AI/NLP
Word Embedding을 위한 Word2Vec와 GloVe
- -
들어가기 전에
인간이 자연어로 대화하는 상황을 생각해보자. 화자는 어떠한 사물, 추상, 관념 등 자연어 형태로 그 대상이 되는 객체를 인코딩(encoding)하고, 이를 '소리'라는 매개체의 메세지로 자연어를 전송하여 청자에게 그 내용을 전달한다. 이후 청자는 그 자연어를 귀로 인식하여 자연어를 뇌에서 떠올릴 수 있는 객체로 디코딩(decoding)한다. 즉, 화자는 청자가 이해할 수 있는 방법으로 정보를 인코딩하고, 청자는 화자가 보낸 데이터를 가지고 디코딩하여 본인의 지식을 통해 이를 해석한다.
이처럼 우리는 정보를 전달하거나 받아들일 때 자연어의 형태로 인코딩 또는 디코딩하지만, 컴퓨터는 자연어를 있는 그대로 인식할 뿐 그 의미를 곧장 해석하지는 못한다. 컴퓨터는 텍스트를 이해할 수 있는 능력이 없고, 컴퓨터에서 정보 처리를 하려면 데이터가 반드시 수학적인 형태로 변형이 되어야 한다. 그래서 대개 컴퓨터는 입력된 자연어를 벡터(vector) 형태로 인코딩하고, 이를 디코딩할 때 다시 자연어 형태로 바꿈으로써 의미를 이해한다. 이 글에서는 컴퓨터가 자연어를 다룰 수 있도록 수학적인 벡터로 어떻게 인코딩하는지 그 방법들을 알아보고자 한다.
자연어의 인코딩
[출처] https://commons.wikimedia.org/wiki/File:Word_vector_illustration.jpg, Singerep
자연어 처리의 여러 task는 일반적으로 '분류(classification)'의 문제로 치환할 수 있다. 주어진 임의의 문장의 의미가 무엇인지를 파악할 때 해당 문장의 의미가 긍정인지, 부정인지를 파악하는 분류 문제로 해석할 수 있고, 문장의 형태소나 구문을 분석할 때도 각 token이 어떠한 문법적인 요소에 속하는지를 분류하는 문제로 고려할 수 있다. 이처럼 대부분의 자연어 처리는 분류의 문제인데, 이를 잘 수행하기 위해서는 자연어를 '벡터(vector)'라는 수학적인 요소로 인코딩할 수 있어야 한다. 좌표 공간 상에서 어떠한 단어의 벡터를 알면 그 단어가 어떠한 의미를 지니고 분류에 속하는지를 확인할 수 있어서다.
[출처] https://commons.wikimedia.org/wiki/File:SVM_explain.png, TseKiChun
즉, 자연어를 '분류'하기 위해서는 그 데이터를 수학적인 벡터로 표현할 수 있어야 하고, 이를 통해 분류 대상인 자연어가 어떠한 특징을 지니는지 파악할 수 있게 된다. 일반적으로 이러한 과정을 feature extraction이라고 하는데, 특징(feature)를 기준으로 분류 대상을 그래프 또는 좌표 공간 위에 표현함으로써 분류 대상들의 경계를 수학적으로 구분할 수 있는 것이다. 구분지을 수 있는 특징이 단순하면 사람이 일일이 구분해도 크게 문제가 되지 않겠지만, 분류 문제가 좀 더 복잡해지고 자연어의 의미가 더 다양해지면 그러한 특징을 사람이 파악하는 건 어려울 수 있다. 그래서 그러한 특징을 컴퓨터가 스스로 찾고, 이를 바탕으로 기존 데이터뿐만이 아니라 새로운 데이터에 관해서도 스스로 분류할 수 있도록 하는 것이 기계학습(machine learning)의 핵심이다. 다시 말해 주어진 자연어 데이터의 feature extraction 뿐만이 아니라 해결하고자 하는 문제에 잘 부합하는 decision boundary를 잘 찾아내는 게 중요하다.
Word Embedding
앞서 우리는 자연어를 컴퓨터가 이해하려면 벡터 형태로 인코딩해야 된다는 것을 알았다. 같은 맥락에서 워드 임베딩(Word Embedding)은 자연어의 단어를 벡터 형태로 치환하여 인코딩하는 걸 말한다. 어떠한 자연어 문장이 단어라는 정보의 기본 단위로 이루어지는 sequence라고 볼 때, 각각의 단어를 특정한 차원으로 이루어진 공간 상의 한 점 또는 그 점의 좌표를 나타내는 벡터로 변환해주는 기법이다. 즉, 각각의 단어를 어떤 특정한 차원의 벡터로 표현하는 방법이다.
텍스트 데이터를 학습 데이터로 주고 이 단어의 좌표 공간의 차원의 수를 사전에 정의해서 word embedding 모델에 학습시키면, 학습이 완료된 이후 좌표 공간 상에서 학습 데이터의 각 단어에 관한 최적의 좌표 값을 구할 수 있게 된다. 여기서 word embedding의 아이디어는 비슷한 의미를 지니는 단어가 좌표 공간 상에 비슷한 위치의 점으로 mapping 되도록 하여 단어 사이의 의미상의 유사도를 잘 반영한 벡터 표현을 지니도록 하는 것이다. 예를 들어, 개를 뜻하는 'dog'와 강아지를 뜻하는 'puppy'는 유사한 의미를 지니는 단어이므로 벡터로 나타냈을 때 좌표 공간에서 가까운 거리에 위치할 수 있지만, 'dog'와 'tree'는 유사한 의미를 지니지 않으므로 먼 거리로 임베딩될 수 있다.
Word2Vec
이전에 Word2Vec의 학습 방식과 이를 추천 시스템에 적용한 Item2Vec에 관해 포스팅한 내용이 있으므로 Word2Vec 응용에 관한 내용은 아래 글을 참고하면 된다.
[Word2Vec과 이를 응용한 Item2Vec]
https://glanceyes.tistory.com/entry/추천-시스템-Word2Vec을-응용한-Item2Vec
Word2Vec을 응용한 Item2Vec
2022년 3월 7일(월)부터 11일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부
glanceyes.com
Word2Vec란?
Word2Vec은 word embedding을 학습시키는 가장 유명한 방법 중 하나이다. 어떠한 단어가 서로 유사한 의미를 지니는지를 학습하기 위해 Word2Vec에서는 같은 문장에서 나타난 인접 단어들 간의 의미가 서로 유사할 것이라는 가정을 전제로 가져간다. 즉, 어떤 한 단어가 주변에 등장하는 단어를 통해 그 의미를 유추할 수 있다는 아이디어에서 출발한 방법이며, 주어진 학습 데이터를 바탕으로 특정 단어의 주변에 나타나는 단어의 등장 확률 분포를 예측하게 된다.
쉬운 예시를 위해 'dog'라는 단어를 예를 들어보자. 'dog' 외에 주어진 여러 단어 $w$에 관해 'dog'라는 단어 근처에 등장할 확률이 무엇인지를 학습하는 것이다. 즉, $P(w|\text{dog})$를 구해서 'dog'라는 단어의 의미를 확률 분포를 통해 파악한다.
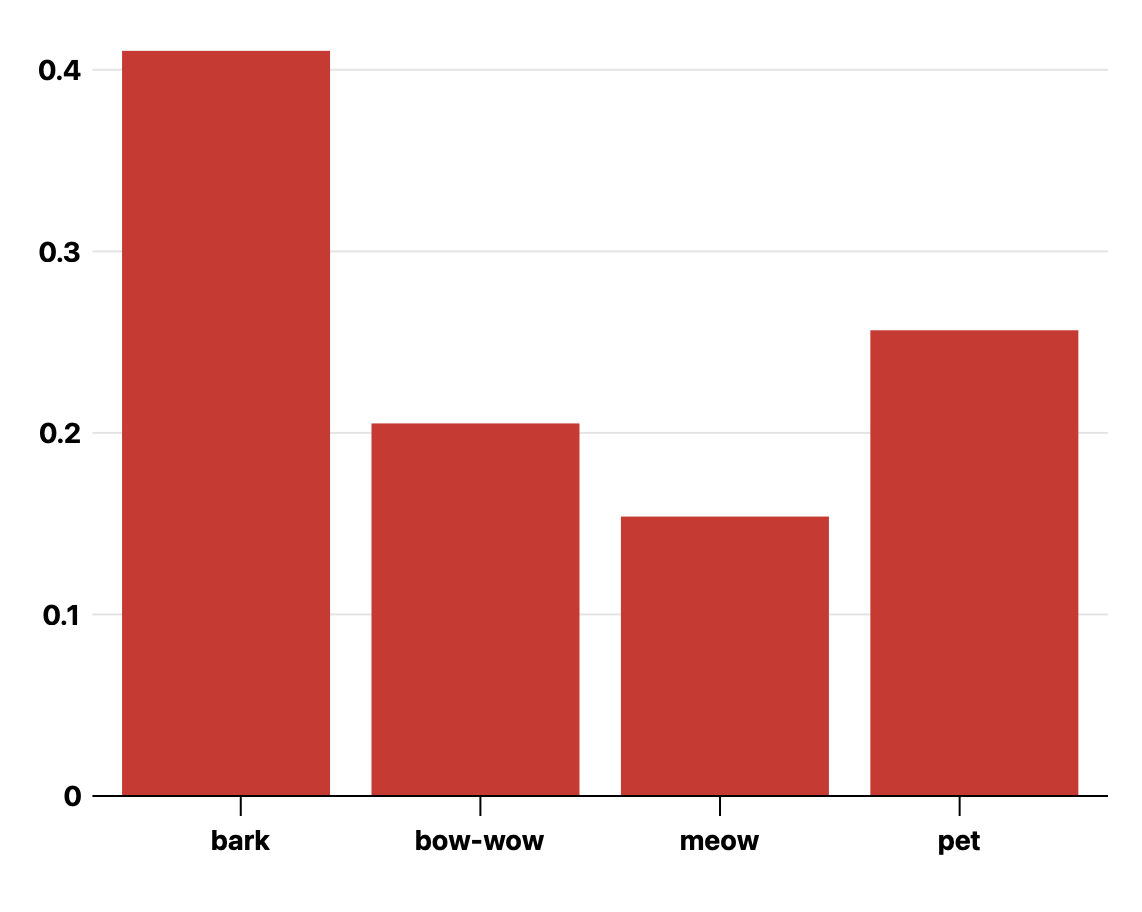
예를 들어, 'bark', 'bow-wow', 'meow', 'pet'이라는 단어 목록이 주어질 때, 각 단어에 관해 dog'라는 단어 근처에 등장할 확률 분포를 구했을 때 위와 같이 나타난다고 하자. 위의 그래프에서는 'pet'이라는 단어의 등장 확률이 가장 높게 나왔는데, 이때 'pet'과 'dog'는 유사한 의미를 지닌 단어로 해석할 수 있다.
Word2Vec의 핵심 아이디어
주변 단어를 통해 중심 단어의 의미를 파악해 보자!
Word2Vec의 학습 과정
[출처] https://commons.wikimedia.org/wiki/File:Rete_neurale_artificiale.png, Mirkipedia
주어진 학습 데이터를 단어로 구분하는 tokenizing 과정을 수행하고, 거기서 unique한 단어만을 모아서 사전(vocabulary)을 구축한다. 이때 사전의 각 단어는 사전의 크기만큼의 차원을 지니는 one-hot vector 형태로 나타낸다. 그냥 모든 단어를 one-hot encoding vector로 나타내면 안되냐는 의문이 들 수 있는데, 이는 굉장히 비효율적인 방법이다. 만약 사전에 단어가 1,000개 존재하면 단어를 인코딩한 벡터는 크기가 1,000이 될 것이다. 일반적으로 단어는 1,000개 보다 매우 많고, 신조어로 인해 단어의 개수는 계속 증가하므로 인사전에 필요한 단어의 개수가 많다면 one-hot encoding을 사용하는 것이 좋지 않을 수 있다. 즉, 단어 벡터가 sparse 해서 단어가 가지는 의미를 벡터 공간에 표현하기 어려워지는 단점을 지니고 있다. 그래서 Word2Vec 모델을 사용하여 단어의 의미를 임베딩 공간에 임베딩함으로써 one-hot encoding vector가 지니는 단점을 보완할 수 있다.

예시로, "The dog barks at everyone."이라는 문장이 주어진다고 가정해보자. 여기서 tokenizing으로 단어를 분리하면 "The", "dog", "barks", "at", "everyone"으로 될 것이다. 이 단어들을 가지고 사전을 만들었을 때, 각 단어를 one-hot vector로 나타내면 위와 같이 벡터에서 하나의 원소만 1이고 나머지는 모두 0인 원소를 갖게 된다. 위의 예시에서는 사전에 포함된 단어가 5개이므로 각 단어에 관한 벡터의 차원은 전체 단어의 개수인 5가 되고, 한 원소만 1이고 나머지 네 개의 원소는 모두 0인 one-hot vector로 표현된다.
Word2Vec에서는 인접한 단어의 의미적인 유사성을 파악하기 위해 슬라이딩 윈도우(sliding window) 기법을 사용하는데, 이는 중심 단어로부터 얼마나 멀리 떨어져 있는 단어까지 유사한 관계로 학습할지를 반영하기 위함이다. 그래서 슬라이딩 윈도우 기법을 적용하여 어떤 한 단어를 중심으로 앞뒤로 나타나는 각각의 단어와 짝을 지어 입출력 쌍을 구성한다.
이때 슬라이딩 윈도우의 크기를 몇으로 설정하는지가 중요하다. 예를 들어 Sliding window의 크기를 5로 설정한다고 가정하면, 중심 단어로부터 양쪽으로 최대 두 단어만큼 떨어져 있는 곳까지 유사한 단어로 고려하여 학습하겠다는 의미가 된다.
다음은 Sliding window 크기를 5로 설정하여 앞서 나온 예시인 "The dog barks at everyone"를 Word2Vec으로 학습하는 과정을 정리한 것이다.

위의 이미지를 살펴보면, 형광색으로 그어진 중심 단어를 기준으로 최대 두 단어만큼 떨어진 단어들을 모두 중심단어와의 순서쌍으로 고려하며, 순서쌍에서 중심 단어는 input이 되고 주변 단어는 output이 된다. 이처럼 주어진 중심 단어를 통해 주변부의 단어를 예측하는 방식의 학습 과정을 skip-gram이라고 한다.
예를 들어, "barks"가 중심 단어일 때 "dog"는 주변 단어가 되며, 이를 순서쌍으로 나타내면 ("barks", "dog")가 된다. 그러면 Word2Vec의 모델에서 "barks"는 input, "dog"는 output이다. 이 예시에서의 학습 과정을 바탕으로 Word2Vec 모델을 그림으로 그리면 다음과 같다.
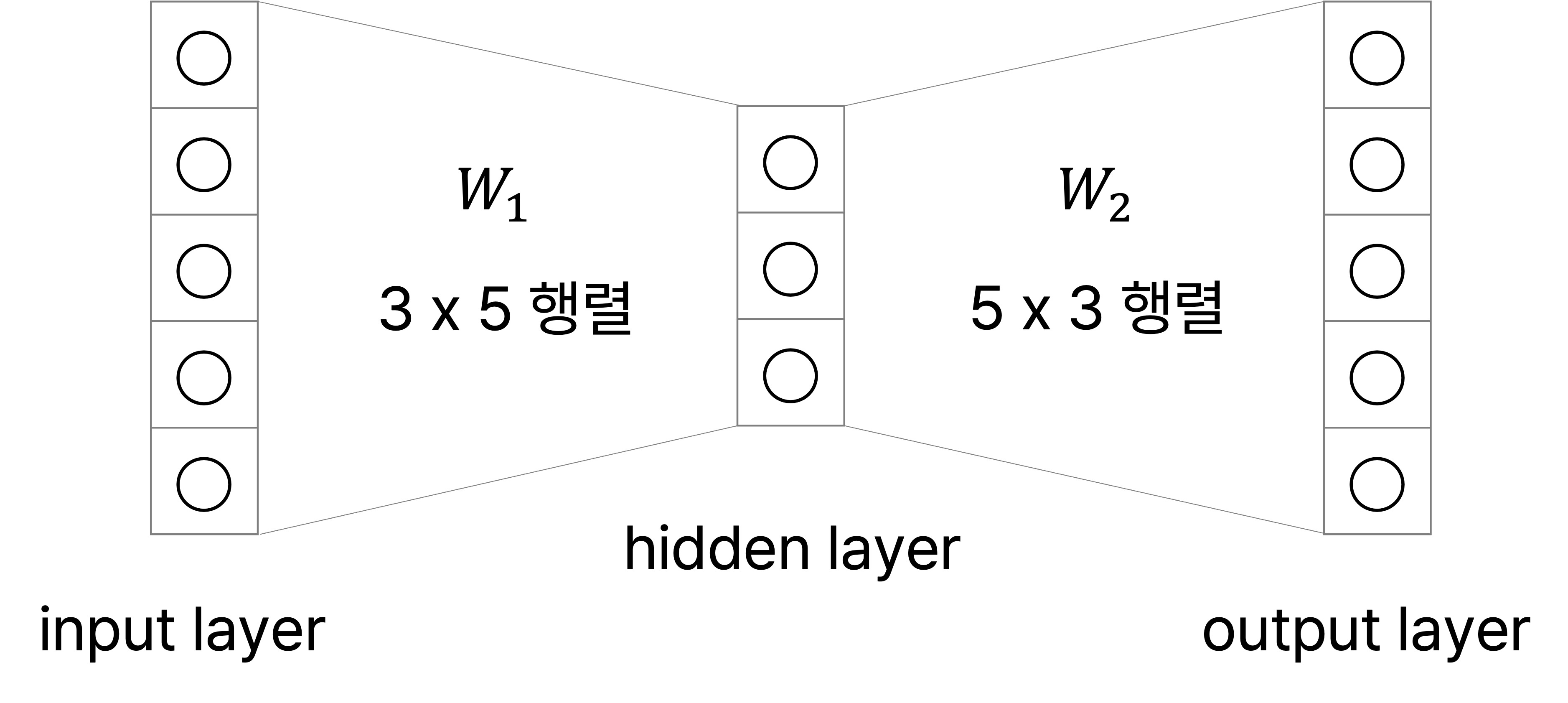
이 예시에서 One-hot vector의 차원 수이자 전체 단어의 개수가 5이므로 input layer와 output layer의 node 개수는 5가 된다. Hidden layer의 node 수는 사용자가 정하는 하이퍼파라미터이며, word embedding을 수행하는 좌표 공간의 차원 수의 동일한 값으로 설정한다. 이번 예시에서는 차원이 3인 임베딩 공간에서 임베딩을 수행한다고 가정하여 hidden layer의 node 수를 3으로 설정했다.
또한 각 layer 사이의 파라미터에 주목할 필요가 있다. 위의 예시에서 Input layer에서 hidden layer로 가는 파라미터를 $W_1$, hidden layer에서 output layer로 가는 파라미터를 $W_2$라고 하자. $W_1$를 행렬로 나타냈을 때의 크기는 (임베딩 차원 수) × (one-hot vector 차원 수)이고, $W_2$는 (one-hot vector 차원 수) × (임베딩 차원 수)이다.
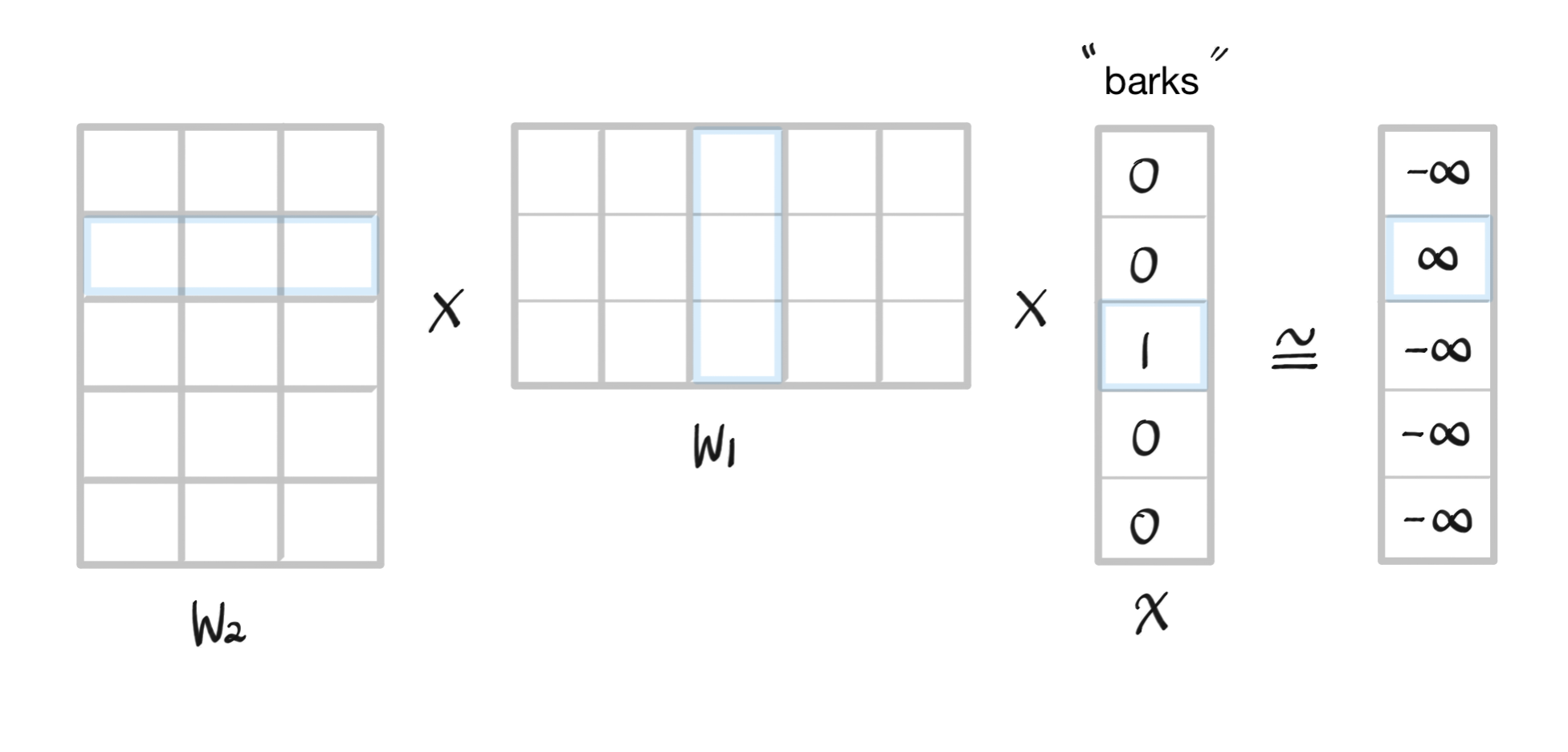
최종적으로 Word2Vec에서는 input $x$에 관해 $W_1$과 $W_2$를 곱한 것에 비선형성을 적용하는 softmax 활성 함수를 취한 결과가 output $y$와 비슷해지도록 학습을 진행한다. 위의 이미지는 "bark" 단어가 input $x$, "dog" 단어가 output $y$일 때의 학습 과정을 정리한 그림이다.
$W_1$과 $x$를 곱하는 과정을 잘 살펴보면 $x$의 세 번째 행만 1이므로 결국 $W_1$에서 세 번째 컬럼의 값만 뽑아 와서 학습하게 되며, 이는 입력 $x$에 대한 3차원의 임베딩 column vector를 구하는 것이며, 결국 one-hot encoding과는 달리 단어에 관한 dense vector를 얻을 수 있게 되는 것이다.
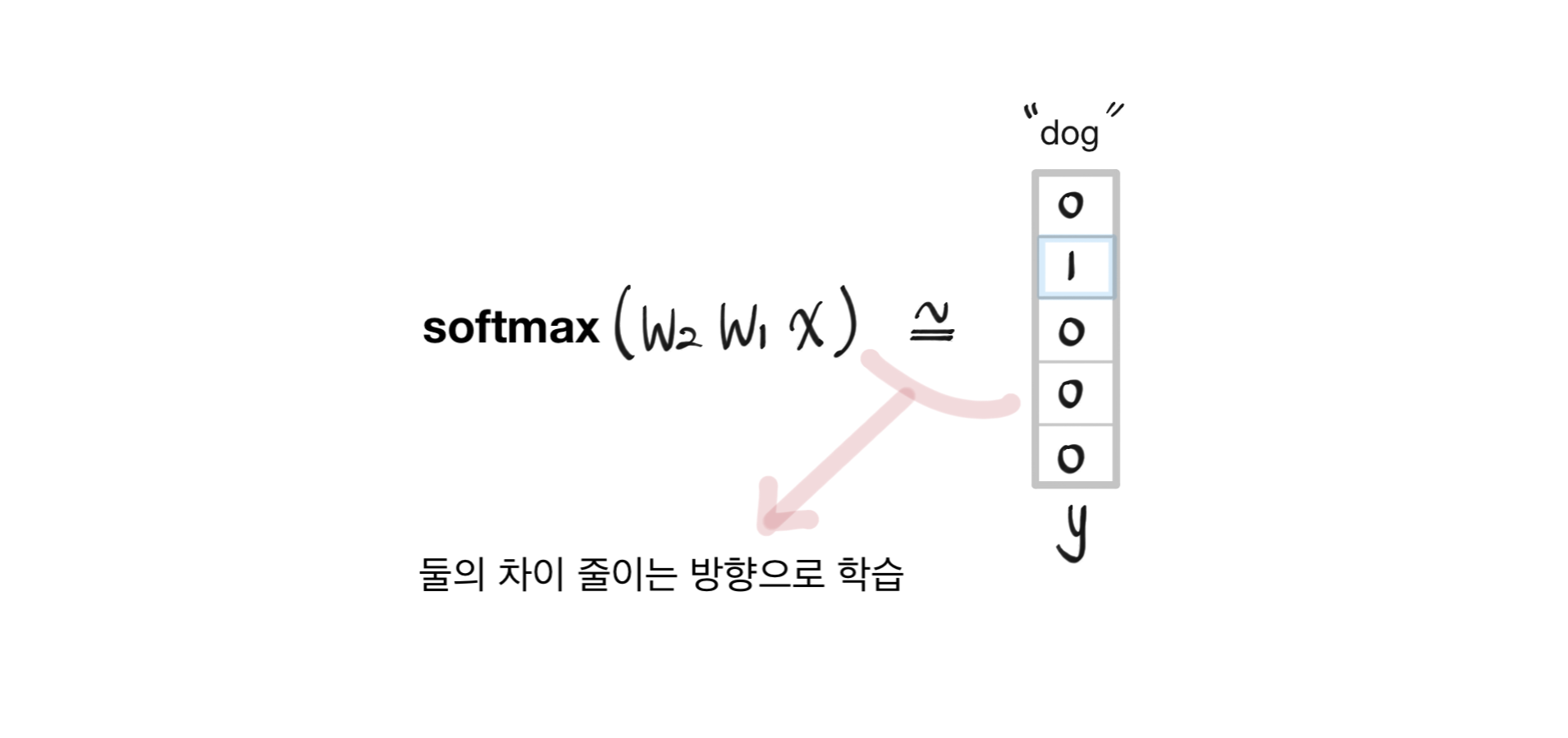
위에서 구한 결과를 $W_2$의 row vector와 곱해서 나온 결과에 softmax를 취해서 나오는 확률 분포가 ground truth인 "dog"의 one-hot vector와 유사해지도록 학습해야 한다. 그래서 $W_2 W_1 x$의 결과에다가 softmax를 취해서 0과 1사이의 확률 값으로 나타내도록 하여 output $y$과 얼마나 차이나는지 loss를 구하고 이를 줄이는 방향으로 학습을 진행한다.
그런데 Word2Vec을 학습한 후, 우리가 원하고자 하는 각 단어에 관한 임베딩 벡터를 무엇으로 사용해야 할지 고민이 될 수 있다. 이는 앞에서 학습한 $W_1$ 또는 $W_2$에서 각 단어에 해당되는 column 또는 row 벡터를 임베딩 벡터로 사용하면 된다. 대체로 $W_1$의 column 벡터를 각 단어의 임베딩 벡터로 사용한다고 알려져 있다.
다음 사이트에서는 실제로 Word2Vec 모델에 데이터를 넣어서 각 단어의 embedding을 벡터를 구하는 과정을 시각적으로 확인해 볼 수 있다.
[Word2Vec 모델의 학습 결과를 시각화한 사이트]
https://ronxin.github.io/wevi/
wevi
Training data (context|target): Presets: Update and Restart Update Learning Rate Next 20 100 500 PCA
ronxin.github.io
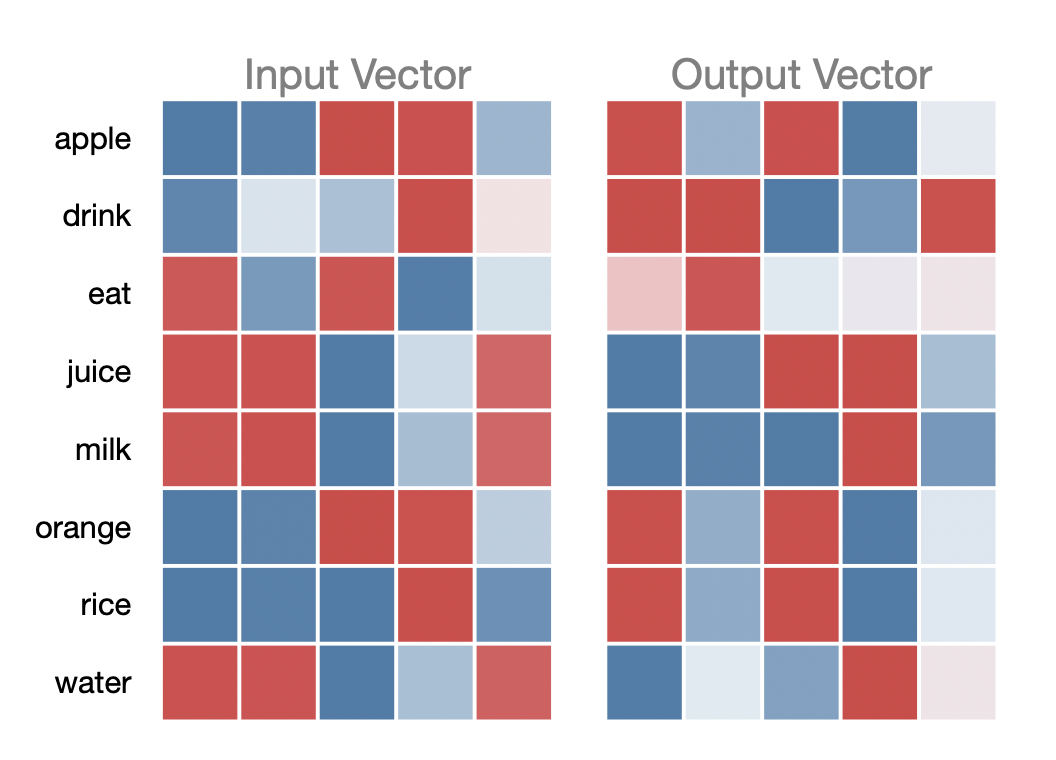
주어진 "apple", "drink", "eat" "juice", "milk", "orange", "rice", "water" 단어 간의 순서쌍을 만들어서 Word2Vec으로 각 단어의 임베딩 벡터를 학습했을 때 나오는 결과를 살펴보면 "juice", "milk", "water"가 매우 유사하고, "apple"과 "orange"가 서로 유사함을 알 수 있다.
Word2Vec 응용 사례
Word2Vec을 사용한 예시에는 아래 설명된 것 외에 Automatic Image Captioning 등 다양한 사례가 있지만, 간단하게 두 가지만 살펴보고자 한다.
Intrusion Detection
여러 단어가 주어졌을 때 그중 나머지 단어와 가장 상이한 의미를 지닌 단어를 찾아내는 작업에서도 Word2Vec을 사용할 수 있다.
Word2Vec로 구한 임베딩 벡터를 가지고 각 단어마다 나머지 단어들과의 euclidean distance를 구하여 평균을 취했을 때, 가장 값이 크게 나온 단어는 나머지 단어들과 크게 연관성이 없는 단어로 판단할 수 있다.
Machine Translation
기계 번역에서 Word2Vec은 서로 다른 언어 간의 같은 의미를 지는 단어들의 임베딩 벡터가 서로 잘 정합(align)될 수 있도록 한다.
Word2Vec의 장단점
Word2Vec은 단어가 가지는 의미 자체를 다차원 임베딩 공간에 벡터화할 수 있으며, 중심 단어의 주변 단어들을 사용해 어떠한 중심 단어가 왔어야 하는지 또는 중심 단어가 주어졌을 때 어떠한 주변 단어가 나오는지를 예측하여 학습을 진행한다. 이처럼 Word2Vec을 사용하면 유클리디안 거리 등 다양한 지표를 통해 단어 간의 유사도를 측정하는 데 용이하고, 단어 간의 관계를 파악하는 데 용이하다. 또한 벡터 연산을 통해 단어의 의미를 추론할 수도 있다.
그러나 단어의 subword information을 무시한다는 단점이 있다. 예를 들어 '고양이'와 '길고양이'는 모두 '고양이'라는 같은 의미를 지녀야 하지만, Word2Vec에서는 각 단어가 쓰인 상황에 따라 서로 다른 의미를 지닌 단어로 해석할 가능성이 있다. 이는 형태학적으로 유사한 '고양이'라는 어근 또는 용언(subword)를 고려하지 않은 채 단어 자체를 학습에 사용해서다. 그리고 사전에 존재하지 않아 학습에 사용되지 않은 단어가 새롭게 주어졌을 때 그의 의미를 추론하지 못하는 out of vocabulary 문제가 발생할 수 있다. 이는 실제 서비스에서 굉장히 치명적인 문제가 된다. 이러한 문제를 해결하고자 등장한 방법이 바로 FastText인데, 이에 관해서는 다른 글에서 자세히 다룰 예정이다.
GloVe
GloVe(Global Vectors for Word Representation)는 Word2Vec처럼 많이 쓰이는 Word embedding 방법 중 하나이다. Word2Vec과는 달리 각 입력과 출력 단어 쌍에 관하여 학습 데이터에서 두 단어가 한 window 내에서 총 몇 번 동시에 등징했는지 그 횟수인 $P_{ij}$를 사전에 계산하고, 입력 단어의 임베딩 $u_i$와 출력 단어 임베딩 $v_j$의 내적이 $P_{ij}$에 $\log$를 취한 값에 가까워지도록 손실함수를 정의하여 사용한다는 것이 특징이다. 이러한 손실함수는 다음과 같은 식으로 정의할 수 있다.
$$ J(\theta) = \frac{1}{2} \sum_{i, j = 1} ^ {W} f(P_{ij})(u_i^Tv_j - \log P_{ij})^2 $$
Word2Vec에서는 특정한 입출력 단어쌍이 자주 등장한 경우 입출력 단어에 관한 임베딩이 여러 번에 걸쳐 학습됨으로써 두 단어의 임베딩 간 내적 값이 커지도록 학습한다. 그러나 GloVe에서는 어떤 단어 쌍이 같은 윈도우에서 동시에 등장한 횟수를 미리 계산하여 이에 $\log$를 취한 값을 두 단어의 임베딩 간 내적 값의 GT(Ground Truth)로 설정하여 학습을 진행하므로 중복되는 계산의 횟수를 줄일 수 있다. 그래서 Word2Vec보다 더 빠른 학습이 가능하고, 보다 적은 데이터에 관해서도 잘 동작한다는 장점이 있다.
추천 시스템 관점에서는 co-occurrence matrix에 low-rank matrix factorization를 적용하는 태스크와 유사하다고 볼 수 있는데, 여기서 co-occurrence matrix란 어떠한 아이템이 등장할 때 다른 아이템이 얼마나 자주 등장하는지를 나타낸 행렬이며 EASE(Embarrassingly Shallow Autoencoders for Sparse Data) 논문을 분석할 때도 등장한 개념이다. 이에 관한 내용은 아래의 글을 참고해 보면 좋다.
[EASE 모델 논문 리뷰에서의 co-occurrence matrix]
Embarrassingly Shallow Autoencoders for Sparse Data 모델이 희소 데이터에 강한 이유
Embarrassingly Shallow Autoencoders for Sparse Data 모델은 왜 희소한 데이터에서 괜찮은 성능을 보일까? 한 달이라는 긴 시간동안 네이버 부스트캠프 AI Tech 3기에서 진행했던 Movielens 데이터 기반의 영화..
glanceyes.tistory.com
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech NLP Track 주재걸 교수님 기초 강의
2. 네이버 커넥트재단 부스트캠프 AI Tech RecSys Track 이영수 마스터님 DKT 대회 강의
3. 네이버 커넥트재단 부스트캠프 AI Tech 3기 NLP Track 김성현 마스터님 KLUE 강의
'AI > NLP' 카테고리의 다른 글
| BERT를 경량화하여 모델의 크기를 줄인 ALBERT의 특징 (0) | 2022.08.20 |
|---|---|
| Zero-shot Learning이 가능한 GPT-2와 Few-shot Learning의 가능성을 제시한 GPT-3 (0) | 2022.08.16 |
| Self-supervised Model인 GPT-1과 BERT 분석 및 비교 (0) | 2022.08.01 |
| Beam Search와 NLP 모델의 성능을 평가하는 지표인 BLEU Score (0) | 2022.07.16 |
| LSTM과 GRU의 Gate별 특징과 구조 한번에 이해하기 (0) | 2022.07.06 |
Contents
소중한 공감 감사합니다.