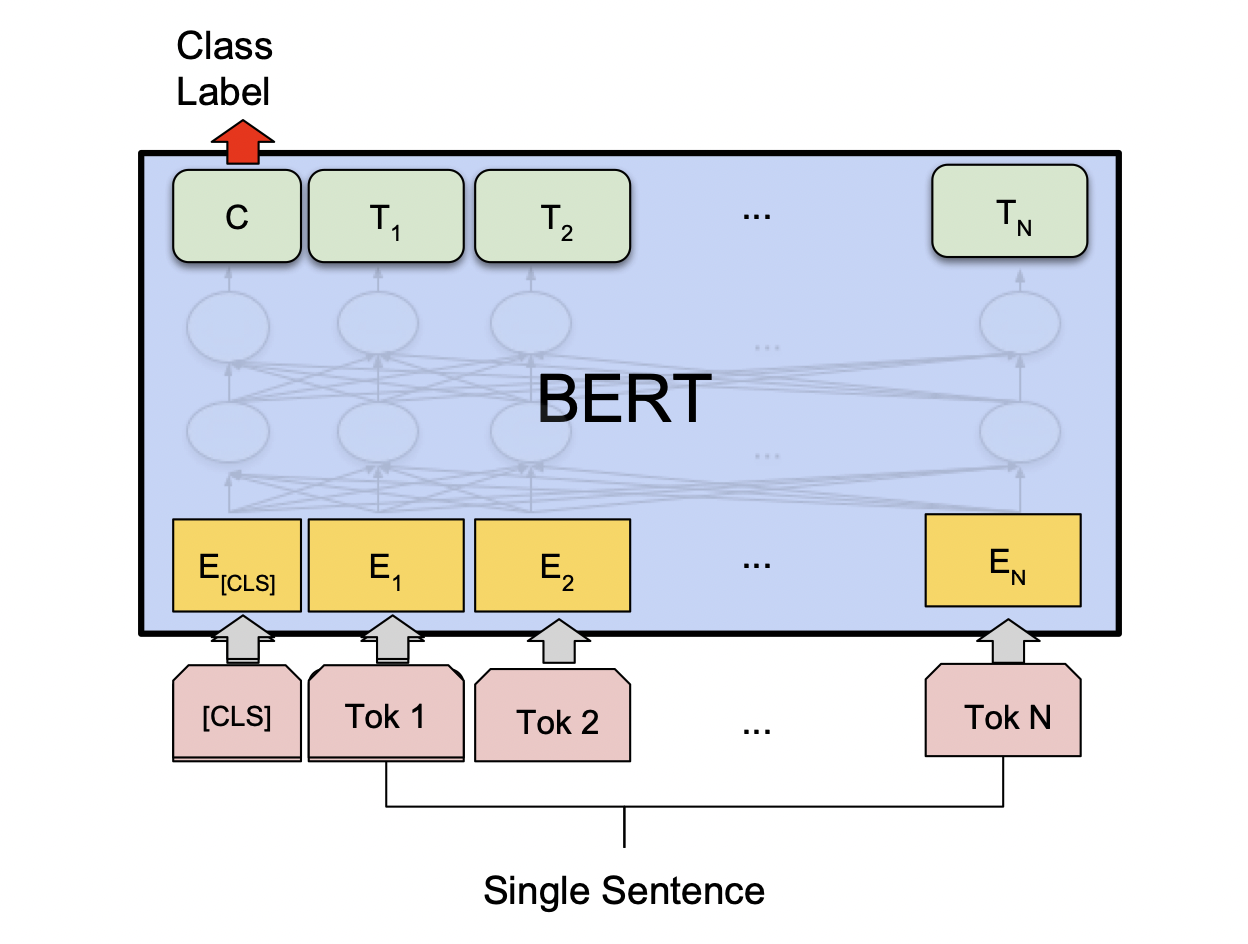
[출처] https://arxiv.org/pdf/1810.04805.pdf, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
단일 문장에 관한 분류를 예측하는 task에서는 <SEP> token을 필요로 하지 않고 단지 입력 문장 앞에 <CLS> token을 추가하는 것이 앞서 설명한 다수 문장에서의 관계를 예측하는 task와의 차이이며, <CLS> token의 인코딩된 벡터를 가지고 output layer를 통과하여 해당 문장 간의 관계의 분류를 예측하는 것은 동일하다.
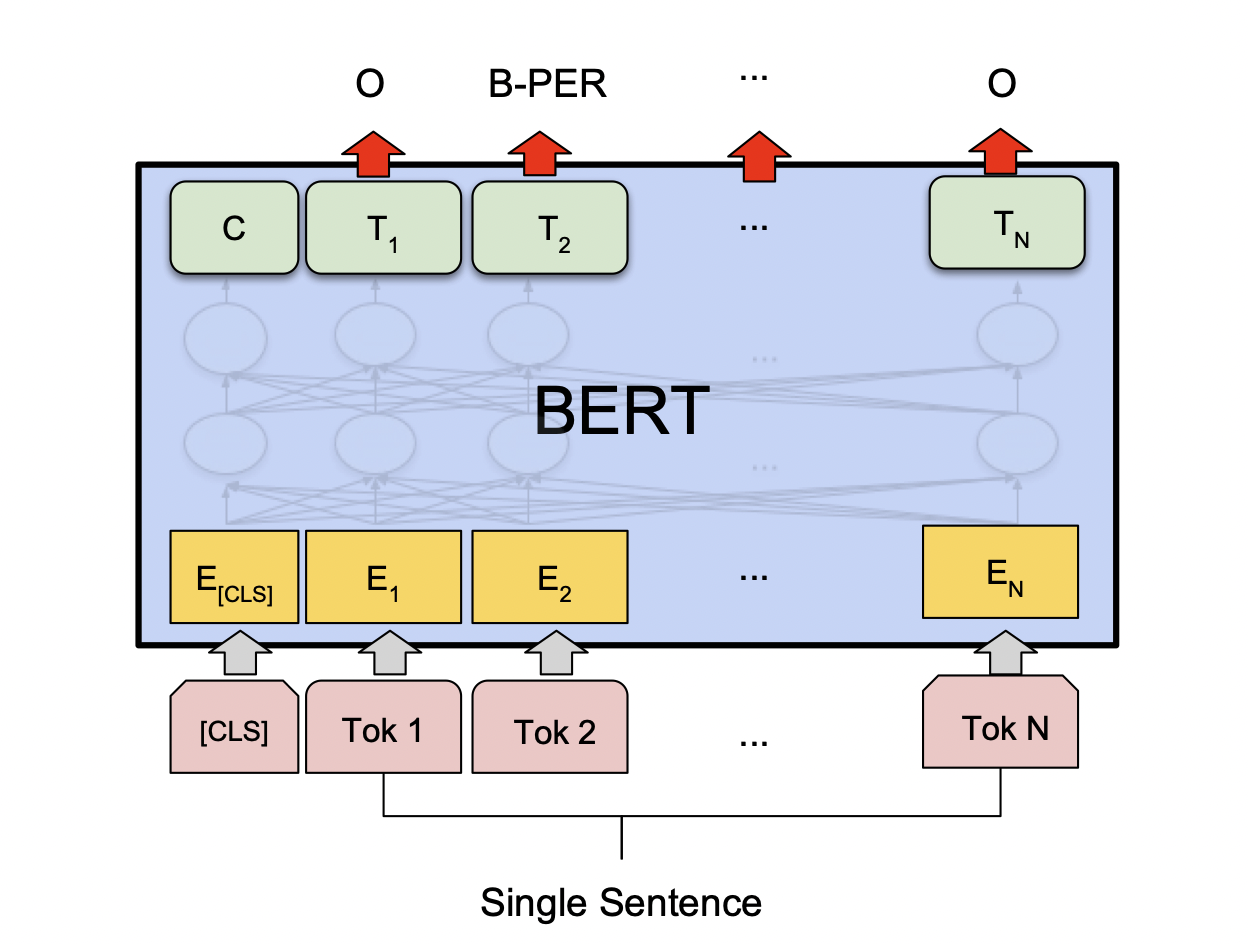
[출처] https://arxiv.org/pdf/1810.04805.pdf, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
각 단어의 품사 등 단어별로 분류 또는 태그를 붙여야 하는 single sentence tagging task에서는 모델에 의해 각각의 단어에 관해 인코딩된 벡터를 모두 공통의 output layer에 통과하여 각 단어별로 어떠한 태그 또는 레이블에 속하는지를 예측한다.
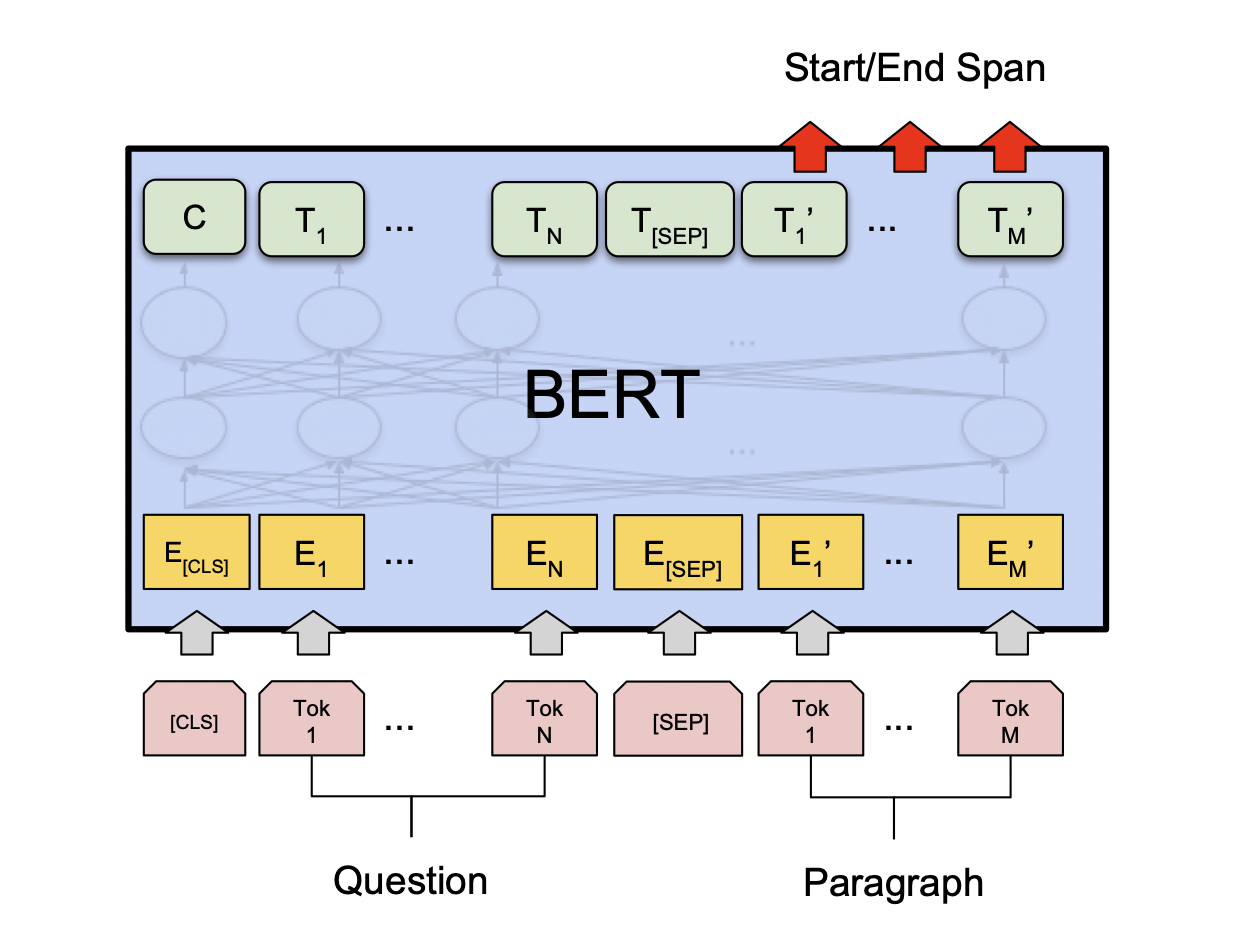
[출처] https://arxiv.org/pdf/1810.04805.pdf, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
질의응답의 한 형태인 MRC(Machine Reading Comprehension)도 fine-tuning하여 수행할 수 있는데, 여기서의 질의응답은 질문 하나만 주어지는 것이 아니라 질문에서 필요로 하는 정보를 갖고 있는 지문이 함께 주어져서 질문에 관한 답을 추출하는 task이다.
실제로 좀 더 어렵지만 유의미한 대표적인 공개 데이터셋인 SQuAD이 있는데, BERT 모델은 해당 데이터셋에서 준수한 성능을 보여주는 것으로 알려져 있다.
The Stanford Question Answering Dataset
What is SQuAD? Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the correspo
rajpurkar.github.io

Pre-training할 때는 질문과 지문을 마치 두 개의 서로 다른 문장인 것처럼 <SEP> token으로 서로 이어서 하나의 sequence를 만들어 BERT를 통해 인코딩을 진행한다.
그러면 BERT의 출력으로 지문에서 단어별로 인코딩된 벡터가 나오고, 이를 통해 정답에 관한 정보를 추출할 수 있는 지문 상에서의 위치를 예측하도록 모델을 학습한다.
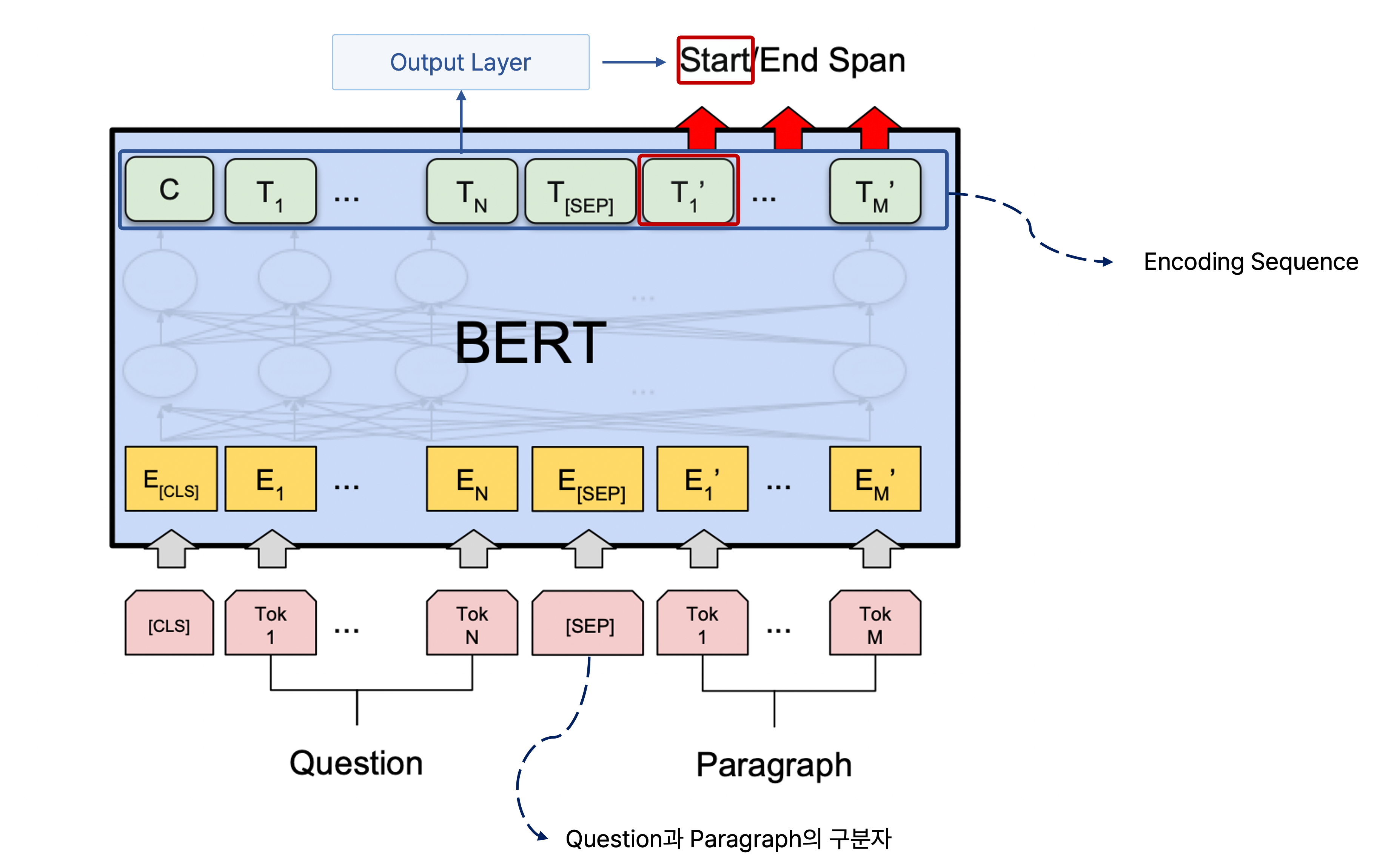
출력으로 나온 각 단어의 인코딩 벡터를 starting position를 예측하는 fully connected layer에 통과하여 하나의 scalar 값을 단어별로 갖도록 하고, 이 모든 단어의 scalar 값에 관하여 softmax를 통과하여 어떠한 단어 위치에서 질문에 관한 답이 나올 확률이 높은지를 예측한다.
이것이 질문에 관한 답을 찾을 수 있는 지문에서의 위치의 첫 번째 단어, 다시 말해서 ground truth에 해당되는 위치에 해당되는 단어의 scalar 값이 거의 1에 가까워지도록 학습을 반복하여 수행한다.
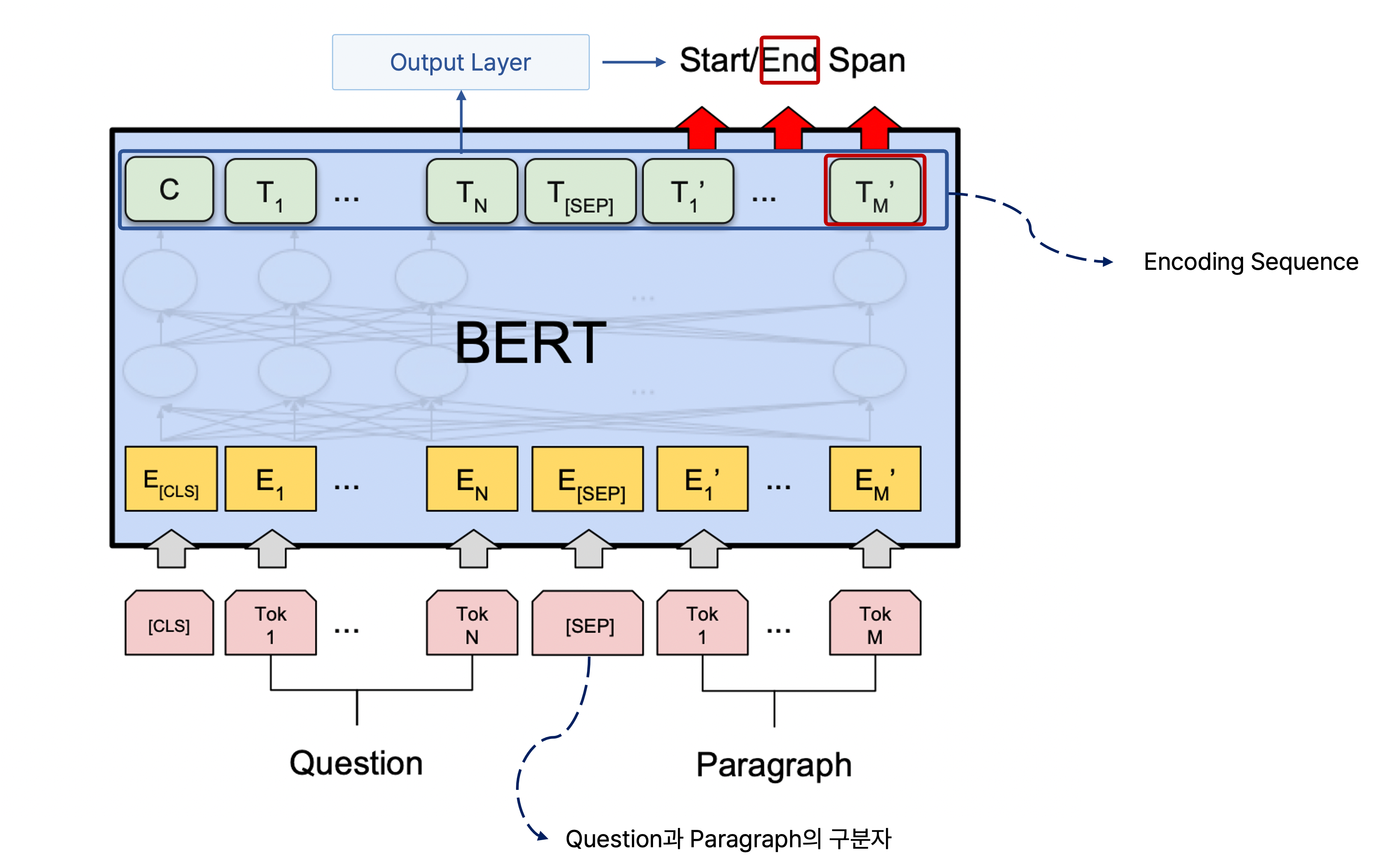
마찬가지로 정답을 찾을 수 있는 부분이 끝나는 위치도 구해야 하는데, 이는 starting position 예측과 마찬가지로 또 다른 fully connected layer를 만들어서 모든 단어의 출력 인코딩 벡터가 scalar 값으로 나오도록 한다.
이후에 softmax를 통과해서 나온 ending position에 관한 예측을 ground truth와 비교하고, 이러한 오차를 줄이는 방향으로 학습을 반복하여 수행한다.

만약 주어진 지문에서 질문에 관한 답을 도출할 수 없는 경우일 때 <No Answer>라는 예측을 해야 할 때도 있는데, 이는 먼저 주어진 지문에서 질문에 관한 답을 구할 수 있는지에 관한 task를 수행하고 이후에 앞서 언급한 지문에서 질문에 관한 답을 찾을 수 있는 위치를 구하는 task를 수행하면 된다.
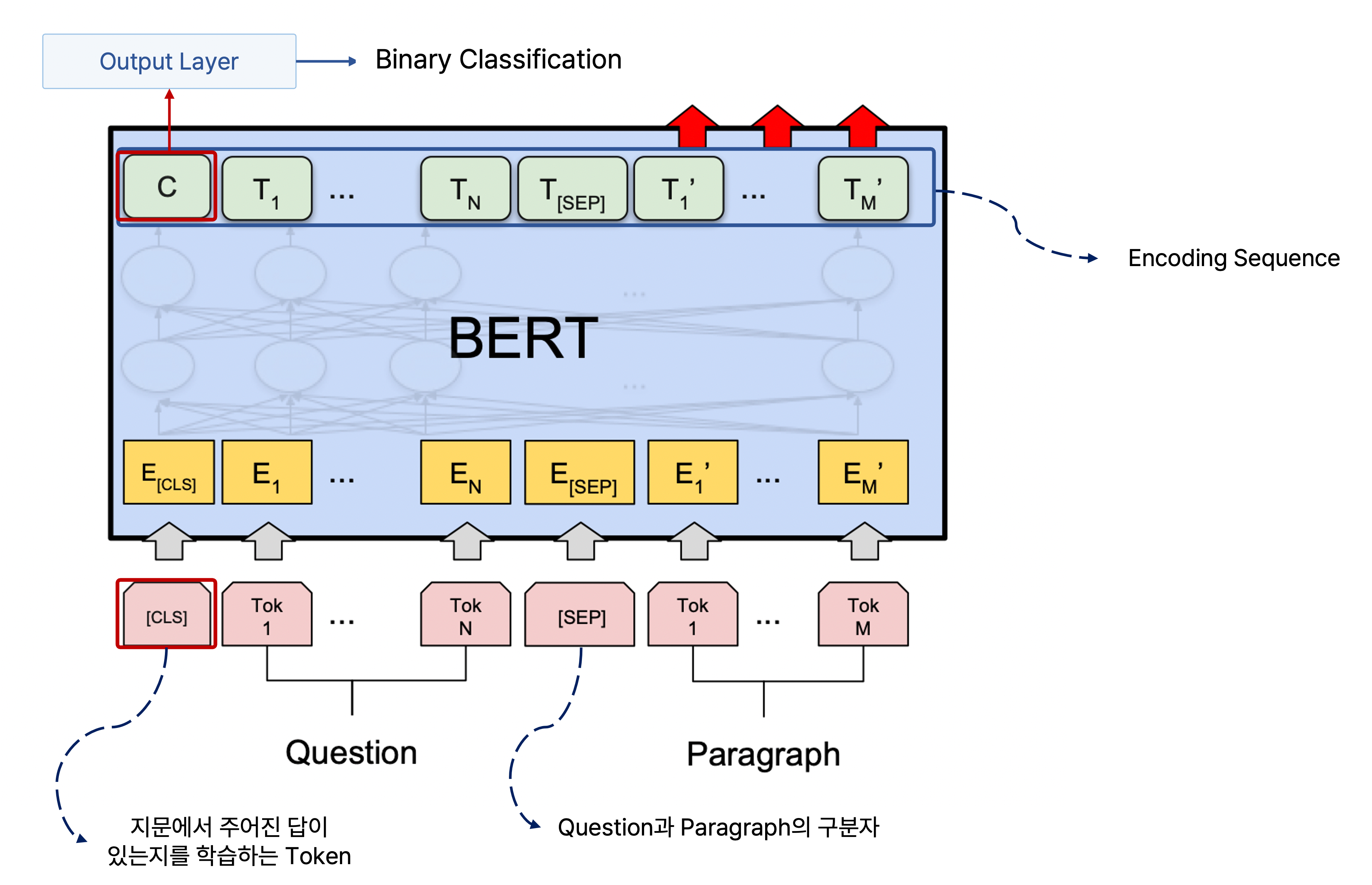
주어진 지문에서 질문에 관한 답을 구할 수 있는지 여부를 판단하는 task는 BERT에서 입력 sequence의 맨 앞에 오는 <CLS> token을 사용하면 되는데, 지문과 질문을 하나로 이은 입력 sequence의 맨 앞에 <CLS> token을 붙여서 이에 관한 인코딩 벡터를 가지고 output layer에 통과하여 cross-entropy loss를 통해서 binary classification을 수행한다.
다음에 올 문장으로서 적절한 문장을 예측하는 task도 BERT를 fine-tuning하여 수행할 수 있는데, 여기서도 <CLS> token을 이용한다.
처음으로 주어지는 문장과 다음으로 올 문장으로 가능한 선지 문장을 모두 하나씩 쌍으로 만드는 방법을 사용할 수 있다.
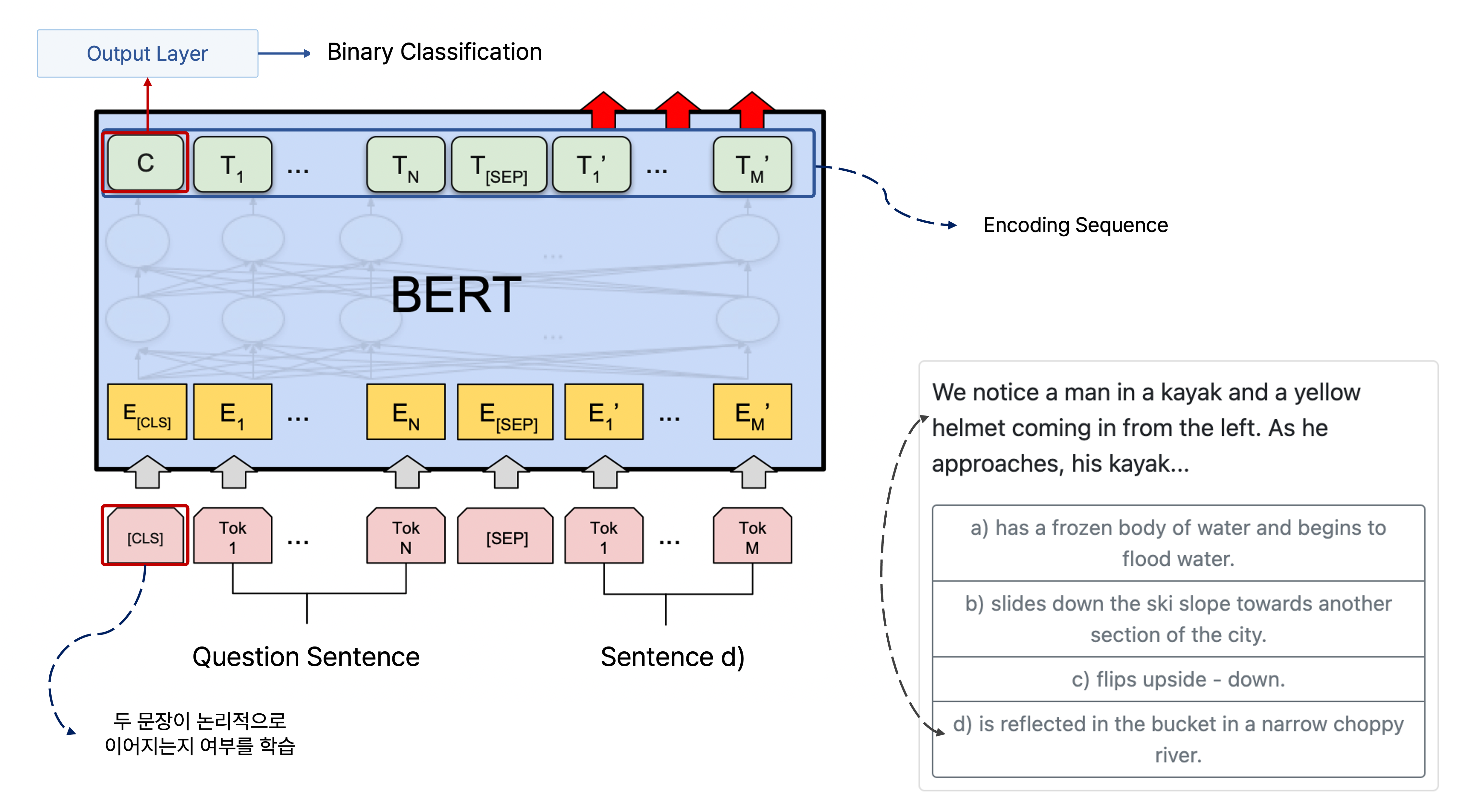
SWAG라는 데이터셋을 예를 들면, 제시 문장과 네 개의 선지 문장 중에서 먼저 제시 문장과 1번 선지 문장을 BERT의 입력 sequence로 만들고, 여기에 <CLS> token을 추가하여 이를 가지고 문장 간의 논리적 관계를 예측하는 task를 수행하는 것이다.
이를 나머지 3개의 문장과도 짝지어서 논리적 관계를 예측을 반복적으로 수행하며, 각 쌍에 의해 만들어진 <CLS> token의 인코딩 벡터를 output layer를 통해 scalar 값으로 만들고 이를 softmax에 통과하여 어떠한 문장 선지가 다음으로 올 확률이 높은지를 구한다.
그리고 예측한 문장 선지가 실제 ground truth가 되도록 loss를 줄이는 방향으로 학습을 반복적으로 수행한다.
BERT의 모델 크기 증가 따른 기대 효과
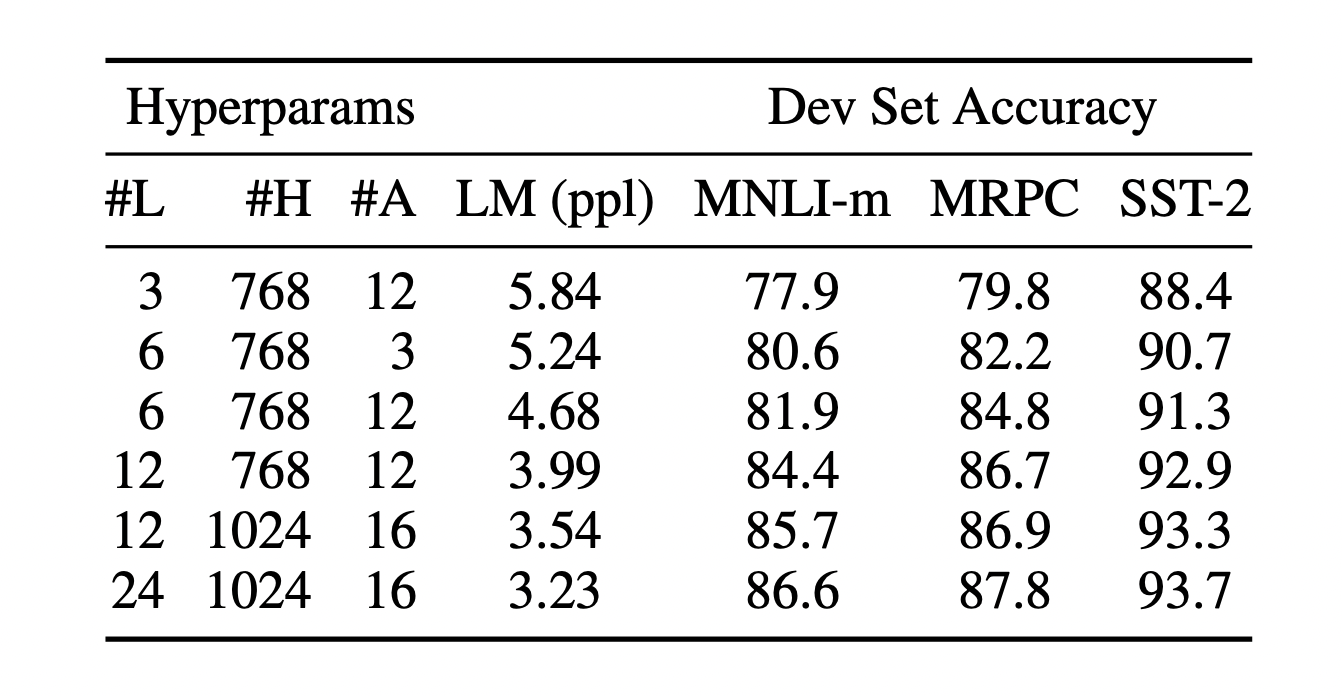
[출처] https://arxiv.org/pdf/1810.04805.pdf, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT의 레이어 수를 추가하고 레이어별 파라미터 수를 증가시켜서 모델의 크기를 늘려 pre-training를 수행하면 다양한 fine-tuning task에 관해 더 좋은 성능을 보인다는 것이 실험적으로 알려져 있다.
또한 성능 향상이 어떤 특정 값으로 수렴하거나 점근되지 않고 모델의 크기가 커지면 커질수록 성능도 점차 높아지는 것으로 예상된다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech NLP Track 주재걸 교수님 기초 강의
'AI > NLP' 카테고리의 다른 글
| BERT를 경량화하여 모델의 크기를 줄인 ALBERT의 특징 (0) | 2022.08.20 |
|---|---|
| Zero-shot Learning이 가능한 GPT-2와 Few-shot Learning의 가능성을 제시한 GPT-3 (0) | 2022.08.16 |
| Beam Search와 NLP 모델의 성능을 평가하는 지표인 BLEU Score (0) | 2022.07.16 |
| LSTM과 GRU의 Gate별 특징과 구조 한번에 이해하기 (0) | 2022.07.06 |
| RNN의 기본 개념과 자연어 처리에서의 RNN 학습 과정 (0) | 2022.07.01 |
Contents
소중한 공감 감사합니다.